本文主要是介绍Hive实战:统计总分与平均分,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 一、实战概述
- 二、提出任务
- 三、完成任务
- (一)准备数据文件
- 1、在虚拟机上创建文本文件
- 2、将文本文件上传到HDFS指定目录
- (二)实现步骤
- 1、启动Hive Metastore服务
- 2、启动Hive客户端
- 3、创建Hive表,加载HDFS数据文件
- 4、利用Hive SQL统计总分与平均分
一、实战概述
-
本次实战主要聚焦于使用Hive框架对成绩数据进行处理和分析。任务目标是基于一个包含六个字段(姓名、语文、数学、英语、物理、化学)的成绩表,计算每个学生的总分和平均分。
-
首先,我们在虚拟机上创建了一个名为
score.txt的文本文件,其中包含了五名学生的成绩记录。然后,我们将该文件上传到HDFS的指定目录/hivescore/input中。 -
接下来,我们启动了Hive Metastore服务,并通过执行命令行启动了Hive客户端。在客户端中,我们创建了一个名为
t_score的内部Hive表,该表的结构与成绩表的字段相匹配。我们使用load data命令将HDFS中的成绩数据加载到t_score表中。 -
最后,我们编写了一条Hive SQL语句,用于计算每个学生的总分和平均分。该语句根据学生的姓名进行分组,并对每个学生的所有科目成绩进行求和和求平均值。结果集包含了每个学生的姓名、总分和平均分。
-
通过这次实战,我们展示了如何利用Hive框架处理和分析大规模数据,以及如何通过简单的SQL语句实现复杂的数据统计和计算任务。这一过程不仅体现了Hive在大数据处理中的高效性和便利性,也为我们提供了宝贵的实践经验,为进一步的数据分析工作奠定了基础。
二、提出任务
- 成绩表,包含六个字段(姓名、语文、数学、英语、物理、化学),有五条记录
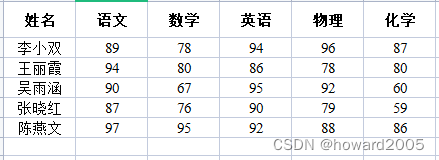
- 利用Hive框架,计算每个同学的总分与平均分
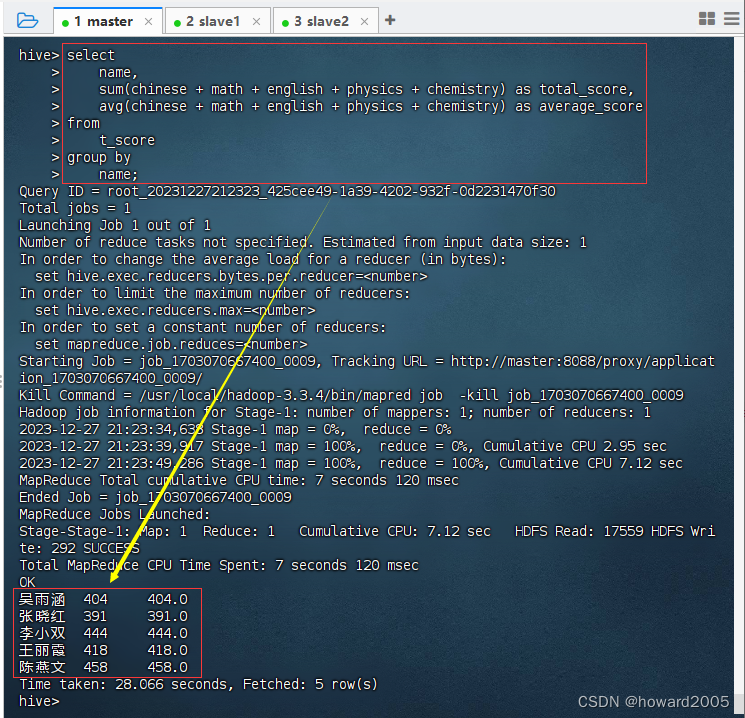
吴雨涵 404 404.0
张晓红 391 391.0
李小双 444 444.0
王丽霞 418 418.0
陈燕文 458 458.0
三、完成任务
(一)准备数据文件
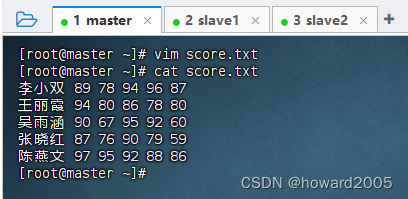
1、在虚拟机上创建文本文件
- 在master虚拟机上创建
score.txt文件
2、将文本文件上传到HDFS指定目录
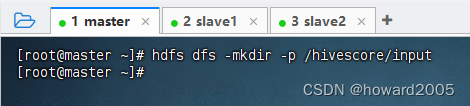
-
在HDFS上创建
/hivescore/input目录
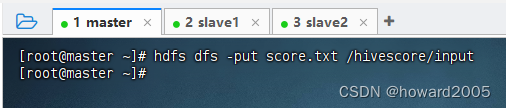
-
将
score.txt文件上传到HDFS的/hivescore/input目录
(二)实现步骤
1、启动Hive Metastore服务
- 执行命令:
hive --service metastore &,在后台启动metastore服务

2、启动Hive客户端
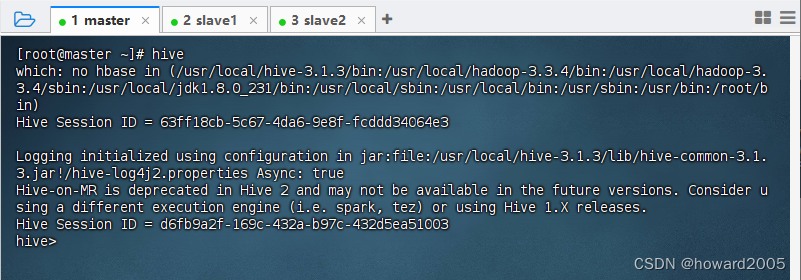
