本文主要是介绍使用仪表板轻松搞定数据趋势图,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
什么是仪表板
仪表板是不同小组件(Widget)或者输入控件(Input)的集合,它们一起工作从多个角度告诉用户与数据趋势图有关的情况。
根据您想要仪表板显示的内容或工作方式,您可以添加不同小部件,例如关键绩效指标、图表、表格、筛选器等等。
为什么需要仪表板
●仪表板的用途之一是为受众提供重点。数据集可包含大量数据。一些数据与受众具有的特定问题相关;一些数据是不相干的噪音。有时,对一组问题而言至关重要的数据可能相对于其他一组问题而言就是干扰。
●仪表板并不仅仅告诉我们有什么变化;它还邀请我们去深入挖掘基础数据。
在鸿鹄中如何使用仪表板
在鸿鹄中,创建并使用仪表板有以下2种方式:
●当您在查询页面查询完毕,并绘制出想要的图表效果后,您可以将这个图表以小组件(Widget)的形式保存到一个已有的仪表板中,也可以在选择仪表版的控件中选择新建一个仪表板,并将图表保存成小组件
●您也可以打开仪表板列表,单击右上方的新建仪表板。在您输入仪表板标题、描述,并确认之后,您就新建了一个仪表板。
在列表中找到它,并单击标题打开后,单击页面右上角的编辑按钮,您就能进入编辑模式(Edit Mode)。在编辑模式种,您能新建/编辑/删除小组件,也能拖拽各小组件重新进行布局。
仪表板输入(Input)和标记(Token)
在开发仪表板的过程中,我们通常会将一些相似的数据分析案例做成一个仪表板,希望用户根据不同的情况进行分析。而这不同的情况,就需要用户提供不同输入,为此我们的也在仪表板中提供了不同的输入组件(Input)来方便用户提供不同情况的输入。
