本文主要是介绍Python - Wave2lip 环境配置与 Wave2lip x GFP-GAN 实战 [超详细!],希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

一.引言
前面介绍了 GFP-GAN 的原理与应用,其用于优化图像画质。本文关注另外一个相关的项目 Wave2lip,其可以通过人物视频与自定义音频进行适配,改变视频中人物的嘴型与音频对应。

二.Wave2Lip 简介
Wave2lip 研究 lip-syncing 以达到视频匹配目标语音片段的目的。目前的作品擅长在训练阶段看到的特定人的静态图像或视频。然而,它们无法准确地改变动态、无约束的谈话面部视频中的任意身份。通过学习强大的唇同步鉴别器来解决它们。接下来,我们提出了新的、严格的评估基准以及在无约束视频中精确测量嘴唇同步的度量。对我们具有挑战性的基准进行了广泛的定量评估,结果表明视频的唇同步准确性几乎和真正同步的一样好。
论文地址: https://arxiv.org/pdf/2008.10010.pdf
1.Wave2Lip 训练数据

训练中用到了LRS2 数据集,该数据集由英国广播公司电视台的数千句口语组成。每句话的长度不超过100个字符。训练、验证和测试集根据广播日期进行划分。数据集统计数据如下表所示。
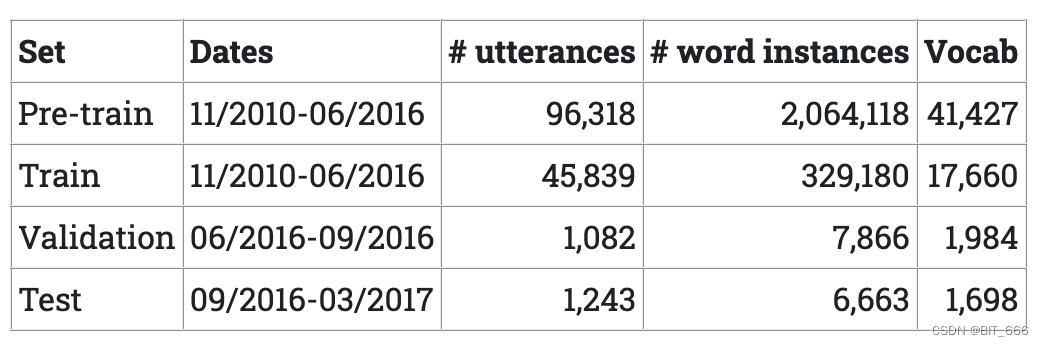
预训练集中的话语对应于部分句子和多个句子,而训练集仅由单个完整句子或短语组成。预训练和训练之间有一些重叠。
2.Wave2Lip 训练目标

wav2lip 模型的训练由生成器和判别器共同组成。GAN 负责学习音频-图像之间的对应关系,生成同步的嘴唇动作。判别器负责评估图像-音频的同步性。具体的,音频会被处理为音频 chunk 并处理转换为梅尔频谱矩阵,该矩阵常用于信号处理中的音频频谱特征;视频则是会逐帧抽取,转化为 [Channel、width、height] 的多通道矩阵。通过训练频谱矩阵与图像多通道矩阵的对应关系,学习chunk 与视频帧中口型的对应关系,不断地反馈训练以优化视频与音频的同步效果。
3.Wave2Lip 模型推理
wave2lip 实战中大致遵循下述流程,下述流程扩展为整个视频图像帧,即可实现视频与音频的嘴型对应:
◆ 解析视频文件