- 执行命令:
hive,看到命令提示符hive>
3、创建Hive表,加载HDFS数据文件
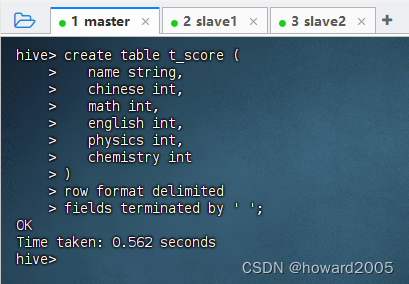
- 创建内部表
t_score,执行命令:create table t_score ( name string, chinese int, math int, english int, physics int, chemistry int ) row format delimited fields terminated by ' ';
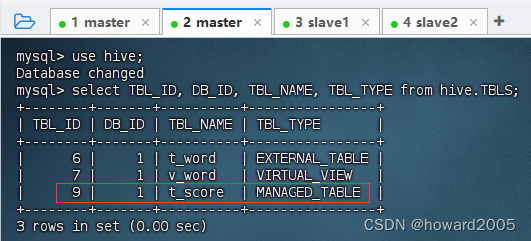
- 在MySQL的
hive数据库的TBLS表里可以查看内部表t_score对应的记录
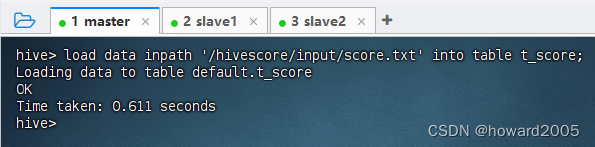
- 加载成绩数据文件到内部表
t_score,执行命令:load data inpath '/hivescore/input/score.txt' into table t_score;
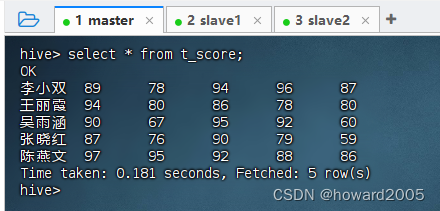
- 查看成绩表全部记录,执行语句:
select * from t_score;
4、利用Hive SQL统计总分与平均分
- 编写Hive SQL语句,进行词频统计
- 执行命令:
select name, sum(chinese + math + english + physics + chemistry) as total_score, avg(chinese + math + english + physics + chemistry) as average_score from t_score group by name;
- 这个SQL语句的功能是在一个名为
t_score的表中,根据学生的姓名(name)进行分组,并对每个学生各科成绩进行统计计算。
SELECT name: 选择t_score表中的name列,表示我们要按照姓名来显示结果。SUM(chinese + math + english + physics + chemistry) AS total_score: 对每个学生的语文、数学、英语、物理和化学成绩进行求和,并将这一结果命名为total_score。这将计算出每个学生的总分。AVG(chinese + math + english + physics + chemistry) AS average_score: 对每个学生的语文、数学、英语、物理和化学成绩进行求平均值,并将这一结果命名为average_score。这将计算出每个学生的平均分。FROM t_score: 指定数据来源是名为t_score的表。GROUP BY name: 根据name列进行分组,这意味着对于表中的每一条具有不同姓名的记录,都会分别进行总分和平均分的计算。
- 因此,这个SQL语句的最终功能是输出一个结果集,其中包含每个学生的姓名、他们的总分以及平均分。
这篇关于Hive实战:统计总分与平均分的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







