本文主要是介绍【Tessent】Scan and ATPG 【ch2 Scan and ATPG Basics】(4) Multiple Detect(n-detect),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Multiple Detect
- 1. Multiple Detect
- Bridge Coverage Estiamte
- 2. Embedded Multiple Detect
- 3. set_multiple_detection命令
- 3.1 Usage
- 3.2 Description
- 3.3 Arguments
- 3.4 Examples
1. Multiple Detect
多重检测(n-detect)的基本思想是多次随机的以每个故障为目标(target each fault multiple times)。通过改变 the way the fault is targeted 和 测试集中的其他值,检测到桥接故障的的可能性增加。
该方法从一个标准的 stuck-at 或 transition 向量集开始,对每个故障进行分级,以便进行多次检测。然后,执行额外的ATPG,针对低于多重检测目标阈值的故障生成测试向量。
Bridge Coverage Estiamte
桥接覆盖率估计(Bridge coverage estimate,BCE)是用于报告多重检测策略检测到桥接缺陷的能力的度量。
如果目标故障站点和另一个 net 之间存在桥接故障,使用单一向量检测到故障的可能性为50%。如果对同一个故障应用第二个不同的测试向量,则检测到桥接故障的概率为1-0.52。BCE对目标列表中的所有故障执行这种类型的计算,并且总是低于测试覆盖值。
下图给出了启用多重检测或嵌入式多重检测时,工具自动生成的统计报告示例:
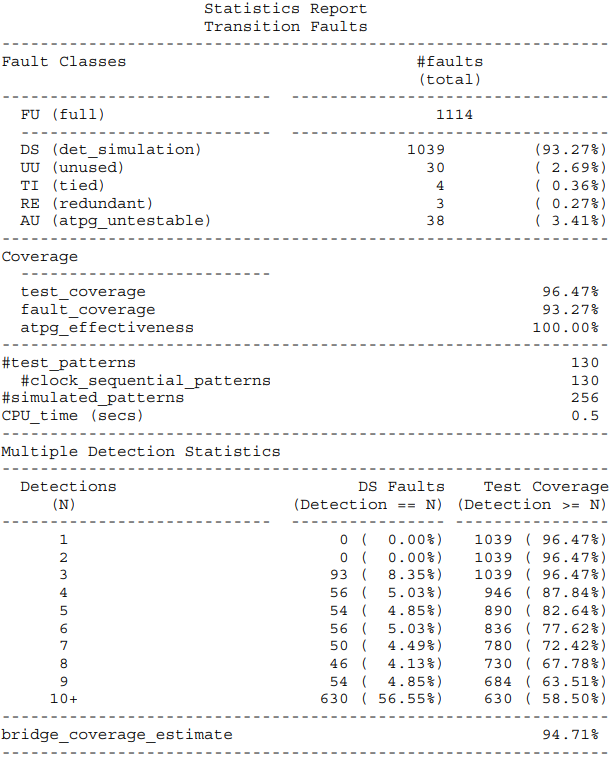
该报告包括BCE值和各种检测小于目标检测值的故障数量。
2. Embedded Multiple Detect
嵌入式多重检测(Embedded multiple detect,EMD)是一种在不增加向量集中向量数量的情况下改进多重检测的方法。本质上,EMD生成与标准向量集相同质量的向量,但增加了改进的多重检测。额外多重检测的唯一成本是在向量创建期间大约增加了30%到50%的运行时间。因此,EMD通常被认为是一种无成本的附加值,并用于ATPG。
当执行ATPG时,工具试图在同一向量下并行检测到尽可能多的先前未检测到的故障。然而,**即使ATPG使每个向量检测到的先前未检测到的故障的数量最大化,也只有一小部分扫描单元具有检测所需的特定值。**该向量中,这些需要加载到扫描单元中的特定bit被称为 “测试立方体(test cube)”。未填充测试立方体值的剩余扫描单元被随机填充,用于fortuitous detection非目标故障。
EMD使用相同的ATPG起点来生成测试立方体,但随后会确定是否存在以前检测次数较少的一些故障。对于这些故障,EMD将额外的扫描单元值添加到测试立方体中,以在新的检测向量之上改进多重检测。
EMD具有比正常ATPG更好的多重检测,但可能没有具有额外向量的 n-detect 所能产生的BCE那么高。在包含EDT电路的设计中,检测量取决于压缩的程度。压缩程度越高,编码容量越低,每个向量可以指定的测试立方体的位数就越少。如果设计的目标是200倍压缩,那么可用的测试立方体的位数可能大部分被许多其他向量填充,用于未检测到的故障。
因此,额外的EMD多重检测的BCE值可能不会显著高于标准向量集合。
标准多重检测具有额外的向量开销,但也具有比EMD更好的多重检测。EMD和多重检测之间的差异取决于特定设计的向量集和使用的压缩级别。
- Multiple Detect for EMD
可以使用set_multiple_delection命令启用EMD或多重检测,工具支 stuck-at 和 transition 向量,可以将以下参数与set_multiple_delection命令一起使用。
-
Guaranteed_atpg_detection —— 将每个故障设置多重检测目标。ATPG尝试针对每个故障进行指定次数的求解。ATPG并不保证它以完全不同的路径检测故障,而是随机改变激活和传播故障的方式。此外,随机填充是不同的,因此目标故障周围的值可能与以前的检测结果随机性的不同。
-
