本文主要是介绍CSGO直播数据调用的坑,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最近做一个客户项目需要调用游戏直播数据的计分板。
用到的是 NPM HLTV 这个东西
https://www.npmjs.com/package/hltv?activeTab=readme
上面是 HLTV 的说明地址
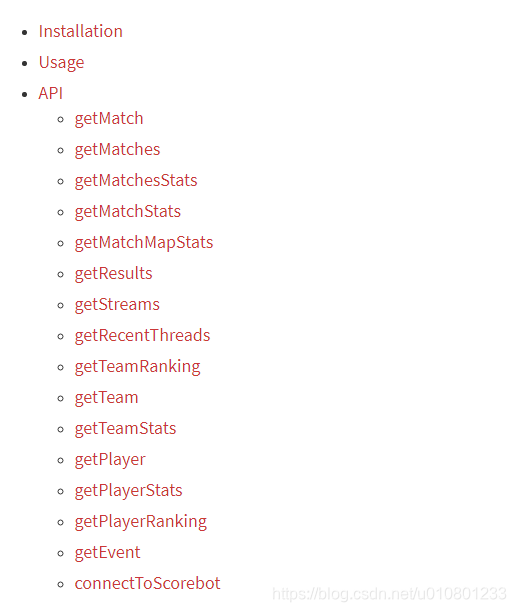
提供了上面的API接口,这里就遇到了一非常坑的问题。
API 下面 除了 connectToScorebot ,其他所有的API 均可在没有直播比赛时正常调取数据。
问题就来了, 当我等到 凌晨12点 使用 connectToScorebot 方法时,一点反应都没有,尝试了N种方法后当天凌晨2点直播结束,但最终还是没有解决问题,依然是无法返回数据。--- 汗啊 ~~~不睡觉干了这么久依然没解决问题。。。。
到了第二天晚上8点又有一场直播,这次终于解决问题了。
先把问题说一下:这个官方 最以一个API connectToScorebot 中其中一个URL 返回值是错误的...真心醉了
先找到 connectToScorebot 的TS 和 JS
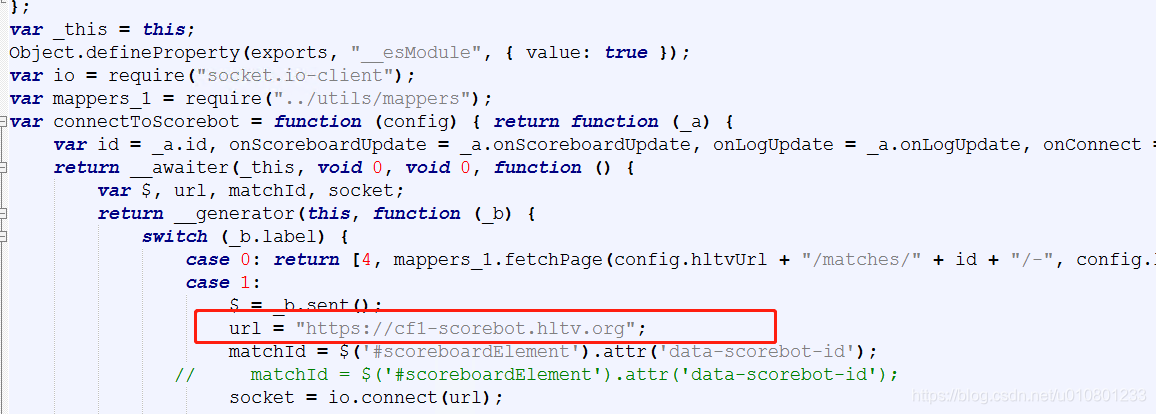
就是这里 这里URL 原来跟下面一样直接是调取的,但是调取出的URL是https://cf1-scorebot.hltv.org,https://cf2-scorebot.hltv.org
这样的竟然直接把2个域名连载一起用了,能回执数据那才有问题。。。。
所以这里应该 先起一个变量将那个获取回来的 分割使用。
然后就测试吧 所有API都可正常工作
这篇关于CSGO直播数据调用的坑的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





