本文主要是介绍NebulaGraph-3.4.1图数据库集群安装部署,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.集群架构
Nebula集群分为测试集群、生产集群,不同环境的集群对应的服务数量不同,大致如下:
| 集群类别 | Meta服务 | Graph服务 | Storage服务 |
| 测试集群 | 1 | >=1 | >=1 |
| 生产集群 | 3 | >=3 | >=3 |
测试环境一般是3台服务器,可以按照如下配置搭建:
| 服务器 | Meta服务 | Graph服务 | Storage服务 |
| 服务器A | 1 | 1 | 1 |
| 服务器B | 1 | 1 | |
| 服务器C | 1 | 1 |
生产环境一般是5台服务器,可以按照如下配置搭建:
| 服务器 | Meta服务 | Graph服务 | Storage服务 |
| 服务器A | 1 | 1 | 1 |
| 服务器B | 1 | 1 | 1 |
| 服务器C | 1 | 1 | 1 |
| 服务器D | 1 | 1 | |
| 服务器E | 1 | 1 |
2.服务部署规划
本地虚拟机采用3台服务器,服务器内核建议使用3.10及以上,搭建测试集群:
| 服务器IP | Meta服务端口号 | Graph服务端口号 | Storage服务端口号 |
| 192.168.153.201 | 9559 | 9669 | 9779 |
| 192.168.153.202 | 9669 | 9779 | |
| 192.168.153.203 | 9669 | 9779 |
3.下载tar软件包安装
官方网址:安装下载 NebulaGraph Database
上传至三台服务器并解压:
tar -zxvf nebula-graph-3.4.1.el7.x86_64.tar.gz
4.集群配置
4.1.进入解压后的目录:cd nebula-graph/etc
需要我们修改 Nebula Graph 的配置文件包含:
nebula-graphd.conf
nebula-metad.conf
nebula-storaged.conf
修改配置文件名以应用配置。
4.2.进入解压出的目录,将子目录etc中的文件nebula-graphd.conf.default、nebula-metad.conf.default和nebula-storaged.conf.default重命名,删除.default,即可应用 NebulaGraph 的默认配置。

