本文主要是介绍数字化时代的探索:学生为何对数据可视化趋之若鹜?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
随着信息时代的迅猛发展,数据已经成为我们生活中不可或缺的一部分。而在这个数字化浪潮中,越来越多的学生开始关注数据可视化,这并非偶然。下面,我就从可视化从业者的角度出发,简单聊聊为什么越来越多的学生开始关注数据可视化。
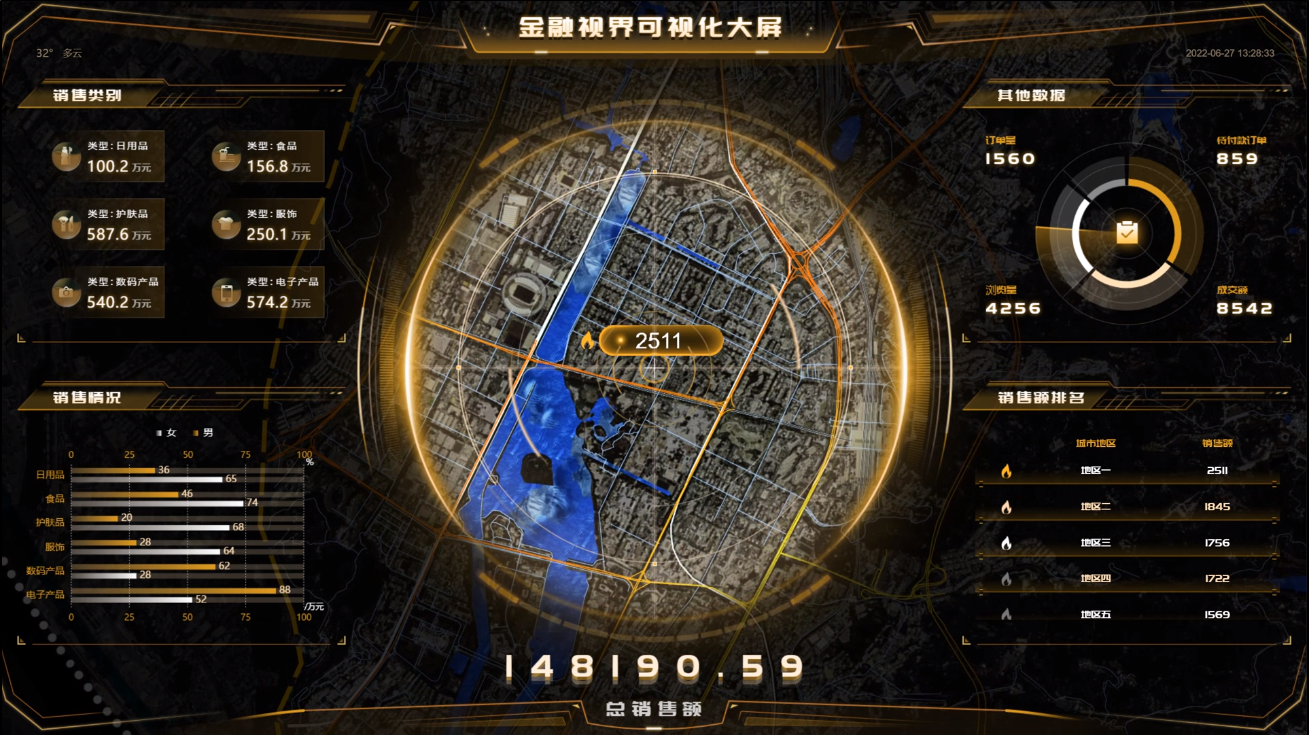
首先,数据可视化为学生提供了更直观的学习体验。相较于枯燥的文字和表格,通过图表、图形的形式呈现数据,学生能够更容易地理解抽象的概念和复杂的信息。这种直观的学习方式不仅能够激发学生的学习兴趣,还能够帮助他们更深刻地理解学科知识。
