本文主要是介绍No module named 'cPickle' python3.6.1 Anaconda4.3.21下pickle模块解决,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
import cPickle as pickle
错误:ModuleNotFoundError: No module named 'cPickle'
cPickle and pickle 它是一个将任意复杂的对象转成对象的文本或二进制的模块。
如何解决?
先看看pickle是干啥的?
持久性就是指保持对象,甚至在多次执行同一程序之间也保持对象
您希望将对象存储在磁盘上,便于以后检索,这就是持久性(你想啥呢!)。
要达到这个目的,有几种方法,每一种方法都有其优缺点 如果希望透明地存储 Python 对象,而不丢失其身份和类型等信息 则需要某种形式的对象 序列化 序列化:是一个将任意复杂的对象转成对象的文本或二进制表示的过程 在 Python 中,这种序列化过程称为 pickle、 可以将对象 pickle 成字符串、磁盘上的文件或者任何类似于文件的对象 也可以将这些字符串、文件或任何类似于文件的对象 unpickle 成原来的对象
先把问题解决了吧!
原来再这里,集成到了,pandas里面了
操作方法:直接在anaconda 安装的文件夹D:\Anaconda\Lib下搜索
上图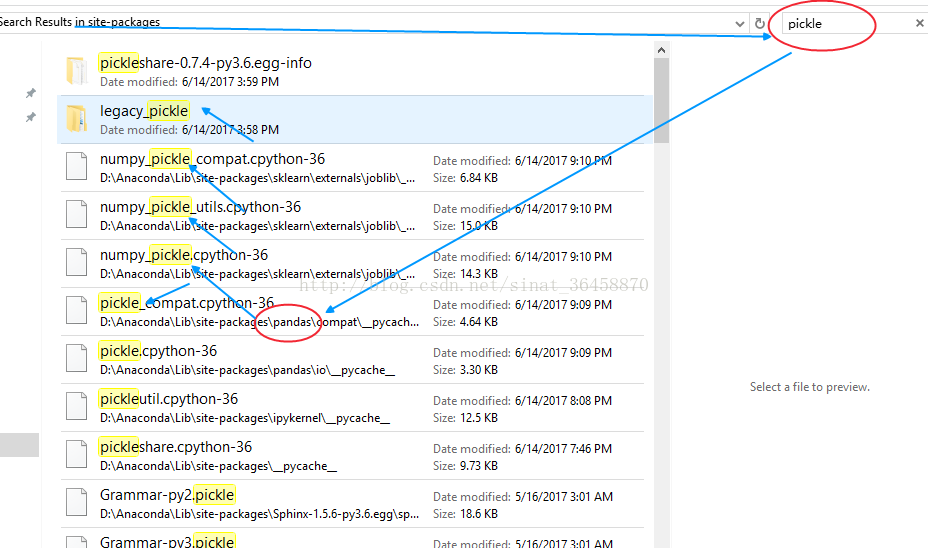
然后就会发现只需要写
import pandas as pd
import pickle然后就可以了
记得先导入pandas
至于用法,这里写的蛮清楚的,就是英文太坑爹。。。各种专业词汇啊
更新,2017/6/21 ! 使用方法!
>>>import pandas as pickle
>>>import pickle
>>> t1 = ('this is a string', 43, [1,2,3], None)
>>> t1
('this is a string', 43, [1, 2, 3], None)
>>> p1 = pickle.dumps(t1)
>>> p1
b'\x80\x03(X\x10\x00\x00\x00this is a stringq\x00K+]q\x01(K\x01K\x02K\x03eNtq\x02.'
>>> print (p1)
b'\x80\x03(X\x10\x00\x00\x00this is a stringq\x00K+]q\x01(K\x01K\x02K\x03eNtq\x02.'
>>> t2 = pickle.loads(p1)
>>> t2
('this is a string', 43, [1, 2, 3], None)
>>> p2 = pickle.dumps(t1, True)
>>> p2
b'(X\x10\x00\x00\x00this is a stringq\x00K+]q\x01(K\x01K\x02K\x03eNtq\x02.'
>>> t3 = pickle.loads(p2)
>>> t3
('this is a string', 43, [1, 2, 3], None)
>>> p2 = pickle.dumps(t1)
>>> p2
b'\x80\x03(X\x10\x00\x00\x00this is a stringq\x00K+]q\x01(K\x01K\x02K\x03eNtq\x02.'
>>> t3 = pickle.loads(p2, True)
Traceback (most recent call last):File "<stdin>", line 1, in <module>
TypeError: Function takes at most 1 positional arguments (2 given)
>>> t4 = pickle.loads(p2)
>>> t4
('this is a string', 43, [1, 2, 3], None)
>>>仔细敲一遍,你就懂了
如果还不懂,看这里!!!!
############### For the simplest code,
############### use the dump() and load() functions.import pickle
data = {'a': [1, 2.0, 4+6j],'b': ("character string", b"byte string"),'c': {None, True, False}}
############## Pickle the 'data' dictionary using the highest protocol available
with open('data.pickle', 'wb') as f:pickle.dump(data, f,pickle.HIGHEST_PROTOCOL)########################## pickle.HIGHEST_PROTOCOL, 这个不要也行
print(f)>>> print(f)
<_io.BufferedWriter name='data.pickle'>############### reads the resulting pickled data
with open('data.pickle', 'rb') as f:data = pickle.load(f)
print (data)>>> print (data)
{'a': [1, 2.0, (4+6j)], 'b': ('character string', b'byte string'), 'c': {False, True, None}}
接下来,我们看一些示例,这些示例用到了 dump() 和 load()
它们使用文件和类似文件的对象。这些函数的操作非常类似于我们刚才所看到的 dumps() 和 loads()
区别在于它们还有另一种能力 — dump() 函数能一个接着一个地将几个对象转储到同一个文件
(和dump根本不相符啊,很厉害的,编写者又调皮了)。
随后调用 load() 来以同样的顺序检索这些对象(这个厉害啊!)
open/文件操作可以看可以看这里(详情可以看这里)
f=open('/tmp/hello','w')
#open(路径+文件名,读写模式)
#读写模式:r只读,r+读写,w新建(会覆盖原有文件),a追加,b二进制文件.常用模式
如:'rb','wb','r+b'等等
如何面对文件操作!
#! /usr/local/env python
# -*- coding=utf-8 -*-if __name__ == "__main__":import pickle#序列化到文件obj = 123,"abcdedf",["ac",123],{"key":"value","key1":"value1"}print (obj)#输出:(123, abcdedf, [ac, 123], {key1: value1, key: value})#r 读写权限 r b 读写到二进制文件f = open(r"d:\Anaconda\envs\my_env\a.txt",'wb')pickle.dump(obj,f)f.close()f = open(r"d:\Anaconda\envs\my_env\a.txt", 'rb')print (pickle.load(f))#输出:(123, abcdedf, [ac, 123], {key1: value1, key: value})#序列化到内存(字符串格式保存),然后对象可以以任何方式处理如通过网络传输obj1 = pickle.dumps(obj)print (type(obj1))#输出:<type str>print (obj1)#输出:python专用的存储格式obj2 = pickle.loads(obj1)print (type(obj2))#输出:<type tuple>print (obj2)#输出:(123, abcdedf, [ac, 123], {key1: value1, key: value})这篇关于No module named 'cPickle' python3.6.1 Anaconda4.3.21下pickle模块解决的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







