本文主要是介绍SQL数据工程师面试题20231226,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、数据库知识:
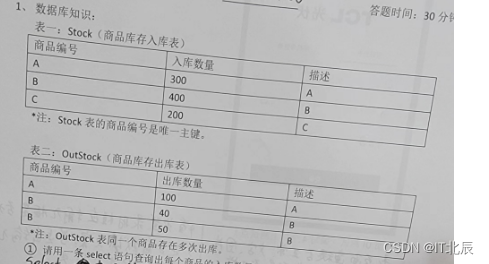
表一:Stock(商品库存入库表)
商品编号 入库数量 描述
A 300 A
B 400 B
C 200 C
注: Stock 表的商品编号是唯一主键。
表二: OutStock(商品库存出库表)
商品编号 出库数量 描述
A 100 A
B 40 B
B 50 B
注: outStock 表同一个商品存在多次出库。
– 创建 Stock 表
CREATE TABLE Stock (
商品编号 VARCHAR(10) PRIMARY KEY,
入库数量 INT,
描述 VARCHAR(255) );– 插入数据到 Stock 表
INSERT INTO Stock (商品编号, 入库数量, 描述) VALUES (‘A’, 300, ‘A’), (‘B’, 400, ‘B’), (‘C’, 200, ‘C’);– 创建 OutStock 表
CREATE TABLE OutStock (
商品编号 VARCHAR(10),
出库数量 INT,
描述 VARCHAR(255) );– 插入数据到 OutStock 表 INSERT INTO OutStock (商品编号, 出库数量, 描述) VALUES (‘A’, 100, ‘A’), (‘B’, 40, ‘B’), (‘B’, 50, ‘B’);
1、请用一条 select 语句查询出每个商品的入库数量。
SELECT 商品编号, SUM(入库数量) AS 总入库数量
FROM Stock
GROUP BY 商品编号;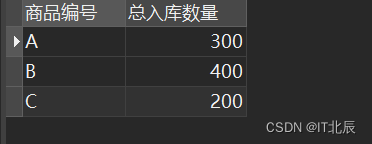
2、请用一条 select 语句查询出每个商品的出库数量:
SELECT 商品编号, COALESCE(SUM(出库数量), 0) AS 总出库数量
FROM OutStock
GROUP BY 商品编号;#这里使用了COALESCE函数,它的作用是返回其参数中的第一个非NULL值。如果SUM(出库数量)的结果为NULL(可能是因为某些商品没有出库记录),则COALESCE函数会返回0,从而确保总出库数量始终有一个明确的值。
例如:SQL实例select coalesce(出库数量, 1) from OutStock当“出库数量”为null值的时候,将返回1,否则将返回“出库数量”的真实值。
第二种写法:
SELECT商品编号,SUM(出库数量) AS 出库数量
FROMOutStock
GROUP BY商品编号;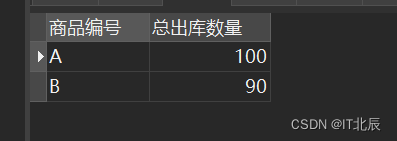
3、请用一条 select 语句查询出剩余数量最大的商品编号:
*注:剩余数量 = 入库数量 - 出库数量
-- 从一个子查询中选择商品编号
SELECT 商品编号
FROM ( -- 子查询中首先从Stock表中选择商品编号,并计算每个商品的剩余数量 SELECT s.商品编号, (SUM(s.入库数量) - COALESCE(SUM(o.出库数量), 0)) AS 剩余数量 FROM Stock s -- 定义了一个别名s来表示Stock表 LEFT JOIN OutStock o ON s.商品编号 = o.商品编号 -- 使用LEFT JOIN连接Stock和OutStock表,连接条件是两个表中的商品编号相同 GROUP BY s.商品编号 -- 按商品编号进行分组,这样就可以对每个商品进行汇总计算
) AS 剩余数量表 -- 给子查询结果起了一个别名"剩余数量表"
ORDER BY 剩余数量 DESC -- 按剩余数量降序排序,这样剩余数量最大的商品会排在最前面
LIMIT 1; -- 只取排序后的第一条记录,即剩余数量最大的商品编号#简而言之,这段SQL代码首先通过子查询计算每个商品的剩余数量(入库数量减去出库数量),然后从这些结果中选取剩余数量最大的商品编号。

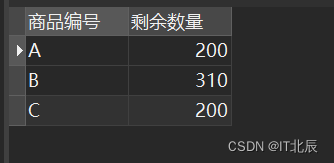
4、 请用一条 select 语句查询剩余数量:
*注:剩余数量 = 入库数量 - 出库数量
-- 从Stock表中选择商品编号和入库数量
SELECT Stock.商品编号, -- 商品编号是唯一标识商品的字段 Stock.入库数量 - COALESCE(OutStock.出库数量, 0) AS 剩余数量 -- 入库数量减去出库数量得到剩余数量
FROM Stock -- 从Stock表开始查询
LEFT JOIN ( -- 使用LEFT JOIN连接一个子查询结果,该子查询计算每个商品的出库数量总和 SELECT 商品编号, -- 商品编号用于分组,表示不同的商品 SUM(出库数量) AS 出库数量 -- 对每个商品的出库数量进行求和,得到该商品的出库总量 FROM OutStock -- 从OutStock表中选择数据 GROUP BY 商品编号 -- 按商品编号进行分组,这样就可以对每个商品进行汇总计算
) AS OutStock -- 给子查询结果起了一个别名OutStock
ON Stock.商品编号 = OutStock.商品编号; -- 使用商品编号作为连接条件,确保我们正确地将Stock表和子查询结果连接在一起#这段SQL代码首先从Stock表中选择商品编号和入库数量。然后,它使用LEFT JOIN连接一个子查询结果,该子查询计算每个商品的出库数量总和。通过商品编号作为连接条件,确保我们正确地将Stock表和子查询结果连接在一起。最后,通过将入库数量与出库数量相减,得到每个商品的剩余数量。
这篇关于SQL数据工程师面试题20231226的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





