本文主要是介绍错误标注太多,不想人工检查?试试置信学习来自动找错,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
众所周知,在机器学习中,测试集是我们用来衡量模型性能的基准。但是,在实际工作中,我们或许会遇到这样一个问题,那就是不论用何种手段获取到的标注数据,都或多或少存在一些标注错误,这对模型精度的提升是一个不可忽视的问题。
在早前的一篇论文中,麻省理工 CSAIL 和亚马逊的研究者对 10 个主流机器学习数据集展开了研究[1],结果发现平均有3.3%的数据标注错了,ImageNet,CIFAR100等知名数据集的错误率竟接近6%。

图一 主流数据集的错误案例
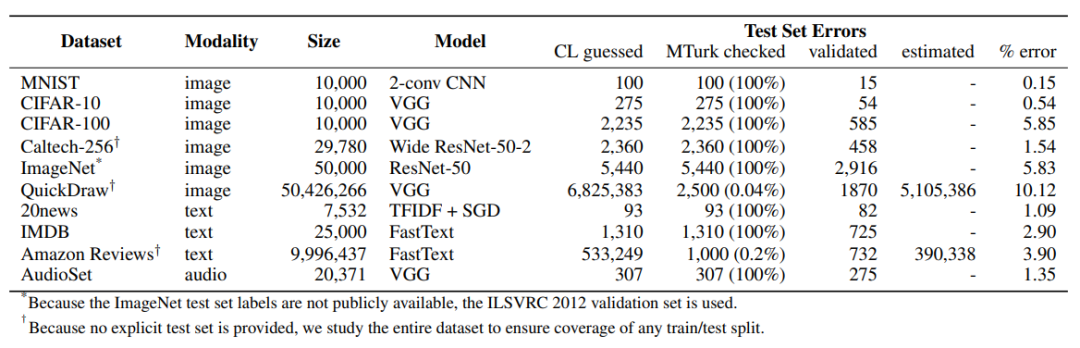
图二 主流数据集的错误情况
因此,如何快速便捷的从数据集中找到错误或者疑似错误的样本,成为一件很重要的事情。
本文介绍了一种采用置信学习的方式来寻找错误样本的方法[2],并选择MNIST数据集进行了实验,介绍了采用置信学习方法来寻找错误样本的主要流程,下面是详细的内容。
一、方法介绍
NO.1
何为置信学习
置信学习的概念来自一篇由MIT和Google联合提出的Paper:Confident Learning: Estimating Uncertainty in Dataset Labels[2] 。论文提出的置信学习(confident learning,CL)是一种新兴的、具有原则性的框架,可用于识别标签错误、表征标签噪声并应用于带噪学习(noisy label learning)。
置信学习具有以下优点:
● 可直接估计噪声标签与真实标签的联合分布,具有理论合理性;
● 不需要超参数,只需使用交叉验证来获得样本的预测概率;
● 不需要做随机均匀的标签噪声的假设(这种假设在实践中通常不现实);
● 与模型无关,可以使用任意模型,不像众多带噪学习与模型和训练过程强耦合;
● 作者开源了置信学习的工具包cleanlab,一行代码调用,方便快捷;
NO.2
置信学习的流程
置信学习包含三个主要步骤:
● Count:估计噪声标签和真实标签的联合分布;
● Clean:根据联合分布找出噪声样本;
● Re-Training:过滤噪声样本后,重新训练;
在Count阶段,首先进行交叉验证(交叉验证的流程如图三所示),得到所有样本的预测概率,然后统计每个人工标定类别的平均概率作为置信度阈值,如公式一所示;
然后计算每个样本的预测类(预测概率最大的那个类,且该概率大于该类的置信度阈值)如公式二所示;
接着统计预测类别和给定类别之间的计数矩阵(类似混淆矩阵),如公式三所示;
最后标定计数矩阵,让计数矩阵的总和与数据总量相同,并进行归一化,得到预测标签和给定标签的联合分布,如公式四所示。
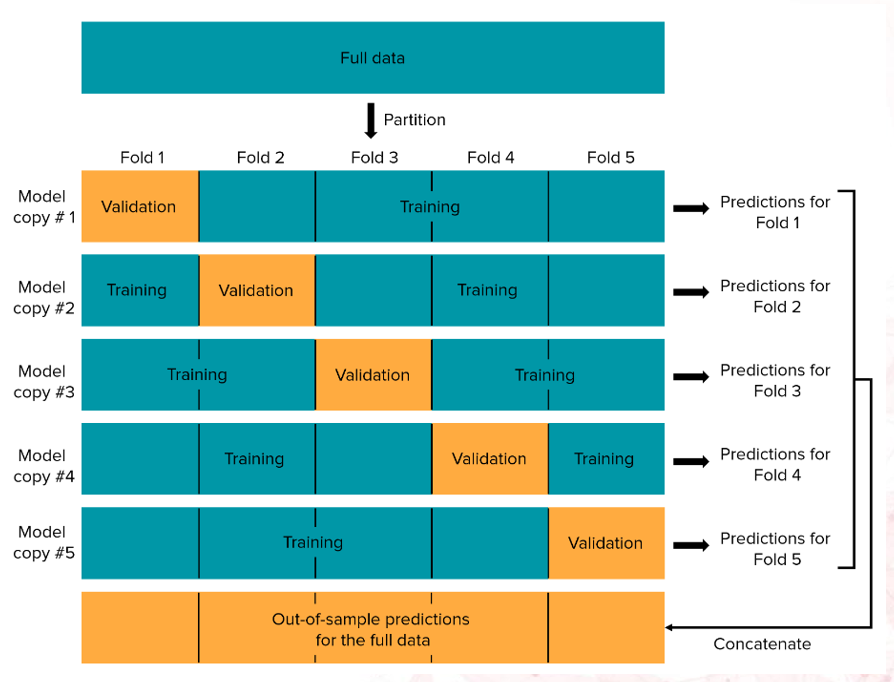
图三 交叉验证示意图
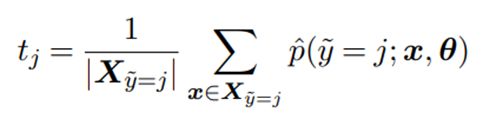
公式一

