本文主要是介绍Hierarchical combinatorial deep learning architecture for pancreas segmentation-笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Network architecture
网络结构来源于RCF network。RCF基于Holistically-nested Edge Detection (HED) network,是一个边缘检测结构,目的是提取自然图片的显著的边缘和物体的边界。
网络结构如图:
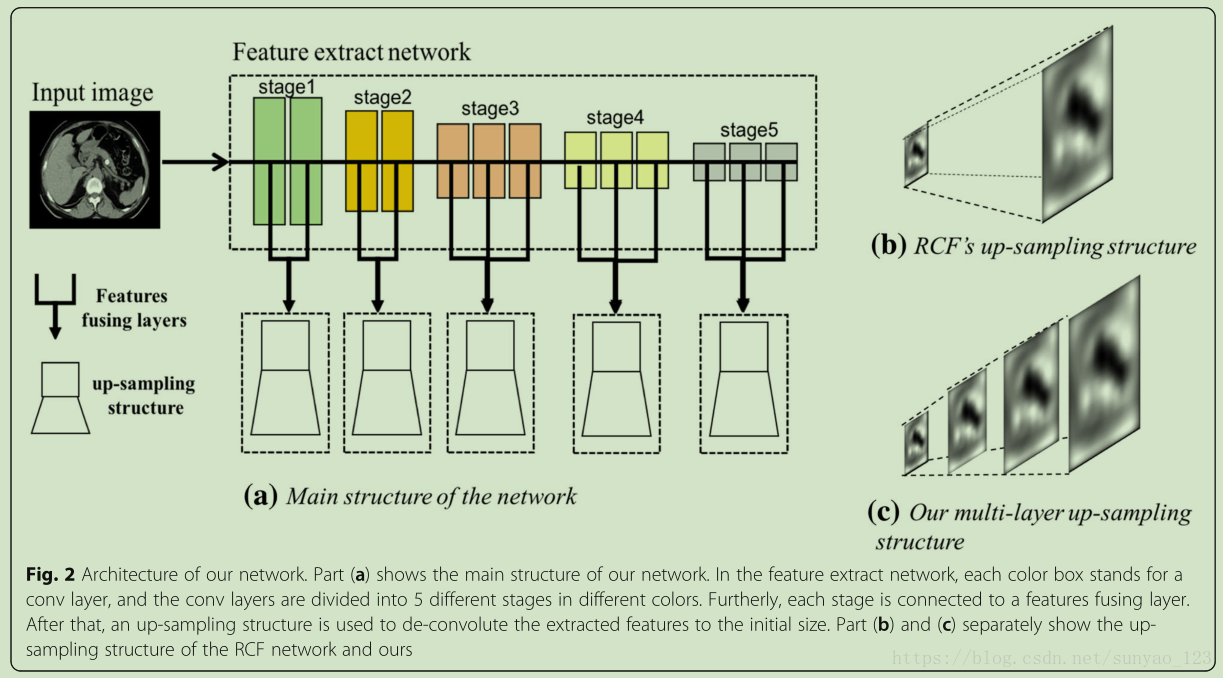
虽然这个图画的不太常规,好像很厉害,但是有类似的结构。4个pooling,5个stages,13个卷积。每个stage后边加特征融合层,对5个stage提取的特征进行融合。每个stage之间的卷积核大小为1X1,通道21。将每个stage不同卷积层输出的特征进行堆积,得到混合特征,然后通过一个1X1@1的卷积层。特征融合层厚,通过反卷积对特征图进行上采样,得到和原图一样大小的特征图。
使用双线性插值对不同的卷积核进行初始化。
网络具体细节如下:
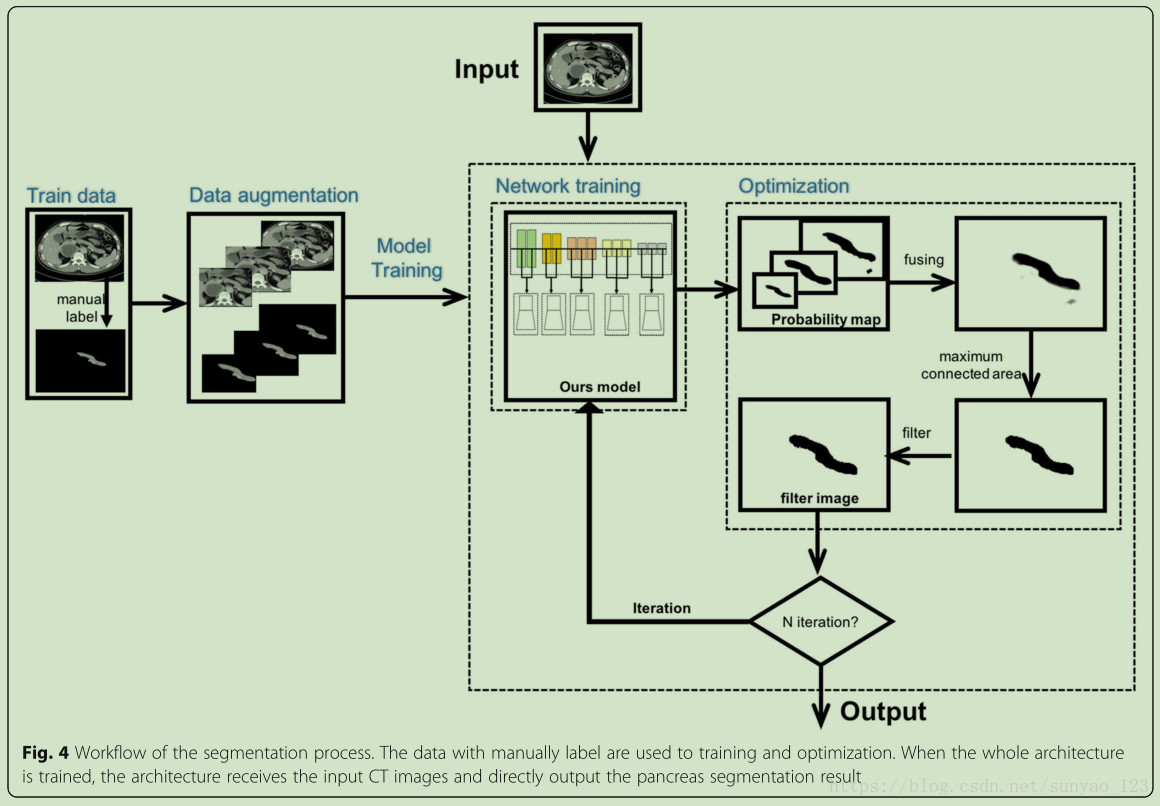
对原图进行裁剪。通过平移和缩放进行数据增强【28】。使用BSDS500【26】数据集进行迁移学习。【29】证明了迁移学习对医学图像任务的重要性。对label进行处理,将目标区域变为0黑色,背景变为255白色。