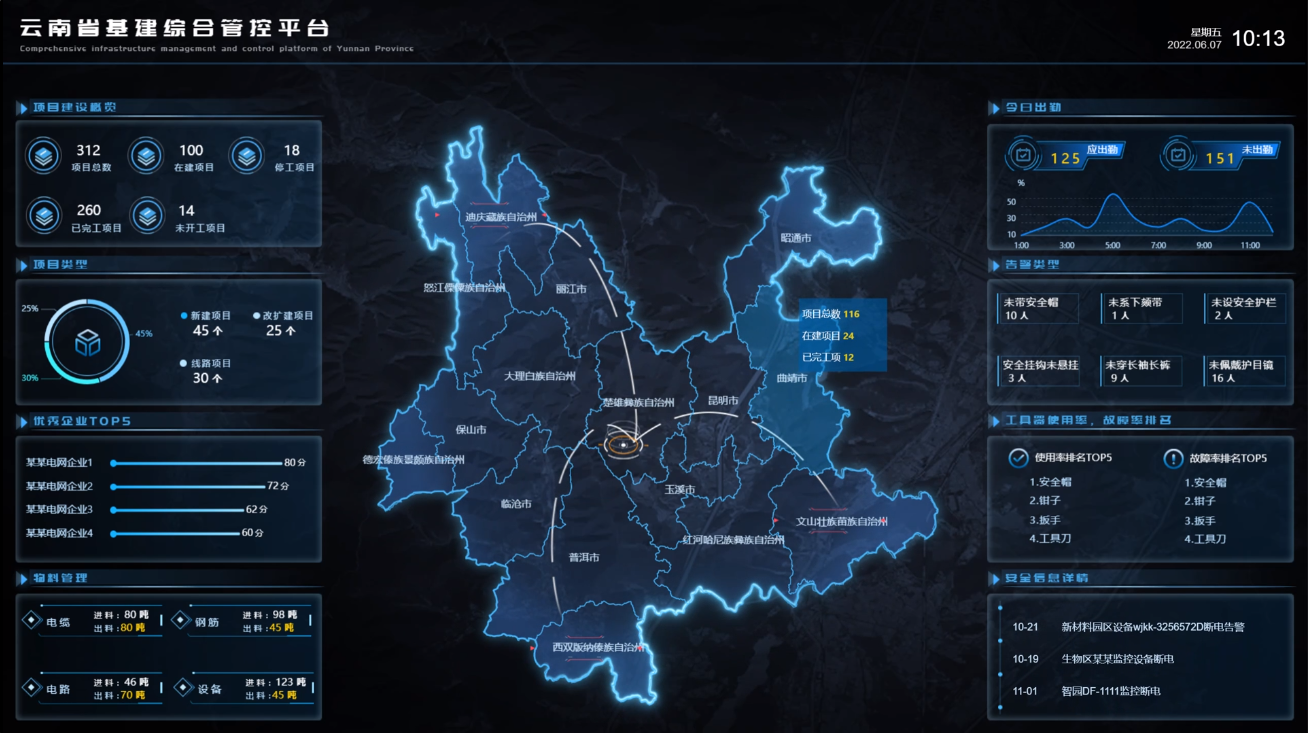
其次,学生关注数据可视化是因为它有助于培养数据分析能力。在信息时代,数据分析已经成为各行各业的重要技能。通过学习数据可视化,学生能够掌握从数据中提炼信息的能力,培养逻辑思维和问题解决能力。这些技能不仅在学业中有所帮助,更是未来职场中的竞争优势。

另外,数据可视化也与现实生活息息相关,促使学生更好地应用所学。通过实际案例的分析和展示,学生能够看到数据可视化在商业、科学、社会等领域的实际应用。这种联系现实的学习方式使学生更容易将理论知识转化为实际能力,更好地适应未来的社会发展需求。

这里惯例推荐一下山海鲸可视化这款数据可视化软件,它的数据可视化相关编辑功能全部可以免费使用,并且没有任何限制,甚至如果你制作的是纯二维项目,那么私有化部署也是完全免费的。