4.3.master配置nebula-metad.conf
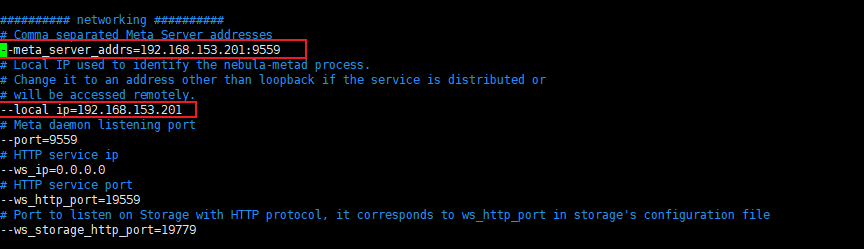
修改meta_server_addrs和local_ip两个字段,其他使用默认字段
########## networking ##########
# Comma separated Meta Server addresses
--meta_server_addrs=192.168.80.128:9559
# Local IP used to identify the nebula-metad process.
# Change it to an address other than loopback if the service is distributed or
# will be accessed remotely.
--local_ip=192.168.80.128
# Meta daemon listening port
--port=9559
4.4.master修改配置文件nebula-graphd.conf
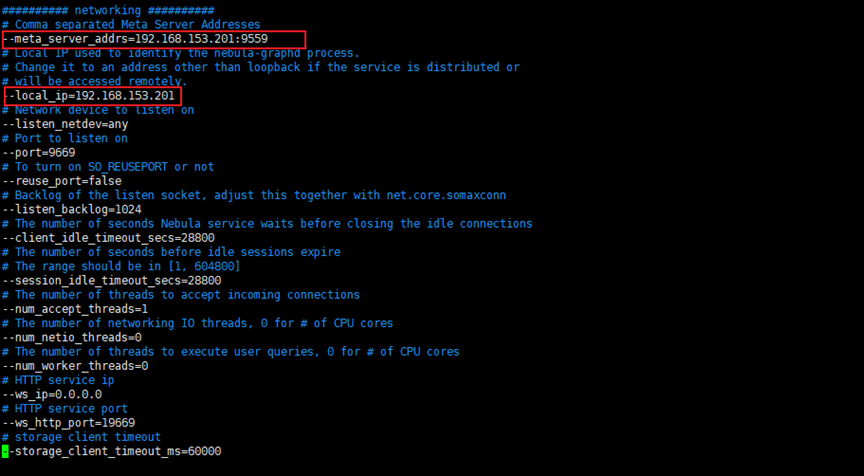
修改meta_server_addrs和local_ip两个字段,其他使用默认字段
########## networking ##########
# Comma separated Meta Server addresses
--meta_server_addrs=192.168.80.128:9559
# Local IP used to identify the nebula-metad process.
# Change it to an address other than loopback if the service is distributed or
# will be accessed remotely.
--local_ip=192.168.80.128
# Meta daemon listening port
--port=9669
4.5. master修改配置文件nebula-storaged.conf
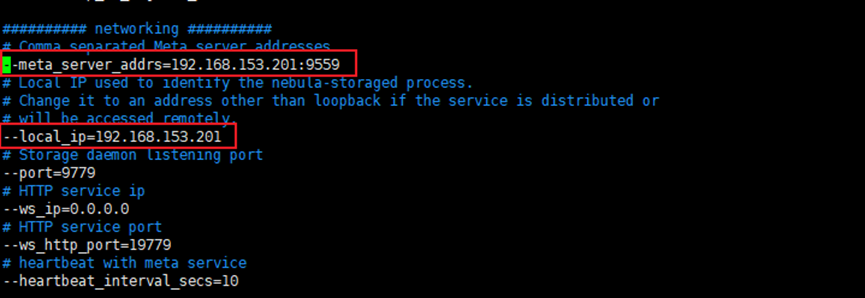
修改meta_server_addrs和local_ip两个字段,其他使用默认字段=
########## networking ##########
# Comma separated Meta Server addresses
--meta_server_addrs=192.168.80.128:9559