在进入仪表板的编辑模式后(在仪表板页面,点击页面右上方的编辑按钮),用户可以添加输入。现在鸿鹄系统支持的输入类型有:
●文本输入
●选择器输入
●时间类型输入
而在添加输入的过程中,我们会要求用户指定一个标记(Token),意味着添加输入之后,用户的输入将会被赋值到这个标记中,而之后这个标记将在整个仪表板的上下文中使用。
文本输入
文本输入的概念很简单,在指定标记名称(Token Name)等必要信息之后,用户就能在仪表板中成功添加一个文本输入,其表现形式为一个文本输入框。而用户之后在文本框中输入的任意值将被赋值到对应的标记中。

文本框输入
值得注意的是,文本框输入需要用户按下回车键(Enter)才会完成标记的赋值,并触发这个标记影响到的小组件进行刷新
选择器输入
与文本输入的形式类似,只是在创建过程中选择输入类型为选择器
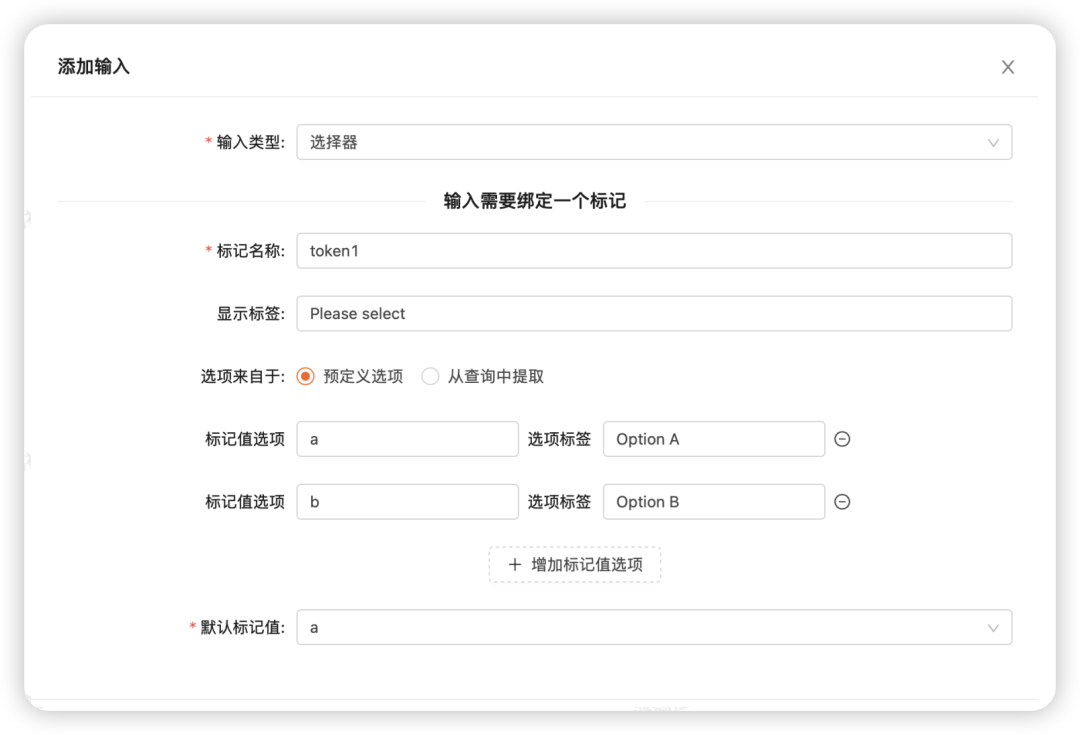
选择器输入:预定义选项
可以看到,选择器的选项来源有预定义选项和从查询中提取2种:
●预定义选项:用户可以点击增加标记值选项,自己手动填入对应的选项值和选项标签
●从查询中提取:用户可以输入一个查询,然后从查询结果集中选取一列A作为标记值,选取一列B作为选项标签,如下图所示
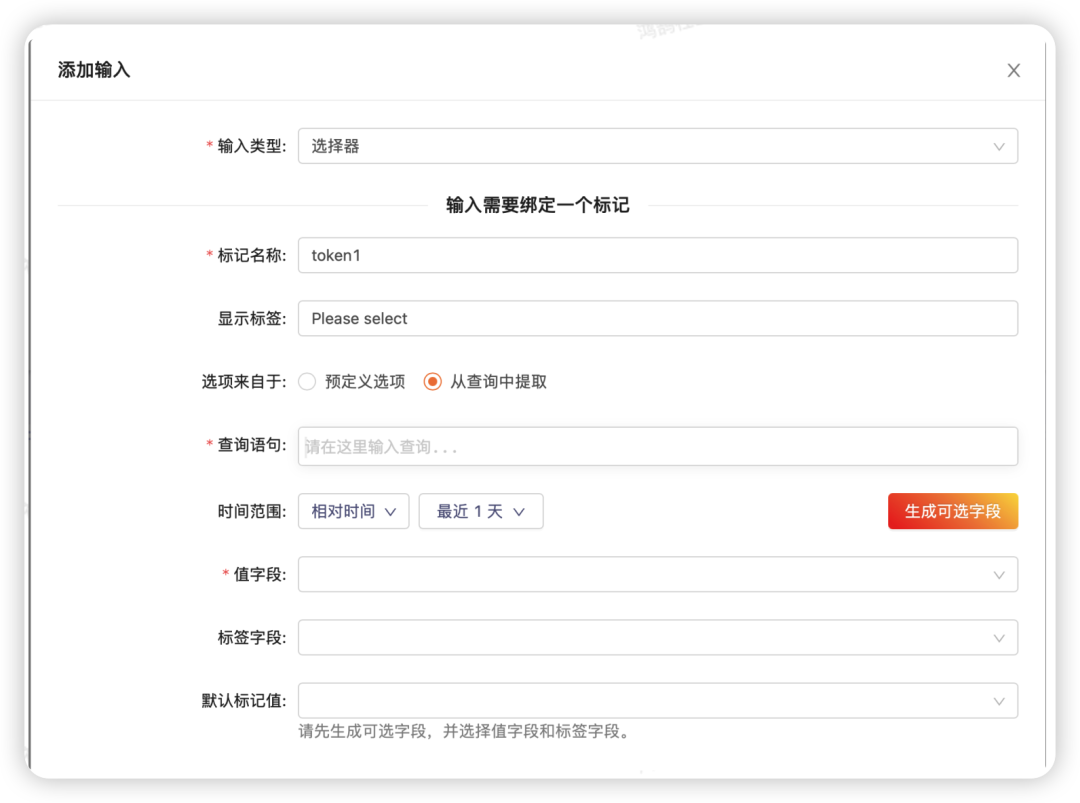
选择器输入:从查询中提取选项
需要注意:需要点击生成可选字段的按钮,来运行所填入的查询语句,才能生成结果集,用户才能选择。
时间输入