Desired_atpg_detections —— 设定EMD目标,通常将此目标设置为5左右。
-
Simulation_drop_limit —— BCE计算的准确性。通常,不会对其默认值10做出修改。默认值10意味着一旦故障被检测到10次,BCE仿真就会停止。故障的多次检测值设为10,其BEC值或者说,检测到缺陷的统计值为1 - 1/2e10(或0.99902),这样就只有0.0009%的不准确度,是可以忽略不计的。
- Logic BIST
Logic BIST具有自然的具有非常高的多次检测。用LBIST检测到的故障通常具有远高于10的多次检测。这在一定程度上是因为用于逻辑BIST的向量数量通常非常大。此外,电路的许多难以检测的区域是随机测试的,并且在LBIST期间插入测试逻辑更容易产生高的多重检测覆盖率。
- Multiple Detect and AU Faults
在多次检测ATPG期间,AU(ATPG_untestable)故障计数仅在每个ATPG循环的开始处而不是在循环期间改变。这是对ATPG使用NCP(named capture procedures)时的正常行为。该工具在循环结束时通过所有NCP后更新AU故障。
3. set_multiple_detection命令
Context: dft -edt, patterns -scan, patterns -scan_diagnosis
Mode: setup, analysis
Enables the multiple detection of faults.
3.1 Usage

3.2 Description
启用对故障的多重检测。
多重检测是获得桥接故障覆盖率的一种统计方法。默认情况下,该工具生成单一检测的向量集,每个故障被检测一次,然后从仿真中移除。
启用多重检测时,DS故障类别表示检测到一次或多次的故障,而不仅仅是检测到阈值次数的故障。create_patterns命令在对每一批向量的统计中包括一个累积的BCE的计算。使用simulation_drop_limit参数可以提高BCE的精度,同时要意识到提高的准确性需要更长的运行时间。
BCE的计算公式如下:

启用多重检测会更改以下命令的行为:
-
analyze_compression —
-
create_patterns— 根据需要执行多次迭代(循环),以确保每一个可测试故障都被检测到 guaranteed_atpg_detections次,并在仿真的每一批向量的统计中包括累积BCE的计算。对于任何特定故障,每个向量最多只计数一次检测。 -
report_statistics — 报告中列出最终的BCE,还包括一个直方图,显示多重检测 DS 故障的检测次数概况。
-
report_environment — 列出显示当前多重检测设置的“multiple detection =…”行。如果该行不存在,则表示多重检测被禁用。
-
report_faults — 对于每一个 DS 故障,显示“num_detections…”,用以表示故障检测的次数。
-
write_faults — 对于每一个多重检测的 DS 故障,会写一行“num_detections…”,用以表示故障检测的次数。
发出此命令时不带任何参数,以报告当前设置。如果多次发出带有参数的此命令,最后一个命令将覆盖之前的设置。
当故障类型为UDFM时,set_multiple_delection命令仅适用于仿真,而不适用于ATPG。
3.3 Arguments
- -Guaranteed_atpg_detections guaranteed_atpg_detections
一个可选的开关(switch)和整数的组合,用于指定每个可测试故障所需的检测次数。guaranteed_atpg_detections可以是介于1和255之间的任何整数,确定了create_patterns命令在向量生成期间应该针对每个故障的检测次数。在工具将故障从故障列表中删除之前,在故障仿真过程中保证每个故障的指定检测次数。
guaranteed_atpg_detections的默认值是1,增大该值会显著增加向量的数量和ATPG的运行时间。
- -Desired_atpg_detections desired_atpg_detections
一个可选的开关和整数,用于指定每个可测试故障所需的检测次数。这些故障是使用 嵌入式多重检测(EMD)功能检测到的。desired_atpg_detections可以是介于1和255之间的任何整数。