# Local IP used to identify the nebula-metad process.
# Change it to an address other than loopback if the service is distributed or
# will be accessed remotely.
--local_ip=192.168.80.128
# Meta daemon listening port
--port=9779
 4.6.修改另外两台slave机器的配置文件
4.6.修改另外两台slave机器的配置文件
只需要修改 nebula-graphd.conf、nebula-storaged.conf 这两个配置文件
meta_server_addrs 都指向提供 metadata service 的机器
local_ip 分别指向自己
如果修改了配置文件,希望新配置生效,请在配置文件开头添加--local_config=true再重启服务,否则会从缓存中读取过期配置。
5.验证和授权
身份验证
身份验证用于将会话映射到特定用户,从而实现访问控制
当客户端连接到 Nebula Graph 时,Nebula Graph 会创建一个会话,会话中存储连接的各种信息,如果开启了身份验证,就会将会话映射到对应
的用户。
默认情况下,身份验证功能是关闭的,用户可以使用 root 用户名和任意密码连接到 Nebula Graph。
Nebula Graph 支持两种身份验证方式:本地身份验证和 LDAP 验证。
本地身份验证
本地身份验证是指在服务器本地存储用户名、加密密码,当用户尝试访问 Nebula Graph 时,将进行身份验证。
启用本地身份验证
编辑配置文件 nebula-graphd.conf (默认目录为 /usr/local/nebula/etc/ ),设置如下参数:
–enable_authorize :是否启用身份验证,可选值: true 、 false 。
–failed_login_attempts :可选项,需要手动添加该参数。单个 Graph 节点允许连续输入错误密码的次数。超过该次数时,账户会被锁定。如果有多个
Graph 节点,允许的次数为 节点数 * 次数 。
–password_lock_time_in_secs :可选项,需要手动添加该参数。多次输入错误密码后,账户被锁定的时间。单位:秒。
重启 Nebula Graph 服务
开启身份验证后,默认的 God 角色账号为 root ,密码为 nebula 。角色详情请参见内置角色权限。
6. 启动服务
master:
nebula-graph/scripts/nebula.service start all
nebula-graph 启动之后,发现有警告信息,提示 ADD HOSTS 。
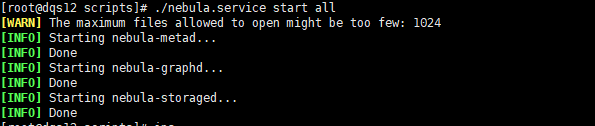
处理报错:
[WARN] The maximum files allowed to open might be too few: 1024
