本文主要是介绍python爬虫实例—猫眼TOP100榜,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1. 实验内容
2. 脚本代码
3.实验结果
4.参考资料
1. 实验内容
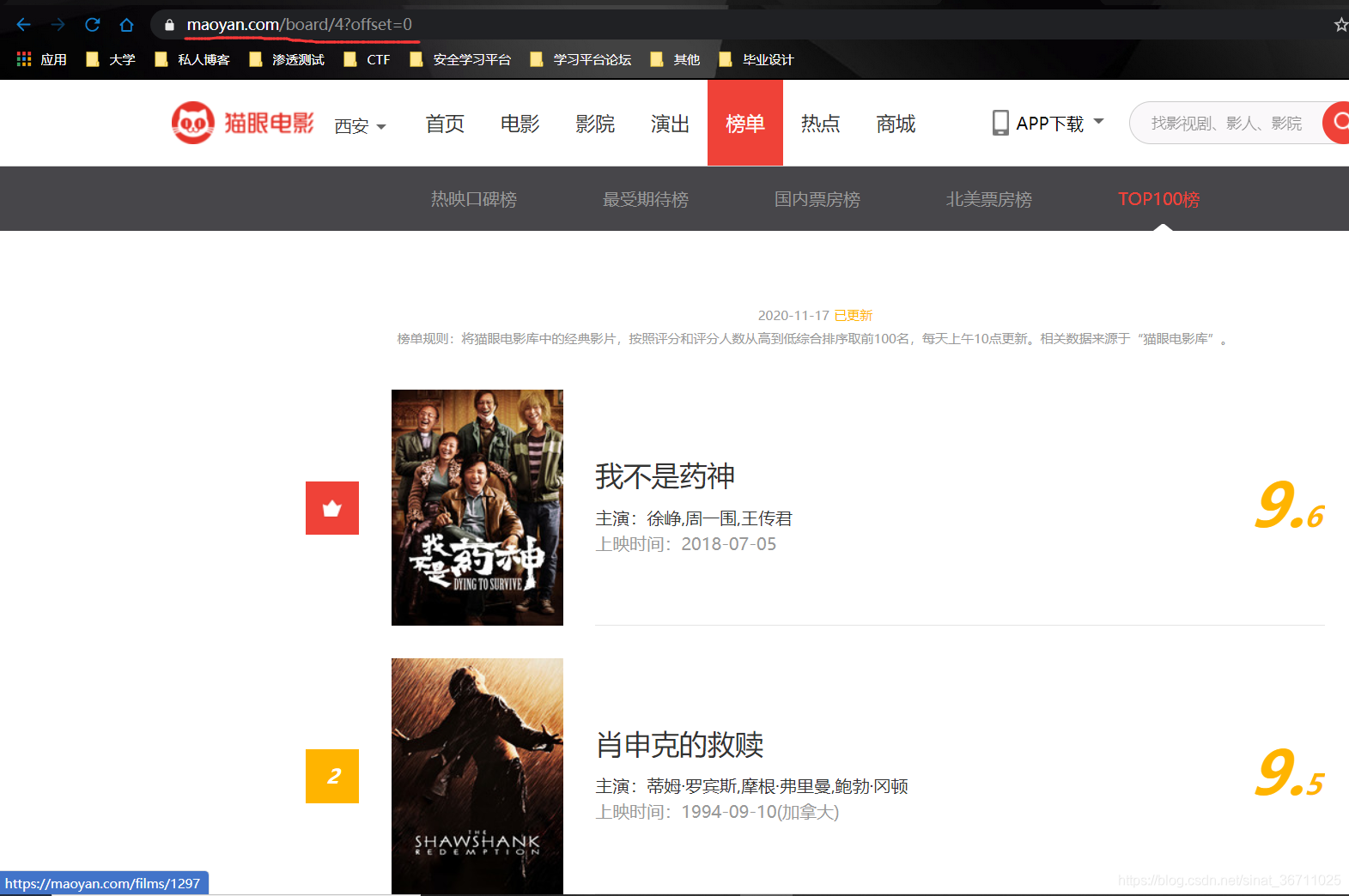
Requests+正则表达式抓取猫眼电影TOP100榜单
URL:https://maoyan.com/board/4
一页有10个推荐电影,https://maoyan.com/board/4?offset=10(第二页)
使用技术:
1.匿名代理
2.python的requests请求包
3.re,正则表达式
4.结果保存json格式
5.使用无线程、多线程、线程池执行爬取任务
2. 脚本代码
# -*- coding: utf-8 -*-
# @Time : 2020/11/17 10:29
# @Author : jpgong
# @FileName: maoyan_spider.py
# @Blog :'''Requests+正则表达式抓取猫眼电影TOP100榜单URL:https://maoyan.com/board/4一页有10个推荐电影,https://maoyan.com/board/4?offset=10(第二页)使用技术:1.匿名代理2.python的requests请求包3.re,正则表达式4.结果保存json格式5.使用无线程、多线程、线程池执行爬取任务
'''
import codecs
import datetime
import json
import time
import requests
from requests.exceptions import RequestException
import re
from requests.packages.urllib3.exceptions import InsecureRequestWarning
from colorama import Foredef get_one_page(url):'''爬取页面内容:param url::return: HTML文本内容'''try:headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.162 Safari/537.36'}proxy = '127.0.0.1:7890'proxies = {'http': 'http://' + proxy,'https': 'https://' + proxy}'''r.text 返回headers中的编码解析的结果,可以通过r.encoding = 'gbk'来变更解码方式r.content返回二进制结果r.json()返回JSON格式,可能抛出异常r.status_code'''# 禁用安全请求警告requests.packages.urllib3.disable_warnings(InsecureRequestWarning)response = requests.get(url, proxies=proxies, headers=headers, verify=False)# print(response.text)if response.status_code == 200:return response.textreturn Noneexcept RequestException:return Nonedef parse_one_page(html):'''解析response响应内容通过正则表达式对html解析获取电影名称、时间、评分、图片等信息。:param html::return:'''pattern = re.compile('<dd>' # (.*)代表匹配除换行符之外的所有字符;(.*?)代表非贪婪模式,也就是说只匹配符合条件的最少字符+ '.*?<i class="board-index.*?">(\d+)</i>' # 获取电影的排名<i class="board-index board-index-1">1</i>+ '.*?<img data-src="(.*?)" alt="(.*?)"' # 获取图片网址和图片名称<img data-src="xxxxx" alt="我和我的祖国"+ '.*?<p class="star">(.*?)</p>' # 获取电影的主演: <p class="star">主演:黄渤,张译,韩昊霖</p>+ '.*?<p class="releasetime">(.*?)</p>' # 获取电影的上映时间: <p class="releasetime">上映时间:2019-09-30</p>+ '.*?<i class="integer">(.*?)</i>'+ '*?<i class="fraction">(.*?)</i>' # 评分,整数部分和分数部分'.*?</dd>',re.S)# pattern = re.compile('<dd>.*?board-index.*?>(\d+)</i>.*?data-src="(.*?)".*?name"><a'# + '.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>'# + '.