那么三维项目呢?尽管三维项目无法像二维项目一样免费部署,但是仍然可以免费编辑制作,只是最终导出后会存在水印。不过与同类产品相比,山海鲸可视化的免费化程度可以说是相当高了。
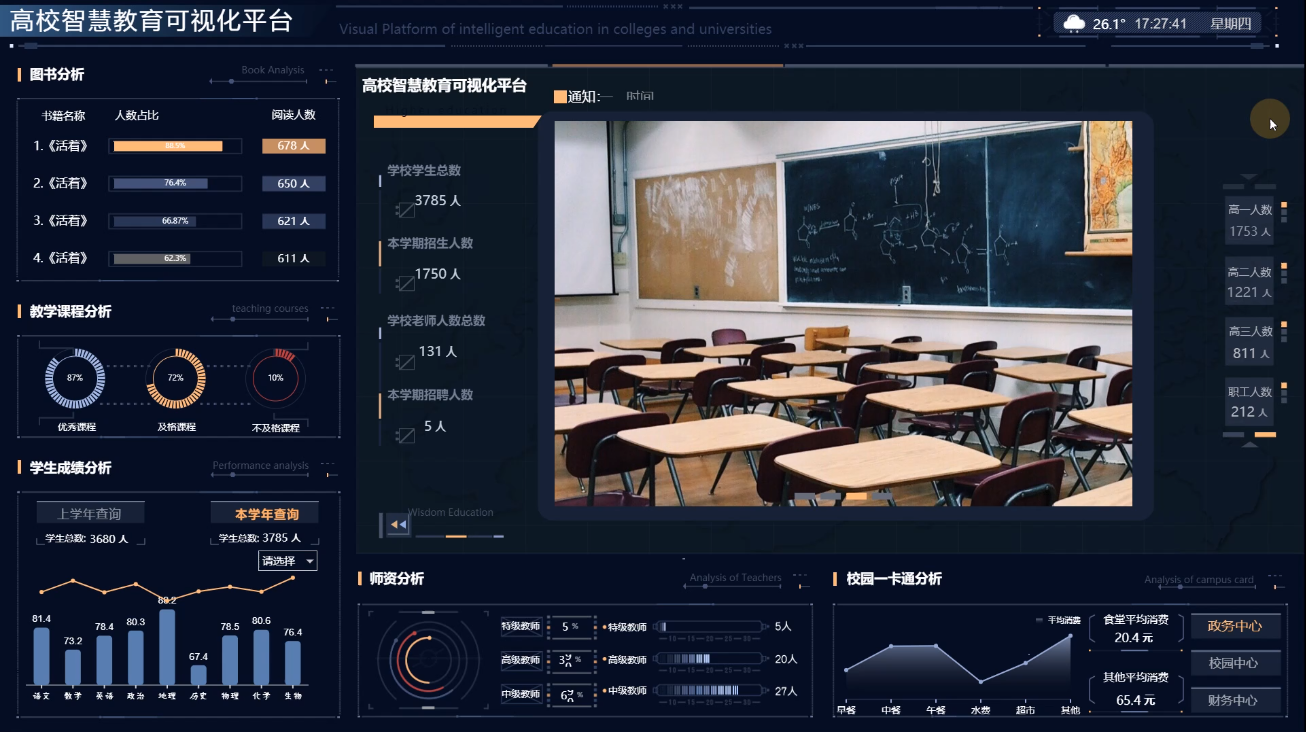
综合而言,学生对数据可视化的关注不仅是对新兴技术的认可,更是对更高效、更有趣学习方式的追求。数据可视化不仅在学术上有着广泛的应用,更在培养学生的综合素养和实际能力方面发挥着重要的作用。这种关注趋势也将为学生未来的学业和职业发展带来更多的机会和挑战。
这篇关于数字化时代的探索:学生为何对数据可视化趋之若鹜?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







