本文主要是介绍AlignBench:量身打造的中文大语言模型对齐评测,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
对齐(Alignment),是指大语言模型(LLM)与人类意图的一致性。换言之,就是让LLM生成的结果更加符合人类的预期,包括遵循人类的指令,理解人类的意图,进而能产生有帮助的回答等。对齐是决定LLM能否在实际场景中得到真正应用的关键因素。因此,评估模型的对齐水平显得至关重要 —— 如果没有评估,我们就无法判断模型的优劣。
然而,至今为止,中文评测领域关于对齐的评测仍然是一片空白。当前广泛使用的一些评测数据集,如 MMLU,C-Eval 等,与真实使用场景的差别较大,不能有效评估模型的指令遵循能力。针对对齐水平的英文评测数据集,如 MT-Bench,AlpacaEval等,受限于其语言、数量、评测方式,也并不能有效评估中文大模型的对齐水平。考虑到以上因素,以及实际的需求,智谱清言团队推出了AlignBench。
论文:https://arxiv.org/abs/2311.18743
数据、代码:https://github.com/THUDM/AlignBench
项目网站:LLMBench
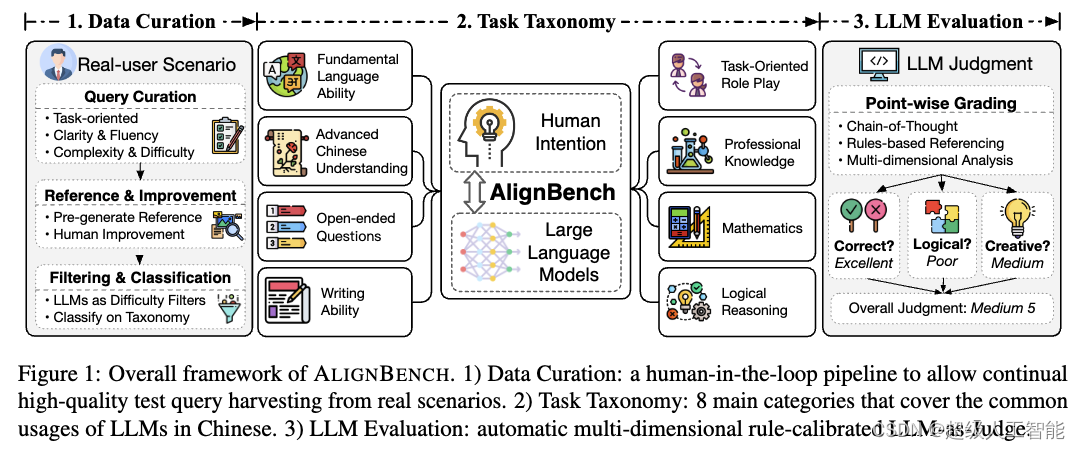
AlignBench是一个多维度、综合性的评测基准。目前来看,这是第一个专为中文大模型设计,能够在多维度上细致评测模型和人类意图对齐水平的评测基准。将 AlignBench 在评测数据和评测方法上与其他基准的对比情况总结如下:

为了让开发人员能够更加高效地完成评估,作者也开发了自动评估模型 CritiqueLLM ,它是一个能够达到 GPT-4 95% 评估能力的专用的评测模型。可以在 AlignBench 网站上使用 CritiqueLLM 进行评测。
数据集
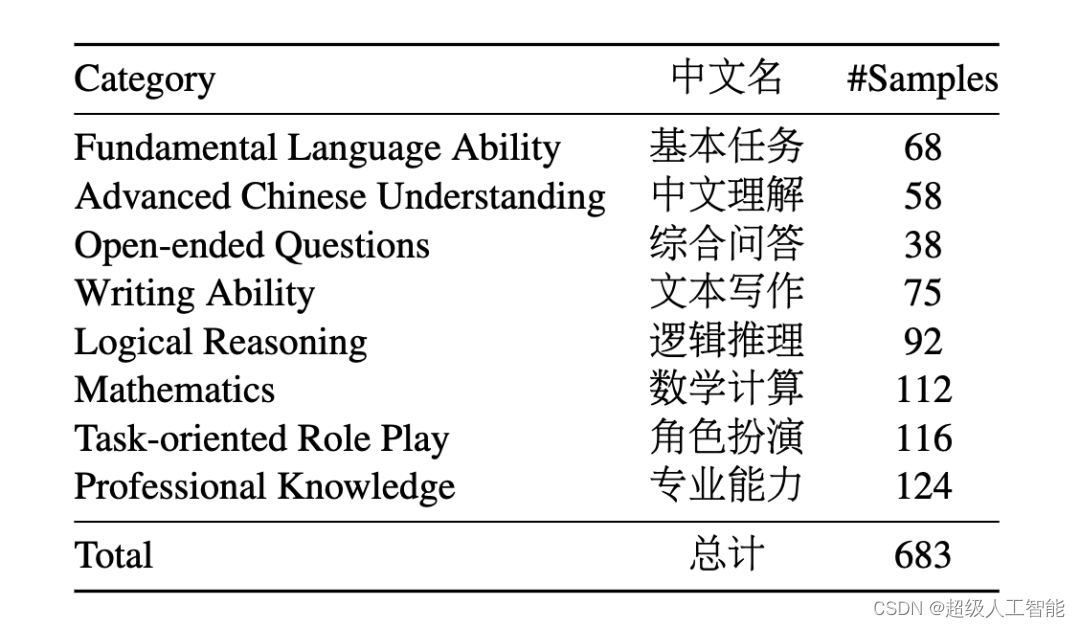
AlignBench 从 ChatGLM 真实的使用场景中构建,经过初步构造,敏感性筛查,参考答案生成,难度筛选等步骤,构建了具有真实性、挑战性的评测数据集。AlignBench 构建了综合全面的分类体系,分为 8 个大类。
评测方法
AlignBench 使用评分模型(GPT-4,CritiqueLLM)为每个模型的回答打 1-10 的综合分数,代表其回答质量。AlignBench 构建了多维度、规则校准的模型评测方法,有效提升了模型评分和人类评分的一致性,以及模型评价的质量。
1. 多维度:AlignBench 针对每个种类定制了多个细分的评测维度(如创造性、逻辑性等等)。
2. 规则校准:AlignBench 引入了细致的打分规则,提升和人类的一致程度。
评测表明,所提出的模型评测方法提高了和人类评分的一致性。在生成的分析上,所提出的方法能够显著提高分析的质量。在对分析质量的成对评估中,所提出的方法分别以 12.4% 和 20.40% 的胜负差显著胜出。
评测结果
使用 gpt-4-0613 和 CritiqueLLM 分别作为评分模型对 17 个中文大模型进行了评测,结果分别如下。


结果表明:
1. 中文大模型相比于 gpt-4,在逻辑推理能力上差距较大。
2. 顶尖中文大模型相比于 gpt-4,在中文相关能力(尤其是中文理解类)能取得相近甚至更好的表现。
3. 中文大模型的开源活力充沛,顶尖开源模型对齐表现接近闭源模型,已处于同一梯队。
这篇关于AlignBench:量身打造的中文大语言模型对齐评测的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








