本文主要是介绍mac 百度云盘开机启动服务器,Mac 上使用百度网盘很烦躁?花点时间配置 aria2 吧...,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Mac 用户肯定都受够了百度网盘在自己电脑上的糟糕体验,至少我是如此:安装官方的 App,经常下载时中断,有时甚至 Bug 般连续中断,无奈使用浏览器下载,速度却是令人挠头。花点时间来配置 aria2,结合 Chrome,一定让你舒心。
aria2 是什么?
aria2 是一款支持多种协议的轻量级命令行下载工具。有以下特性:
多线程连线:aria2 会自动从多个线程下载文件,并充分利用你的带宽;
轻量:运行时不会占用过多资源,根据官方介绍,内存占用通常在 4MB~9MB,使用 BitTorrent 协议,下行速度 2.8MB/s 时 CPU 占用率约 6%;
全功能 BitTorrent 客户端;
支持 RPC 界面远程控制(下文重点介绍)。
开始吧
1. 下载 aria2
你可以在 aria2 的 Download 下载对应的安装程序。下载之后直接双击打开安装即可。喜欢用 homebrew 的同学也可以使用命令brew install aria2来安装,已经安装好 aria2 的同学直接看第五步。
(注:目前所有系统版本均已无需操作第二步)
2. 如果是 El Capitan 用户,你要做的
由于 El Capitan 增加了系统完整性保护(System Integrity Protection),需要先暂时关闭才可进行下一步。操作如下:重启机器,开启时按住 ⌘ Cmd+R,接着在菜单栏选择工具→终端,输入:
csrutil disable
接着进行第三步,切记:第三步结束之后要重新开启,同样的步骤,输入:
csrutil enable
3. 安装 Homebrew
直接在终端里输入:
ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)" 接着等待进度条走完。等到一堆代码跳完之后根据提示按下回车键(Return)。
4. 安装 aria2
在终端输入命令:
brew install aria2
5. 设置配置文件
aria2 提供两种方式使用,一种是直接命令行模式下载,不推荐使用这种方法,推荐使用另外一种 RPC 模式,这种方式 aria 启动之后只会安静的等待下载请求,下载完成后也只会安静的驻留后台不会自动退出。而使用RPC模式推荐做一个配置文件方便使用。我们把配置文件放在 ~/.aria2 下,依次输入命令:
cd ~
mkdir .aria2
cd .aria2
touch aria2.conf
接着打开 Finder,利用 Shift+Cmd+G 进入路径:~/.aria2/aria2.conf,用文本编辑器打开 aria2.conf,将 雪月秋水君 提供的以下配置直接拷贝进去:
#用户名
#rpc-user=user
#密码
#rpc-passwd=passwd
#上面的认证方式不建议使用,建议使用下面的token方式
#设置加密的密钥
#rpc-secret=token
#允许rpc
enable-rpc=true
#允许所有来源, web界面跨域权限需要
rpc-allow-origin-all=true
#允许外部访问,false的话只监听本地端口
rpc-listen-all=true
#RPC端口, 仅当默认端口被占用时修改
#rpc-listen-port=6800
#最大同时下载数(任务数), 路由建议值: 3
max-concurrent-downloads=5
#断点续传
continue=true
#同服务器连接数
max-connection-per-server=5
#最小文件分片大小, 下载线程数上限取决于能分出多少片, 对于小文件重要
min-split-size=10M
#单文件最大线程数, 路由建议值: 5
split=10
#下载速度限制
max-overall-download-limit=0
#单文件速度限制
max-download-limit=0
#上传速度限制
max-overall-upload-limit=0
#单文件速度限制
max-upload-limit=0
#断开速度过慢的连接
#lowest-speed-limit=0
#验证用,需要1.16.1之后的release版本
#referer=*
#文件保存路径, 默认为当前启动位置
dir=/Users/xxx/Downloads
#文件缓存, 使用内置的文件缓存, 如果你不相信Linux内核文件缓存和磁盘内置缓存时使用, 需要1.16及以上版本
#disk-cache=0
#另一种Linux文件缓存方式, 使用前确保您使用的内核支持此选项, 需要1.15及以上版本(?)
#enable-mmap=true
#文件预分配, 能有效降低文件碎片, 提高磁盘性能. 缺点是预分配时间较长
#所需时间 none < falloc ? trunc « prealloc, falloc和trunc需要文件系统和内核支持
file-allocation=prealloc
默认下载路径的「/Users/xxx/Downloads」可以改为任何你想要的绝对路径。此处写为 Downloads 目录,xxx 请自行替换成你的 Mac 用户名,然后保存,退出编辑器。
6. 启动 RPC 模式
在终端输入aria2c --conf-path="/Users/xxxxxx/.aria2/aria2.conf" -D,然后 aria2 就启动了,但是如何搞定百度网盘?还需要在 这里 下载 Chrome 插件。
如何进行下载操作?
随便打开一个百度网盘的链接,会发现网页上多出一个「导出下载」按钮,点击它弹出的「ARIA2 RPC」就自动添加到你的下载队列里了,然后利用 这里 提供的网页界面管理你的下载任务,如下图所示,你可以利用图形界面进行许多操作:
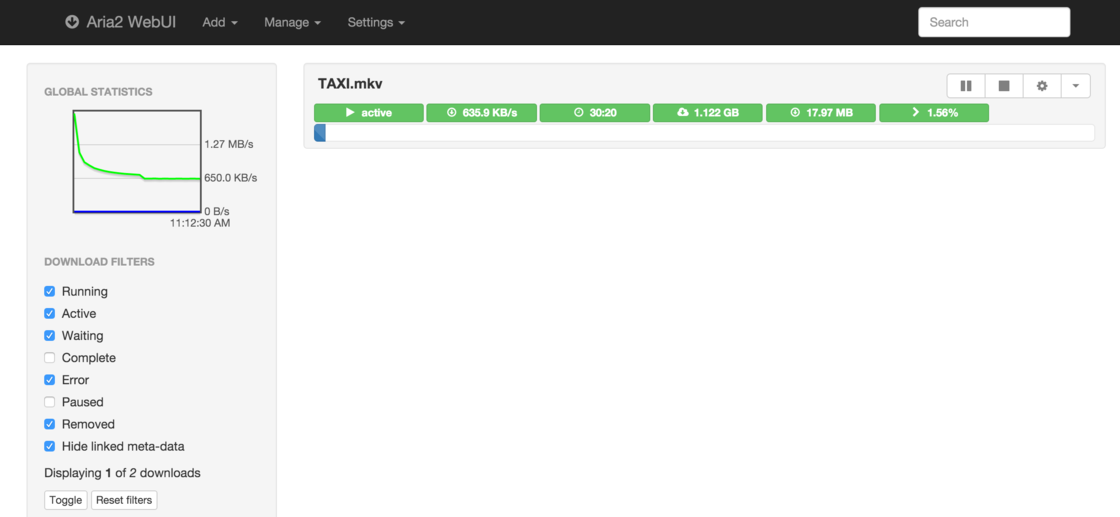
如果你想关掉后台的 aria2,可以到活动监视器中找到 aria2c 杀掉,也可以在终端输入kill aria2之后按 Tab 键,aria2 会自动变成进程号,回车即可杀掉它。
Two More Thing
如果在 Chrome 插件使用中遇到问题,请到这里反馈。
感谢某位保持匿名的软件工程师。
这篇关于mac 百度云盘开机启动服务器,Mac 上使用百度网盘很烦躁?花点时间配置 aria2 吧...的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