时间输入是一个特殊的输入类型,他能将时间范围类型,起始时间,结束时间合并成一个token,输入的表现形式将是一个时间选择框,如图所示:
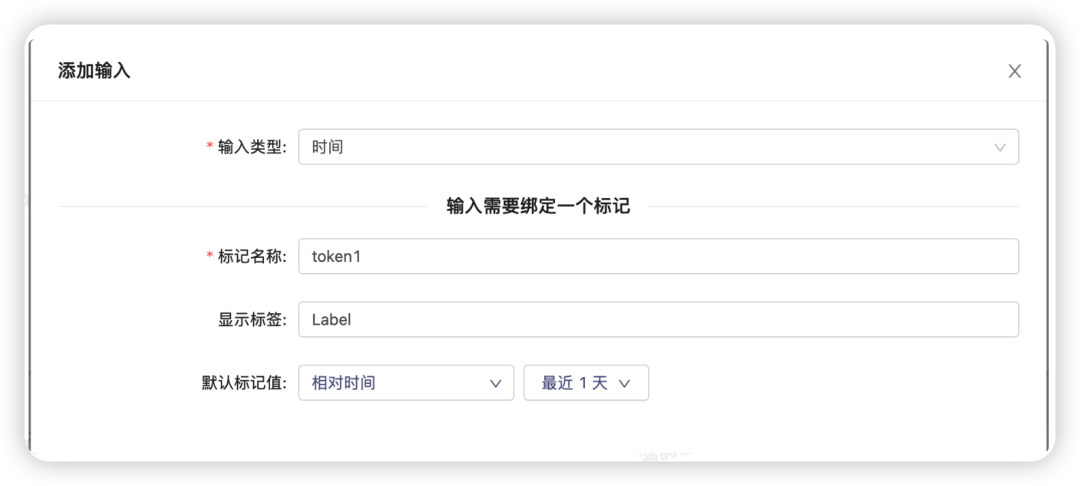
时间输入
标记的使用
文本输入和选择器输入对应的标记的使用是类似的,在你需要使用的地方输入$tokenName$就能使用这个标记。例如:你的文本选择器对应的标记叫做tokenA你需要在SQL中使用,作为一个过滤条件,则你可以在SQL中这样写:

而时间标记值的使用,通常都在编辑小组件(Widget)的查询的时候,你可以在时间范围中选择时间标记值,如图所示
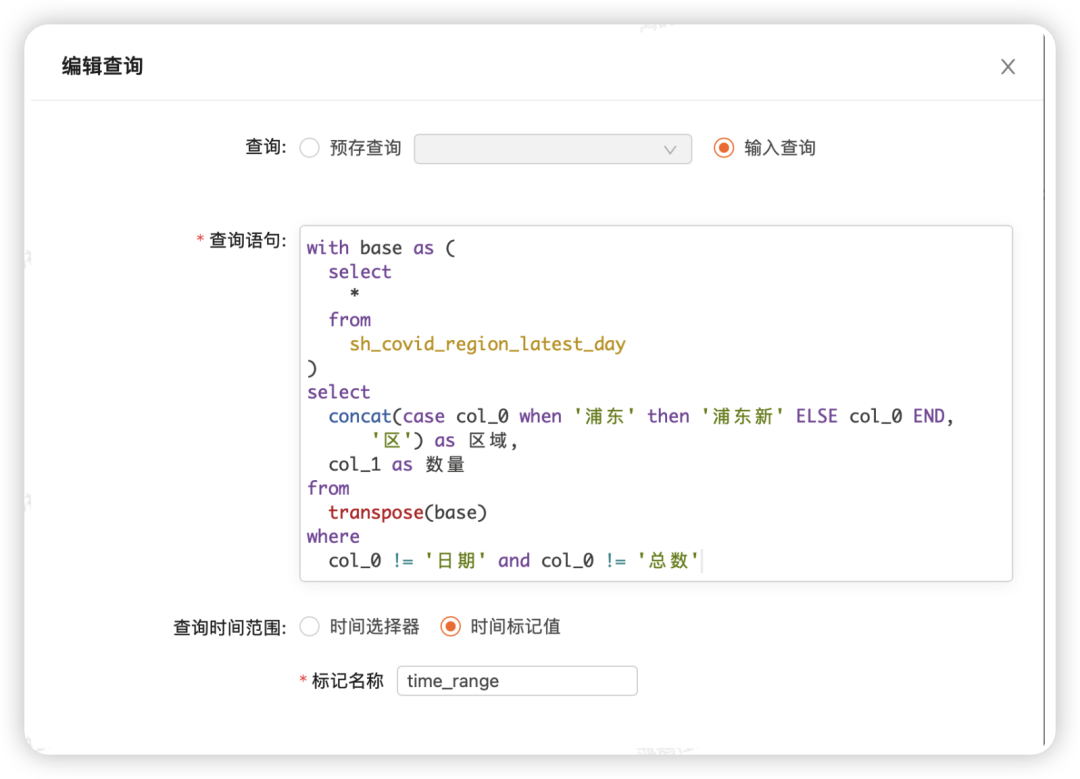
时间标记值的使用
仪表板的布局方式
鸿鹄的仪表板有2种布局方式
行列布局(即将Deprecate)
在一开始的产品中,我们引入了行列布局。所谓行列布局是将仪表板页面分为多行,而每行可以分为多列。每一列都是一个小组件,或者一个仪表板输入的控件。
由于当初的设计时间和实现时间有限,行列布局有以下一些限制
●行列布局的仪表板中,输入控件(Input)只能放在第一行
●同一行的小组件(Widget) 一定有相同的高度和宽度,宽度根据这一行中有的小组件数量进行等分,例如,一行中有N个小组件,则每个小组件的宽度是页面宽度的N分之一
●在行列布局的仪表板中拖动小组件重新布局,将会使得一部分小组件进行没有必要的刷新
网格布局
随着仪表板用户的增多,以及行列布局日益暴露的限制,为了增强用户在仪表板页面的体验,我们推出了全新的网格布局。
●网格布局将页面横向分为24列,用户可以控制小组件(Widget)或输入控件(Input)的宽度为N列(1≤N≤24)
