本文主要是介绍基于Python的新能源汽车销量分析与预测系统,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
温馨提示:文末有 CSDN 平台官方提供的学长 QQ 名片 :)
1. 项目简介
基于Python的新能源汽车销量分析与预测系统是一个使用Python编程语言和Flask框架开发的系统。它可以帮助用户分析和预测新能源汽车的销量情况。该系统使用了关系数据库进行数据存储,并使用了一些前端技术如HTML、JavaScript、jQuery、Bootstrap和Echarts框架来实现用户界面的设计和交互。
该系统的主要功能包括:
- 数据采集和清洗:通过网络爬虫采集新能源汽车销售数据,并对数据进行清洗、数据库存储,以便后续分析使用。
- 数据可视化:将清洗后的数据以图表的形式展示,如折线图、柱状图等,帮助用户直观地了解销量情况和趋势。
- 数据分析:通过统计学和机器学习算法对销售数据进行分析,提取关键特征和规律,帮助用户发现影响销量的因素。
- 销量预测:基于历史销售数据和分析结果,采用ARIMA差分自回归移动平均算法、决策树回归和Ridge岭回归等预测模型对未来销量进行预测,帮助用户做出决策和制定销售策略。
通过该系统,用户可以方便地进行新能源汽车销量分析和预测,从而更好地了解市场需求和制定销售策略。
2. 新能源汽车销量数据采集
本系统利用Python网络爬虫技术采集某汽车排行榜网站的历史月度销售数据:
ef factory_car_sell_count_spider():"""新能源汽车销量"""# ......# 查询数据库中最新数据的日期query_sql = "select year_month from car_info order by year_month desc limit 1"cursor.execute(query_sql)results = cursor.fetchall()if len(results) == 0:start_year_month = '201506'else:start_year_month = results[0][0]print("start_year_month:", start_year_month)base_url = 'https://xxx.xxxxx.com/ev-{}-{}-{}.html'# ......while start_year_month < cur_date:for page_i in range(1, 10):try:url = base_url.format(start_year_month, start_year_month, page_i)resp = requests.get(url, headers=headers)resp.encoding = 'utf8'soup = BeautifulSoup(resp.text, 'lxml')table = soup.select('table.xl-table-def')trs = table[0].find_all('tr')# 过滤表头for tr in trs[1:]:tds = tr.find_all('td')# 车型car_name = tds[1].text.strip()# 销量# ......factory = tds[3].text.strip()# 售价price = tds[4].text.strip()car_info = (start_year_month, car_name, factory, sell_count, price)print(car_info)factory_month_sell_counts.append(car_info)except:breaktime.sleep(1)# 下个月份start_year_month = datetime.strptime(start_year_month, '%Y%m')start_year_month = start_year_month + relativedelta(months=1)start_year_month = start_year_month.strftime('%Y%m')# 采集的数据存储到数据库中# ......
3. 新能源汽车销量分析与预测系统
3.1 系统首页与注册登录

3.2 中国汽车总体销量走势分析
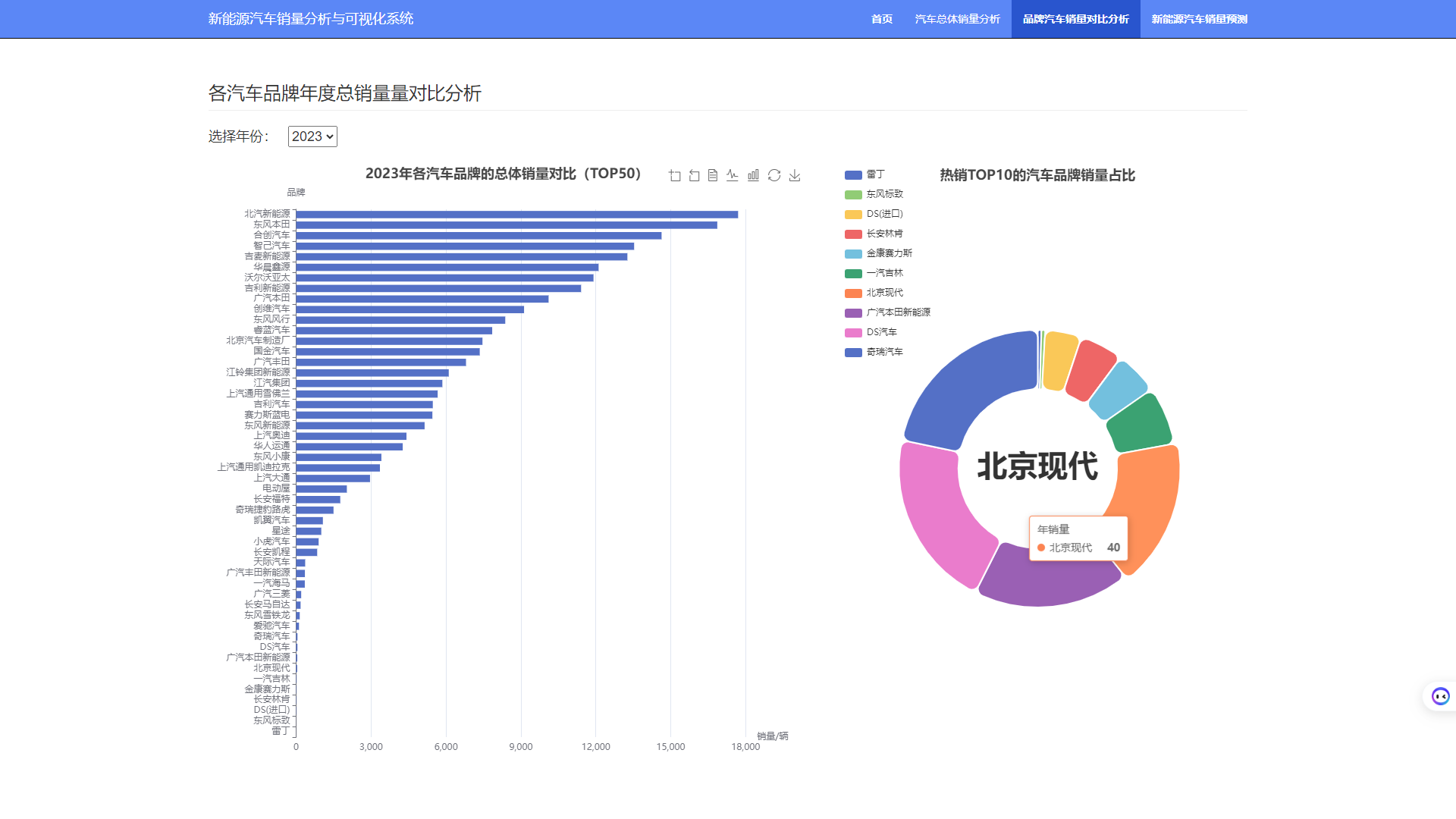
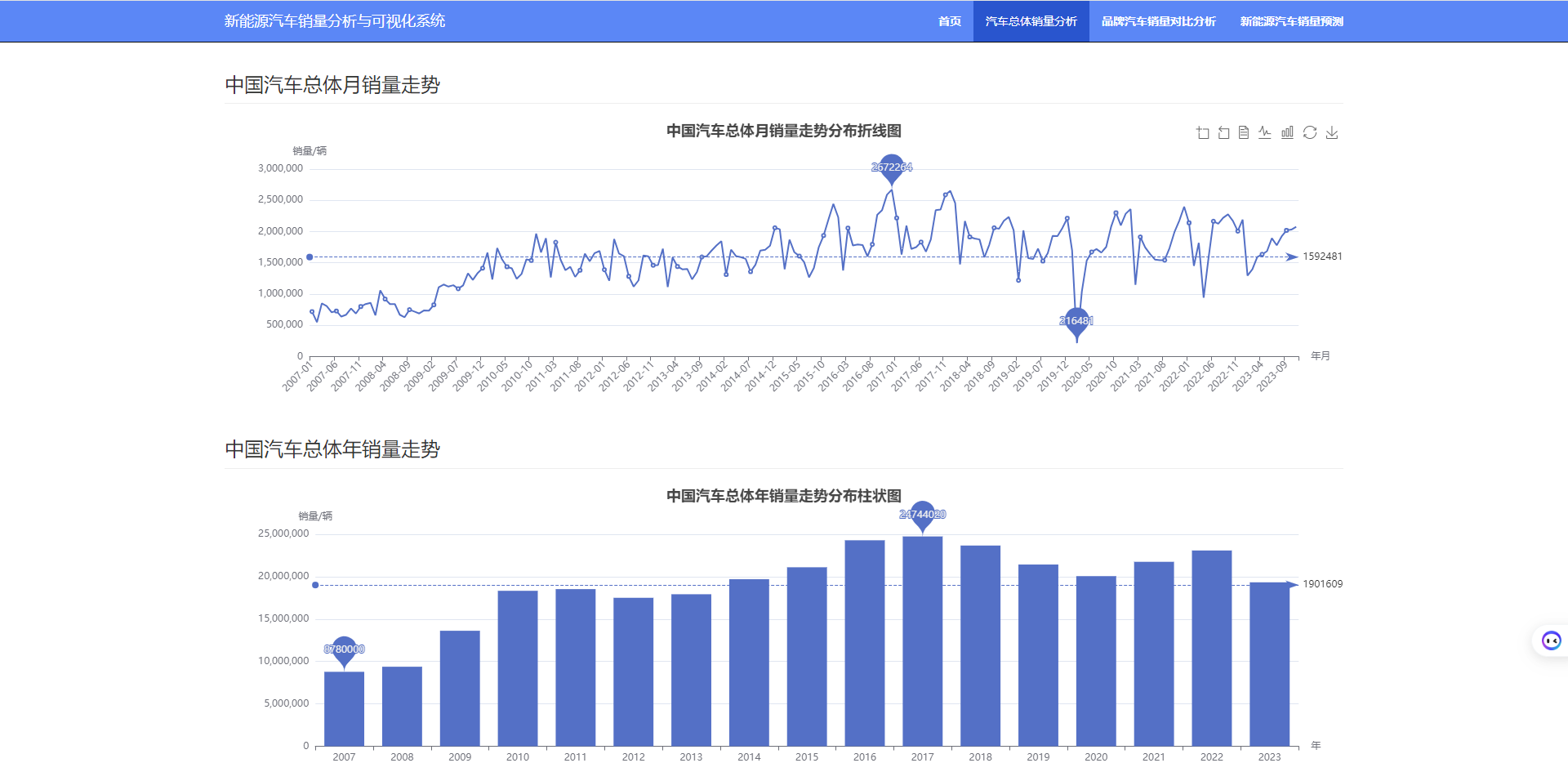 3.3 不同品牌汽车销量对比分析
3.3 不同品牌汽车销量对比分析
3.4 基于机器学习回归算法的汽车销量分析
分别利用ARIMA差分自回归移动平均算法、决策树回归和Ridge岭回归等预测模型,对2015年~2023年所有新能源汽车月度销量数据就行建模训练,并预测最新下一个月度的销量:
@api_blueprint.route('/factory_month_year_sell_count_predict/<factory>/<algo>')
def factory_month_year_sell_count_predict(factory, algo):"""汽车销量预测"""tmp = factory_month_sell_counts[factory_month_sell_counts['厂商'] == factory]tmp = tmp.drop_duplicates(subset=['时间'], keep='first')year_months = tmp['时间'].values.tolist()sell_counts = tmp['销量'].values.tolist()# 销量预测算法predict_sell_count = 0if algo == "arima":predict_sell_count = arima_model_train_eval(sell_counts)elif algo == 'tree':predict_sell_count = decision_tree_predict(sell_counts)elif algo == 'ridge':predict_sell_count = ridge_predict(sell_counts)else:raise ValueError(algo + " not supported.")# 下一个月度next_year_month = datetime.strptime(year_months[-1], '%Y%m')next_year_month = next_year_month + relativedelta(months=1)next_year_month = next_year_month.strftime('%Y%m')year_months.append(next_year_month)# 转为 int 类型predict_sell_count = int(predict_sell_count)sell_counts.append(predict_sell_count)return jsonify({'x': year_months,'y1': sell_counts,'predict_sell_count': predict_sell_count})

切换为柱状图可视化,红色为预测的下一个月度的销量:

4. 总结
本项目通过网络爬虫采集新能源汽车销售数据,并对数据进行清洗、数据库存储,以便后续分析使用。将清洗后的数据以图表的形式展示,如折线图、柱状图等,帮助用户直观地了解销量情况和趋势。通过统计学和机器学习算法对销售数据进行分析,提取关键特征和规律,帮助用户发现影响销量的因素。基于历史销售数据和分析结果,采用ARIMA差分自回归移动平均算法、决策树回归和Ridge岭回归等预测模型对未来销量进行预测,帮助用户做出决策和制定销售策略。
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。技术交流、源码获取认准下方 CSDN 官方提供的学长 QQ 名片 :)
精彩专栏推荐订阅:
1. Python 毕设精品实战案例
2. 自然语言处理 NLP 精品实战案例
3. 计算机视觉 CV 精品实战案例

这篇关于基于Python的新能源汽车销量分析与预测系统的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