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>', re.S)# findall返回列表, finditer返回的是迭代器# print(html)items = re.finditer(pattern, html)for item in items:yield {'index': item.groups()[0], # 索引'image': item.groups()[1], # 图片链接'title': item.groups()[2], # 影片名称'star': item.groups()[3].strip().lstrip('主演:'),'time': item.groups()[4].lstrip('上映时间:'),'score': item.groups()[5] + item.groups()[6]}# yield {# 'index': item[0],# 'image': item[1],# 'title': item[2],# 'actor': item[3].strip()[3:],# 'time': item[4].strip()[5:],# 'score': item[5] + item[6]# }def save_to_json(data, filename):'''将爬取的数据信息写入json文件中r, r+, w, w+, a, a+解决的问题:1. python数据类型如何存储到文件中? json将python数据类型序列化为json字符串2. json中中文不能存储如何解决? ensure_ascii=False3. 存储到文件中的数据不是utf-8格式的,怎么解决? ''.encode('utf-8'):param item::return:'''# with open(filename, 'ab') as f:# f.write(json.dumps(data, ensure_ascii=False,indent=4).encode('utf-8'))# print(Fore.GREEN + '[+] 保存电影 %s 的信息成功' %(data['title']))with codecs.open(filename, 'a', 'utf-8') as f:# f.write(json.dumps(data, ensure_ascii=False) + '\n')f.write(json.dumps(data, ensure_ascii=False, indent=4))print(Fore.RED + '[+] 保存电影 %s 的信息成功' % (data['title']))def spider(page):'''抓取猫眼TOP100榜单的某一个:param offset::return:'''url = 'https://maoyan.com/board/4?offset=' + str((page-1)*10)html = get_one_page(url) # 通过request请求获取爬取的HTML页面# print(html)items = parse_one_page(html) # 对HTML页面进行解析,并输出for item in items:# print(item)save_to_json(item, 'maoyan.json') # 将输出结果保存为json格式文件def no_use_thread():start = time.time()for i in range(1, 11):spider(page=i)print(Fore.GREEN + '[+] 采集第[%s]页数据' % (i))# 反爬虫策略: 方式爬虫速度太快被限速, 在采集数据的过程中,休眠一段时间time.sleep(1) # 推迟调用线程的运行,可通过参数secs指秒数,表示进程挂起的时间。end = time.time()print('采集结束,no_use_thread()函数爬取时间',end-start)def use_multi_thread():start = time.time()# 使用多线程实现的代码from threading import Threadfor i in range(1, 11):thread = Thread(target=get_one_page, args=(i,)) # 给每一页分配一个线程thread.start()print(Fore.GREEN + '[+] 采集第[%s]页数据' % (i))end = time.time()print('采集结束,use_multi_thread()函数爬取时间', end - start)def use_thread_pool():start = time.time()from concurrent.futures import ThreadPoolExecutor# 实例化线程池并指定线程池线程个数pool = ThreadPoolExecutor(100)pool.map(spider, range(1, 11))end = time.time()print("采集结束,use_thread_pool()函数爬取时间",end - start)'''查询TOP100榜单
'''
if __name__ == '__main__':no_use_thread()# use_multi_thread()# use_thread_pool()3.实验结果
比较无线程、多线程、线程池三种方式实现爬虫的性能对比



4.参考资料
python requests用法总结:https://www.cnblogs.com/lilinwei340/p/6417689.html
爬虫使用代理出现的问题:https://blog.csdn.net/qq_19294857/article/details/99653889
python爬虫—–网络数据分析:https://www.codenong.com/cs105647570/
国内高匿代理:https://www.kuaidaili.com/free/inha/
解决Python3 控制台输出InsecureRequestWarning的问题:https://www.cnblogs.com/helloworldcc/p/11107920.html
这篇关于python爬虫实例—猫眼TOP100榜的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