这里一般最常用的格式即为 mp4,通过 cv2 库的 VideoCapture 解析视频文件,并通过 video_stream 流式读取视频的每一帧,更简单的,你的视频可以是一张人物的 Face 图,这样会将图像复制扩展为与音频匹配的帧数。
◆ 音频文件解析
使用 audio 库处理音频文件,为了统一,这里会使用 ffmepg 将音频文件统一转换为 wav 格式。随后通过 melspectrogram 方法获取 wav 音频的梅尔频谱矩阵并将矩阵转换为多个 chunk。
◆ 人脸识别模块
针对视频帧识别人脸位置对应的 coord 坐标,因此 Wave2lip 实现中还需要一个 face-detect 的模型,用于对每一帧图像中人脸进行定位。
◆ GAN 生成
基于上面的人脸的图像通道数字矩阵与音频的 mel 频谱矩阵构造模型的输入,通过调用 GAN 模型生成对应音频的嘴型图像。
◆ 图像拼接与重建
将预测得到的 pred 和 coord 坐标结合,替换原图中的人脸部分,实现人脸与嘴型的替换。

三.Wave2lip 环境搭建
代码实现: https://github.com/Rudrabha/Wav2Lip
1.Package 安装
◆ python 3.6
conda create -n wave2lip python=3.6
conda activate wave2lip◆ ffmpeg
ffmpeg 主要用于音频文件转换为 wav 格式
sudo apt-get install ffmpeg◆ requirements
下载 Wave2lip 对应的 github 项目,安装对应的依赖:
librosa==0.7.0
numpy==1.17.1
opencv-contrib-python>=4.2.0.34
opencv-python==4.1.0.25
torch==1.1.0
torchvision==0.3.0
tqdm==4.45.0
numba==0.48pip install -r requirements.txt◆ face detection model
模型下载地址: 预训练模型
备用下载地址: 备用节点下载
下载好的 .pth 模型需要放置到项目对应的 face_detection/detection/sfd/s3fd.pth 路径下:

2.模型 weights 下载
Wave2lip: Highly accurate lip-sync
