本文主要是介绍Java转大数据第一课(必修课)(用汗水为后来人做铺垫-----非常详细图文步骤),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
搭建Hadoop环境(jdk8/Hadoop2.x/viralbox)
准备工作
- (1)关闭防火墙、主机名
- (2)安装JDK
- (3)免密码登录
准备工具:
jdk
virtualBox
iso
安装过程:
1、环境搭建

安装完毕以后,VirualBox是没有64位显示的,那么我们需要按照如下图更改BIOS配置。
选择自己新建的类型,这里选择linux、选择版本red hat














ipv4和掩码,记得ipv4配置192.168的网段,我这里配置192.168.56.111。掩码:255.255.255.0







2、关闭防火墙

补充:
这里如果你依然链接不上链接:检查密码也对。拒绝访问或者就是ping ip超时,那么问题是在网络链接的四种模式。默认是NAT。你可以修改为

3、配置JDK
解压jdk到指定目录/usr/local:tar -zxvf jdk-8u144-linux-x64.tar.gz -C /usr/local


4、配置Hadoop
解压hadoop到指定文件: tar -xzvf hadoop-2.7.3.tar.gz -C /usr/local
jdk中配置hadoop路径
export JAVA_HOME=/usr/local/jdk1.8.0_144
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:${JRE_HOME}/lib
export HADOOP_HOME=/usr/local/hadoop-2.7.3
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export PATH=$JAVA_HOME/bin:$PATH
每次修改完/etc/profile文件都需要重新激活配置否则不生效:source /etc/profile

Hadoop中也需要配置jdk:

5、本地模式启动Hadoop

小结:在这个过程中,如果你需要上传文件则这里可以通过xftp或者winscp。
这里经常会遇见问题:比如说,拒绝访问。比如说root密码对但是登录不上。别着急,别慌。两种检查方案:
1、检查你的连接IP是否正确通过 ifconfig。
如果没有ifconfig。那么可以选用ip addr show的命令格式查看
2、检查是否安装了ssh服务
查看ssh的安装包 :rpm -qa | grep ssh
查看ssh是否安装成功 :ps -ef | grep ssh
开启sshd服务 :service sshd start
开启sshd服务 :/bin/systemctl start sshd.service
查看sshd服务的网络连接情况:netstat -ntlp 安装ssh
因为以后的操作要用到ssh面密登录,现在先确保系统里安装好ssh. 如
果未安装可利用sudo apt-get install ssh 安装,使用ssh localhost 来ssh登陆本机
使用命令dpkg –l |grep ssh
检查是否安装openssh-server
没有的话使用apt-get安装。
安装完成之后检查是否启动:
有sshd说明已经启动,没有启动的话使用命令:
/etc/init.d/ssh start 来启动ssh服务。tips:
service ssh restart是centos 6的命令。
centos 7的命令应该是:systemctl restart sshd
3、检查是否不允许让root登录
编辑/etc/ssh/sshd_config文件
sudo vi /etc/ssh/sshd_config
1.编辑 /etc/ssh/sshd_config文件: sudo vi /etc/ssh/sshd_config将PermitRootLogin 的值改成 yes将PermitEmptyPassword 的值改成 no保存退出 重启ssh
Hadoop的分布式配置文件图,由于是别人的,所以有些信息和我这里对不上。但是我大体说明下就可以知道了。把/root/training/换成我们这里的/usr/local就可以了

6、启动伪分布式Hadoop
由于刚才我们有个步骤非常恶心,就是选择yes连续才能启动起来。那么我们需要设置免密登录。
6.1免密登录
所以这里我重新设置了hostName以后再进行面密登录:
步骤如下:ssh-keygen -t rsa -P ''

cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
chmod 600 /root/.ssh/authorized_keys

完成之后,以 root 用户登录,修改 ssh 配置文件
vi /etc/ssh/sshd_config把文件中的下面几条信息的注释去掉: RSAAuthentication yes # 启用 RSA 认证PubkeyAuthentication yes # 启用公钥私钥配对认证方式AuthorizedKeysFile .ssh/authorized_keys # 公钥文件路径(和上面生成的文件同)

重启服务:systemctl restart sshd.service
然后ssh localhost登录发现异常

The authenticity of host ‘localhost (::1)’ can’t be established.
ECDSA key fingerprint is SHA256:X+9DEX5+oCD0NyGctt0HK8swVeVvOZOFhJbBt0Vguv8.
ECDSA key fingerprint is MD5:16:33:69:41:1d:99:37:27:5b:81:0e:ee?82:ec:fd.
Fix it:
方法一
ssh -o StrictHostKeyChecking=no 192.168.xxx.xxx(我这里的链接是配置的192.168.56.111)
方法二
一个彻底去掉这个提示的方法是,修改/etc/ssh/ssh_config文件(或$HOME/.ssh/config)中的配置,添加如下两行配置:
StrictHostKeyChecking no
UserKnownHostsFile /dev/null
修改好配置后,重新启动sshd服务即可。
重启ssh服务命令为systemctl restart sshd.service