修改文件/etc/security/limits.conf
* soft nofile 204800
* hard nofile 204800
* soft nproc 204800
* hard nproc 204800
需重启服务器才可生效

slave1和slave2:
nebula-graph/scripts/nebula.service start graphd
nebula-graph/scripts/nebula.service start storaged

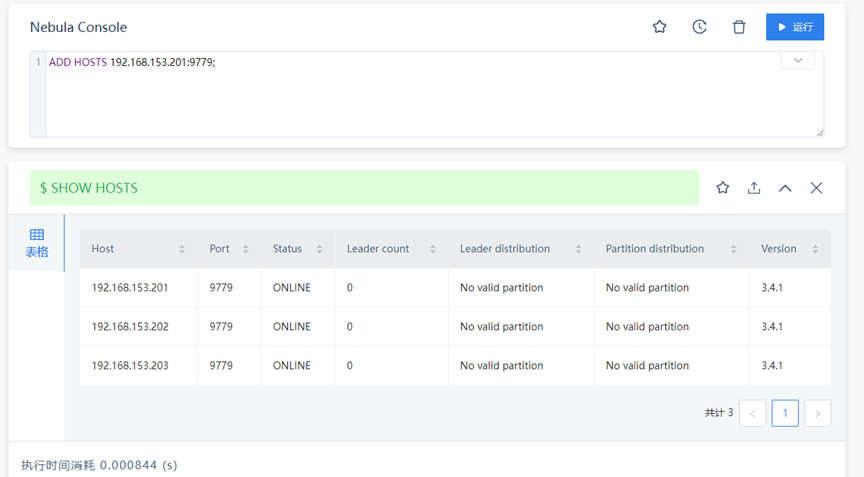
- 解决方式:在nebula-graph-studio 可视化界面的控制控制台执行指令
ADD HOSTS 192.168.153.201:9779;
将三个storage主机添加进去即可。
- 数据库工具部署
NebulaGraph Studio 是一款可以通过 Web 访问的开源图数据库可视化工具

安装包下载地址:Studio NebulaGraph Database
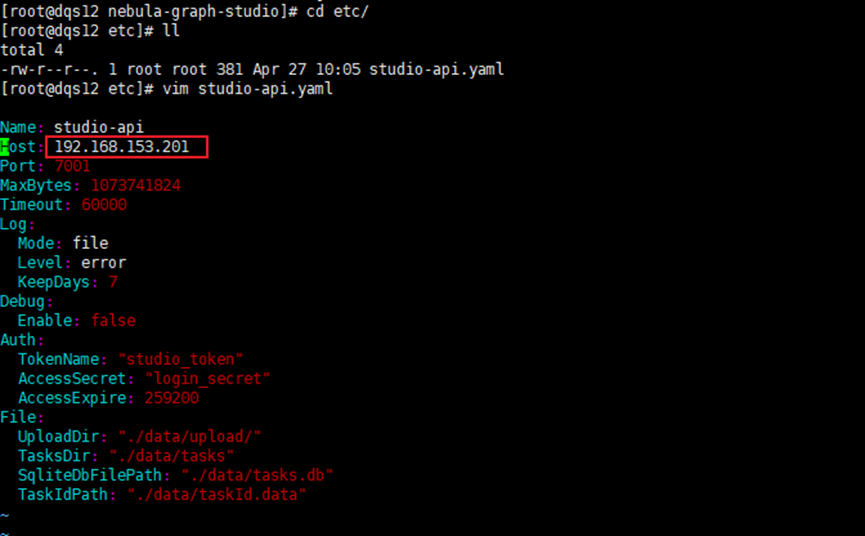
上传至任意一台服务器并解压,然后进入etc目录修改studio-api.yaml文件
将host配置为当前服务器ip即可。
 启动服务
启动服务
nohup ./server start &
访问web:http://192.168.153.201:7001/login
由于未开启认证,输入ip端口后,用户为root,未开启认证密码随意输入即可登录,开启认证需先使用默认密码nebula登录。

7.OpenLDAP 验证
OpenLDAP 是轻型目录访问协议(LDAP)的开源实现,可以实现账号集中管理
当前仅企业版支持集成 OpenLDAP 进行身份验证,详情请参见使用 OpenLDAP 进行身份验证
用户管理
用户管理是 Nebula Graph 访问控制中不可或缺的组成部分,本文将介绍用户管理的相关语法。
开启身份验证后,用户需要使用已创建的用户才能连接 Nebula Graph,而且连接后可以进行的操作也取决于该用户拥有的角色权限。
默认情况下,身份验证功能是关闭的,用户可以使用 root 用户名和任意密码连接到 Nebula Graph。
修改权限后,对应的用户需要重新登录才能生效
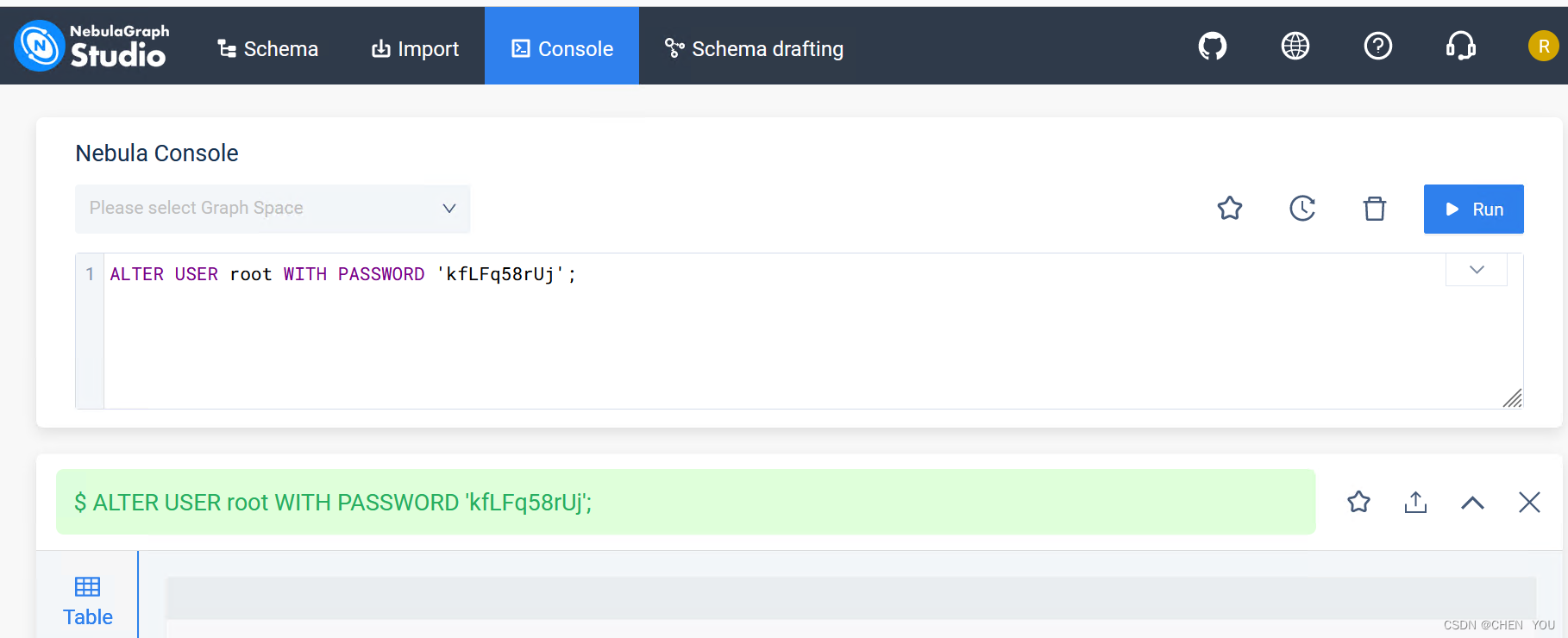
修改用户密码( ALTER USER )
执行 ALTER USER 语句可以修改用户密码,修改时不需要提供旧密码。当前仅 God 角色用户(即 root 用户)能够执行 ALTER USER 语句。
这篇关于NebulaGraph-3.4.1图数据库集群安装部署的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