●网格布局也规定了小组件(Widget)或输入控件(Input)的最小高度: 30px
●网格布局增强了拖拽体验,避免了非必要的组件刷新
●网格布局中可以自由的布局输入控件(Input)
-
如果用户认为这个输入和全局相关,则可以放在仪表板的顶部区域
-
如果用户认为某个输入只和某个小组件(Widget)相关,则可以将小组件和此输入控件相邻放置
仪表板的最佳实践
比较好的布局方式
在今后的版本中,行列布局即将被移除,而网格布局也能跟好的应对客户对于不同布局的需要。所以我们推荐鸿鹄的用户使用网格布局。
仪表板小组件的数量
我们不推荐在同一个仪表板中放置大量的小组件,因为仪表板中的小组件数量越多,用户打开dashboard时候触发的并发查询也越多,而一般来说每个部署中并发查询的数量是有限的,和机器的cpu core数量相关,而剩余的查询将会堆积在队列中。
如果一个拥有大量小组件的仪表板被多个用户经常使用,那么查询队列将很容易阻塞。
我们一般推荐用户在仪表板中放置10个左右的小组件,用以说明一些关联非常紧密的查询结果,建议用户将一些业务逻辑上强烈相关的查询才放置到同一个dashboard中。
活用输入(Input)与标记(Token)
我们推荐将查询逻辑相同,而仅仅是过滤条件不同的查询做成同一个小组件,通过输入(input)和令牌(token)控制这些查询的运行,这样能大大优化仪表板组件个数。
其他参考资料
功能介绍:仪表板的钻取交互
这篇关于使用仪表板轻松搞定数据趋势图的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