6.2伪分布式环境搭建配置
6.2.1、上传和解压hadoop并配置环境变量
上面解压和配置etc/profile的hadoop变量已经完成,现在配置伪分布式环境
6.2.2、创建hadoop文件夹下的tmp目录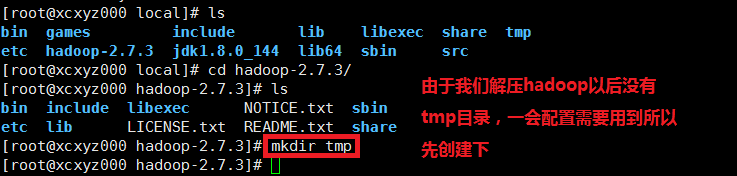
6.2.3、在hadoop-env.sh增加环境变量

6.2.4、在hdfs-site.xml修改数据块的冗余度和禁用HDFS权限检查
(*)hdfs-site.xml<!--数据块的冗余度默认3--><!--原则数据块的冗余度跟数据节点个数一样,最大不超过3--><property><name>dfs.replication</name><value>1</value></property><!--禁用HDFS权限检查--><property><name>dfs.permissions</name><value>false</value></property>

6.2.5、在core-site.xml修改NameNode的地址和HDFS对应的操作系统目录
(*)core-site.xml<!--NameNode的地址--><property><name>fs.defaultFS</name><!-- 192.168.56.111是我们之前配置的虚拟机ip地址--><value>hdfs://192.168.56.111:9000</value></property> <!--HDFS对应的操作系统目录--><property><name>hadoop.tmp.dir</name><!--正式配置参数前创建的目录路径--><value>/usr/local/hadoop-2.7.3/tmp</value></property>

6.2.6、在mapred-site.xml增加yarn容器的配置
(*)mapred-site(.xml/.tmplate)<property><name>mapreduce.framework.name</name><value>yarn</value></property>如果是tmplate结尾,更改为复制template,生成xml,命令如下:cp mapred-site.xml.template mapred-site.xml


6.2.7、在yarn-site.xml增加resourcemanager的地址和洗牌配置
(*)yarn-site.xml<!--ResourceManager地址--><property><name>yarn.resourcemanager.hostname</name><value>192.168.56.111</value></property><!--洗牌--><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property>

到此我们便配置完成一个 hdfs 伪分布式环境

6.2.7、 启动 hdfs Single Node,格式化NameNode,比较重要
①、初始化 hdfs 文件系统
bin/hdfs namenode -format

②、启动 hdfs
sbin/start-dfs.sh,但是我们这里配置了yarn容器所以我们可以直接start-all.sh启动hdfs服务和yarn服务


在你的浏览器内输入你的虚拟主机ip:50070访问namenode服务


这里的黄色信息192.168.56.101就是上面我们提到启动的时候日志提示的信息。



以下是错误失败次数导致的积累。从某种意义上说,多经历几次失败就好了。如果你按照上面的教程没有成功,则肯定是你没看仔细或者省略了步骤,再重新来一遍就好了。对了版本要一致,不同的版本不同的坑。
如果不格式化启动服务,然后再格式化的情况下不能访问50070服务namenode,只能访问如下界面



问题很难过:
hadoop无法访问50070端口怎么办?
Hadoop 50070是hdfs的web管理页面,在搭建Hadoop集群环境时,有些大数据开发技术人员会遇到Hadoop 50070端口打不开的情况,引起该问题的原因很多,想要解决这个问题需要从以下方面进行排查!1. 排查Namenode是否部署成功排查Namenode是否部署成功可以采用命令jps两种方式之一查看,如Namenode未部署成功,需重新部署Namenode;若已部署成功,请进行第二步排查!2. 排查datanode是否部署成功排查datanode是否部署成功可以采用jps命令进行查看,如果部署未成功,找到问题节点进行解决;若部署成功请进行第三步。3.排查防火墙是否开启排查防火墙是否正常开启,如果防火墙关闭了,可按照以下方式进行设置:netstat –ant #查看本地开发端口127.0.0.1 50070在hdfs-site.xml中,更改开放端口的绑定IP:<property><name>dfs.http.address</name><value>0.0.0.0:50070</value></property>将绑定IP改为0.0.0.0,而不是本地回环IP,这样,就能够实现外网访问本机的50070端口了
排查问题:5个节点都启动成功
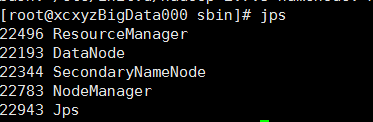

更改0.0.0.0:50070依然失败。无法访问50070.
过程中遇见的其他问题:
userdel -r hadoop
group hadoop not removed because it has other members.
免密登录不能使用hostname大写字母

这篇关于Java转大数据第一课(必修课)(用汗水为后来人做铺垫-----非常详细图文步骤)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