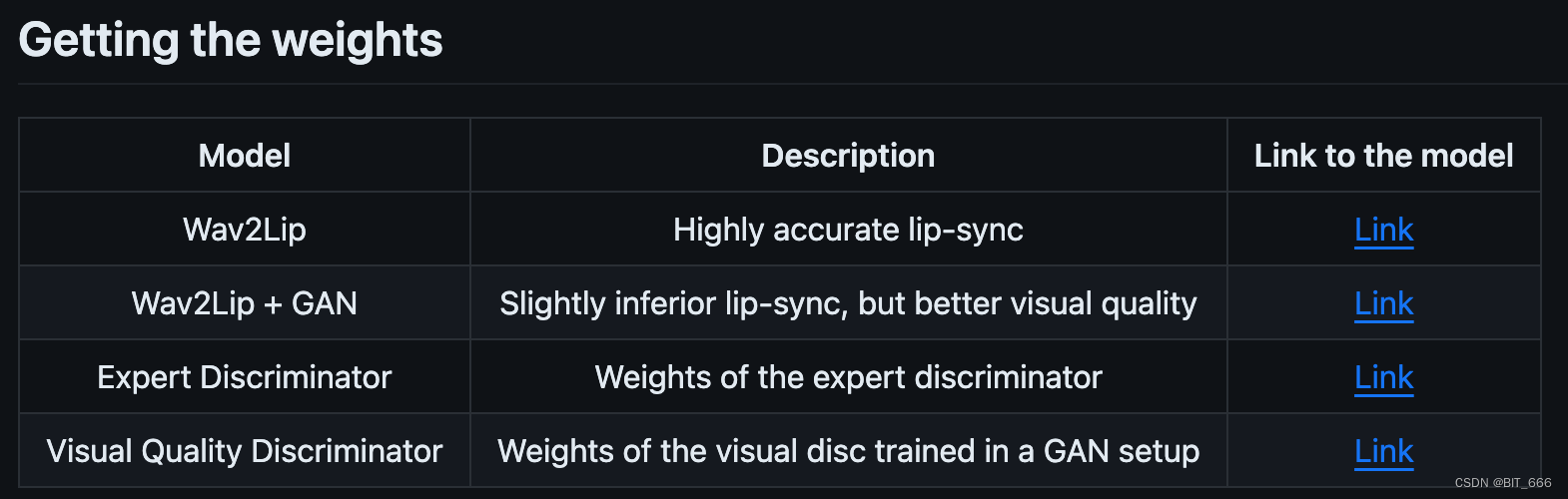
README 中给出了 4 个模型 weights,大小在 50M - 500M 之间,其有各自不同的擅长,有的擅长口型对应,有的擅长图像质量。不过博主测试只有第一个模型可以跑通,其他模型跑通的同学也欢迎在评论区一起交流。
四.Wave2lip X GFP-GAN 实战
1.参数配置
python inference.py --checkpoint_path <ckpt> --face <video.mp4> --audio <an-audio-source>
-- checkpoint_path 模型地址
-- face 要修改的视频,也可以是静态图
-- audio 要适配的音频
其他参数:
-- pads 调整检测到的面部边界框。通常会带来更好的结果。
-- nosmooth 如果嘴巴位置错位或有伪影,可能是过度平滑了人脸检测,加入该参数重试。
-- resize_factor 修改缩放参数以获得较低分辨率的视频。因为原模型是在低分辨率人脸数据上训练的,因此 720p 视频可能比 1080p 视频获得更好更逼真的效果。
还有一些参数可以参考 inference.py 的 args parse 模块,这里有完整的参数解析。
2.Wave2lip 运行
为了方便,我们将官方给的示例调整一下:
#!/bin/bashckpt='/data2/wav2lip/checkpoints/wav2lip.pth'
video='/data2/wav2lip/video/zgl.jpg'
audio='/data2/wav2lip/mp3/AutumnWillNotComeBack.mp3'python inference.py --checkpoint_path $ckpt --face $video --audio $audio◆ 视频选择
为了简化流程,我们使用单一人物图像的 jpeg,当然上传人物的 video.mp4 也可以,但是需要保证每一帧都可以获取 face-detect 的结果,否则程序会异常报错。

◆ 音频选择
AutumnWillNotComeBack.mp3,相信 90 后的你一定不会陌生,没错这就是 《秋天不回来》!
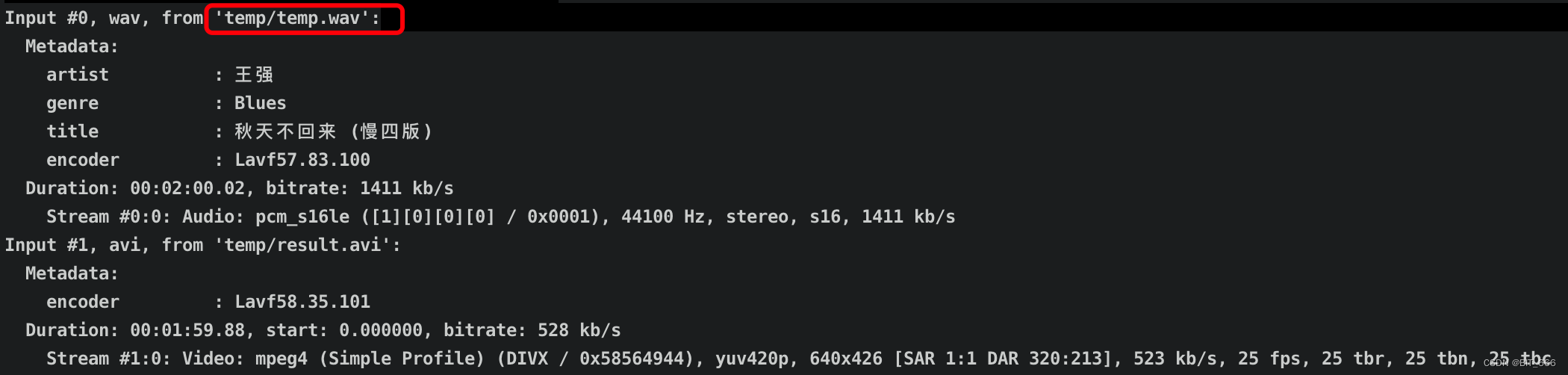
运行命令后会显示音频的相关信息,可以看到原始的 mp4 格式已经处理为 wav,处理命令为:
command = 'ffmpeg -y -i {} -i {} -strict -2 -q:v 1 {}'.format(args.audio, 'temp/result.avi', args.outfile)
subprocess.call(command, shell=platform.system() != 'Windows')◆ 输出结果
输出会通过 cv2.VideoWriter 写入对应的 output 目录,下面为生成视频的相关信息:
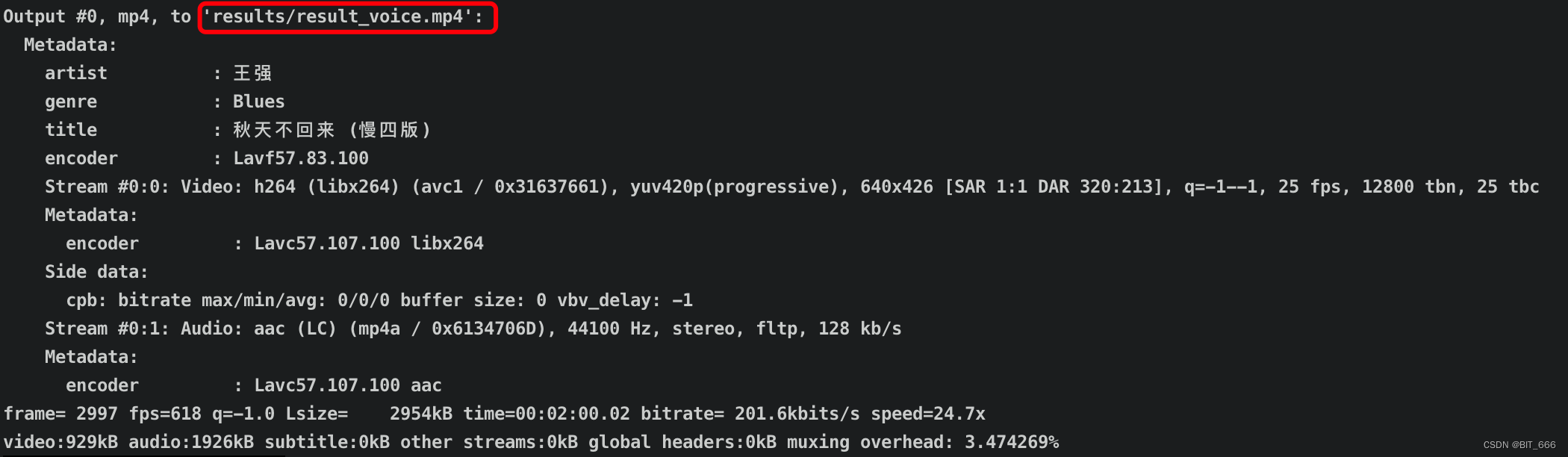
Wave2lip Test
结合前面的介绍的 Nginx 服务,我们可以直接在本机查看服务器上生成的视频,非常的方便。

Nginx 服务搭建: Nginx - 本机读取服务器图像、视频
3.GFP-GAN 修复
由于我们原图的画质较低,导致后续生成的视频也比较模糊。最简单的优化方案是在原始图片、视频的选择上选取更加清晰的版本。不过即便如此嘴部动作也会有一些模型和重影,下面我们基于 GFP-GAN 对视频进行清晰度重建。
◆ Video2PNG
通过 VideoFileClip 库处理视频,共获取 FPS x Duration/s 帧图像。
def video_to_png(_file_name, _output):from moviepy.editor import VideoFileClip# Load your gifclip = VideoFileClip(_file_name)print(f'Duration: {clip.duration} FPS: {clip.fps}')# Loop over clip framesfor i, frame in enumerate(clip.iter_frames()):from PIL import Imageimg = Image.fromarray(frame)img.save(f'{_output}/frame_{i}.png')◆ GFP-GAN ReBuild
GFP-GAN 服务搭建: Python - GFPGAN + MoviePy 提高人物视频画质
python inference_gfpgan.py -i inputs/gif_imgs -o results -v 1.3 -s 2