desired_atpg_detections设为1表示不启用EMD。
默认情况下,desired_atpg_detections 的值等于 guaranteed_atpg_detections
desired_atpg_detections 的值不能小于 guaranteed_atpg_detections , 除非不使用EMD功能(此时desired_atpg_ detections 的值为1)
和改变guaranteed_atpg_detections不同的是,增大 desired_atpg_detections的值不会增加向量的数量,但是同样会增加ATPG运行时间。为了获得最佳性能,不建议将desired_atpg_detections设置为大于5。
- -Simulation_drop_limit simulation_drop_limit
一个可选的开关和整数,用于指定故障的最大检测次数。工具在simulation_drop_limit之后从仿真中删除故障。
默认情况下,simulation_drop_limit为1。
当故障类型为UDFM时,可以将simulation_drop_limit设置为任何正整数。
对于所有其他故障类型,simulation_drop_limit不能小于 guaranteed_atpg_detections 或 desired_atpg_detections值。如果未指定值,simulation_drop_limit 将自动设置为以下值之一:
-
guaranteed_atpg_detections = desired_atpg_detections = 1
The simulation_drop_limit is set to 1. -
guaranteed_atpg_detections <= 10 AND 2 <= desired_atpg_detections <= 10
The simulation_drop_limit is set to 10. -
guaranteed_atpg_detections > 10 OR desired_atpg_detections > 10
The simulation_drop_limit is set to the greater of the guaranteed_atpg_detections or desired_atpg_detections values.
- -REPort_incremental_statistics {ON | OFF}
一个可选的开关和文字,使该工具能够在每个多重检测ATPG循环结束时报告增量多重检测测试覆盖率统计信息。默认情况下,该工具不报告此类统计信息。
- OFF
禁用多重检测功能。
3.4 Examples
- 以下示例生成了一个没有使用 EMD 的 3-detection 向量集,其中故障在5次检测后从仿真中删除:
set_multiple_detection -guaranteed_atpg_detections 3 -desired_atpg_detections 1 -simulation_drop_limit 5
- 以下示例生成一个向量集,满足每个可测试故障必须检测两次,并且应该被检测至少8次:
(The following example generates a pattern set where each testable fault must be detected twice
and should be detected at least 8 times:)
set_multiple_detection -guaranteed_atpg_detections 2 -desired_atpg_detections 8
此时 Simulation_drop_limit 被自动设为10。
(结合该示例,以及这两个参数的名字来看,guaranteed_atpg_detections 应该是必须满足的检测次数,而desired_atpg_detections 是可以不满足的,是期望达到的检测次数。)
- 以下示例禁用故障的多重检测:
set_multiple_detection off
这篇关于【Tessent】Scan and ATPG 【ch2 Scan and ATPG Basics】(4) Multiple Detect(n-detect)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