训练过程
优化过程(其实就是后处理):分为3步,融合,最大化相连区域,阈值滤波器处理。融合,一系列的概率图被融合为1个新图,其实就是将5个stage输出的每个特征图,进行二值化(大于0为255)后相加,然后取平均值,即除以5。最大化相连区域,首先将融合后的图像进行二值化(也是大于0为255),找到二值化图中,相邻非零像素,然后得到几个相连区域,然后选择最大面积的区域;阈值滤波器处理,使用得到这个最大区域对原图进行分割。
评价标准:
Precision,Recall,Dice Similarity Coefficient,Jaccard similarity coefficient。
损失函数
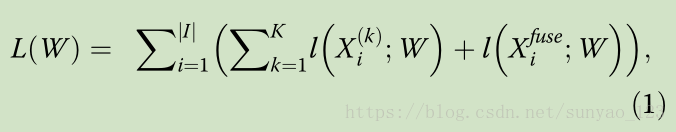
I为每个像素;K表示5个stage,因为每个stage都会有输出;最后一项为经过融合(优化过程第一步)后的概率图的损失。
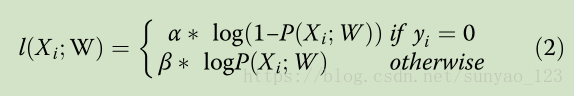
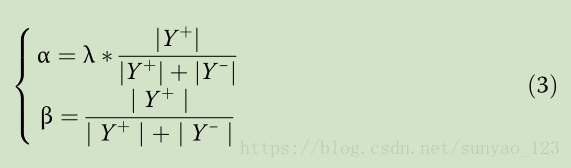
为了平衡正负样本,使用超参数 λ (训练时使用1.1)。+代表原图正样本,-代表原图负样本。
这篇关于Hierarchical combinatorial deep learning architecture for pancreas segmentation-笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