原视频 FPS = 25,共 2 min = 120 s,所以修复后生成 3k 帧图像。
◆ PNG2Video
将上述 3000 帧图像的地址构造生成 image_files 并生成 ImageSequenceClip 对象,通过 set_audio 的方法匹配 Wave2lip 生成视频的 Audio,最终 write_videofile 输出 mp4。
def png_to_mp4(_file_name, input):# Load your gifclip = VideoFileClip(_file_name)print(f'Duration: {clip.duration} FPS: {clip.fps}')# Loop over clip framesimage_files = get_images(_file_name, input)new_clip = ImageSequenceClip(image_files, fps=clip.fps)# 设置音频剪辑到图像序列剪辑image_sequence = new_clip.set_audio(clip.audio)# 导出最终视频image_sequence.write_videofile('output_video.mp4', codec='libx264', audio_codec='aac', fps=clip.fps)可以看到修复后的视频,人物的脸部和嘴部轮廓形状也更加清晰:
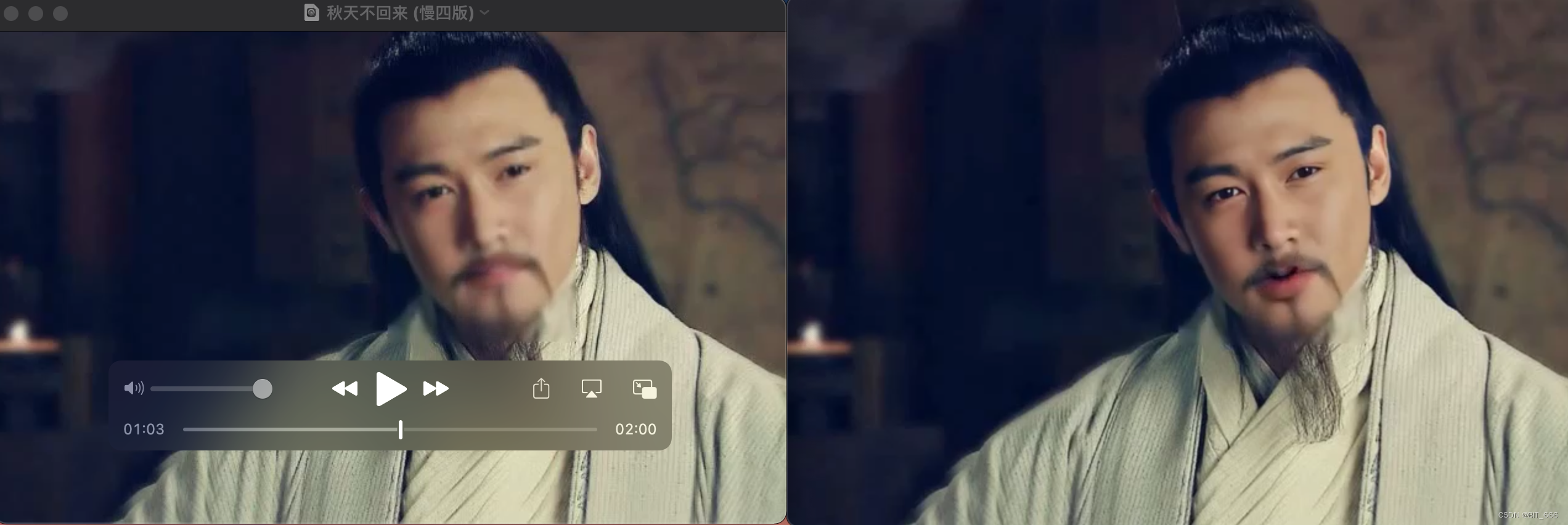
五.总结
通过上面一系列的操作,我们最终实现了 Wave2lip x GFP-GAN 的操作。不过 2min 的视频里,人物的嘴型还是有飘忽不定和重影的问题,一方面可能是由于原图、视频的画质质量过低导致;其次古装人物的胡须与训练集中欧美人的脸部造型差异可能也是原因之一,后续博主也会按 Github 给出的建议,添加 --nosmooth 参数看看是否有好转。有问题欢迎大家评论区交流讨论 ~ 👍
Tips:
Wave2lip 和 GFP-GAN 对应两套 conda 的 python 环境,部署时需要区分。
这篇关于Python - Wave2lip 环境配置与 Wave2lip x GFP-GAN 实战 [超详细!]的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