公式二

公式三
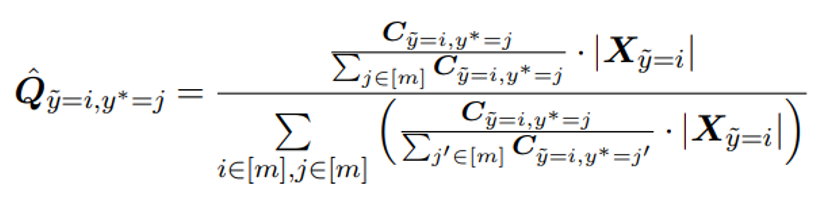
公式四
上述公式中出现的变量含义如下所示:
|
| 判断预测结果是否为j类别的置信度阈值 |
|
| 给定的标签(原始标签,可能带噪声) |
|
| 预测的标签,这里作为真实标签 |
|
| 样本空间 |
|
| 单个样本 |
|
| 预测模型的参数 |
|
| 预测概率 |
|
| 给定标签和预测标签的统计矩阵 |
|
| 给定标签和预测标签的联合分布矩阵 |
在Clean阶段,有5种方法进行噪声标签的筛选:
1. 过滤预测类别和人工标记的类别不一致的数据;
2. 过滤计数矩阵中非对角单元的样本;
3. 对于类别c,选取N*p个样本过滤,其中的N是给定类别为c的样本总数,p是联合分布矩阵中除Q(c,c)之外的概率和;
4. 对于计数矩阵非对角单元,选取N*p个样本过滤,其中N是总样本数,p是联合分布矩阵中计数矩阵的单元对应的概率;
5. 方法3与方法4结合;
其中方法2是作者从理论分析认为比较合理的方法,不过同时作者也进行了实验,5种方法之间的结果差异很小。
把上面的过程用一张图来表示,如图四所示:
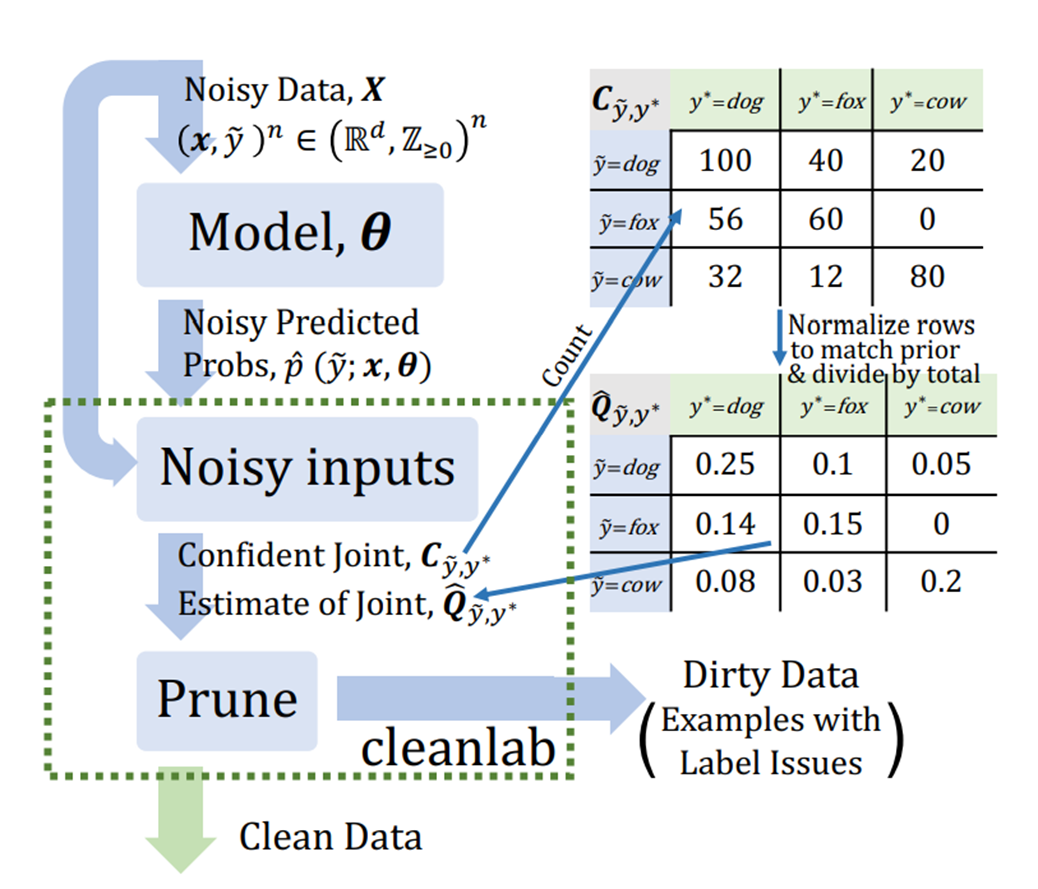
图四 置信学习流程示意图
NO.3
置信学习的效果
论文作者做了大量消融实现来验证置信学习的效果,这里我们只看置信学习在实际数据集中作用,图五是作者在ImageNet(ILSVRC 2012)数据集上进行置信学习所取得的结果:

图五 ILSVRC 2012数据集上置信学习的结果
图五中(a)可见通过置信学习筛选掉噪声标签之后,(对比随机去除样本)精度最多提升了0.6个百分点,对照(b)(c)(d)组实验可以看到,数据集本身包含的错误标签越多,置信学习提升的效果越明显。
二、实际操作
置信学习的作者开源了其代码库cleanlab,只需要一条命令即可安装pip install cleanlab,我们在MNIST上进行了尝试,来介绍置信学习的实际操作过程的详细步骤。代码主要包含以下几个部分:
NO.1
参数定义
import numpy as np
import torch
import warningsSEED = 123
np.random.seed(SEED)
torch.manual_seed(SEED)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
torch.cuda.manual_seed_all(SEED)
warnings.filterwarnings("ignore", "Lazy modules are a new feature.*")NO.2
导入数据集
from sklearn.datasets import fetch_openml
mnist = fetch_openml("mnist_784") # 获取 MNIST 数据集X = mnist.data.astype("float32") # 二维数组
X /= 255.0 # 将图片像素值归一化到0~1
X = X.reshape(len(X), 1, 28, 28) # 改变图片尺寸为 [N, C, H, W] y = mnist.target.astype("int64") # 一维标签
print(X.shape, y.shape)这里打印数据的尺寸如下图所示,其中70000为图片数量,1为通道数(即灰度图片),28*28为图片的分辨率大小:

NO.3
定义分类模型
from torch import nnclass ClassifierModule(nn.Module):def __init__(self):super().__init__()self.cnn = nn.Sequential(nn.Conv2d(1, 6, 3),nn.ReLU(),nn.BatchNorm2d(6),nn.MaxPool2d(kernel_size=2, stride=2),nn.Conv2d(6, 16, 3),nn.ReLU(),nn.BatchNorm2d(16),nn.MaxPool2d(kernel_size=2, stride=2),)self.out = nn.Sequential(nn.Flatten(),nn.Linear(400, 128),nn.ReLU(),nn.Linear(128, 10),nn.Softmax(dim=-1),)def forward(self, X):X = self.cnn(X)X = self.out(X)return Xfrom skorch import NeuralNetClassifier
model_skorch = NeuralNetClassifier(ClassifierModule)由于MNIST数据集相对简单,这里用pytorch定义了一个简单的两层卷积层+两层全连接层的分类网络,并采用skorch进行了包装,以方便后续利用sklearn进行调用。
NO.4
K重交叉验证
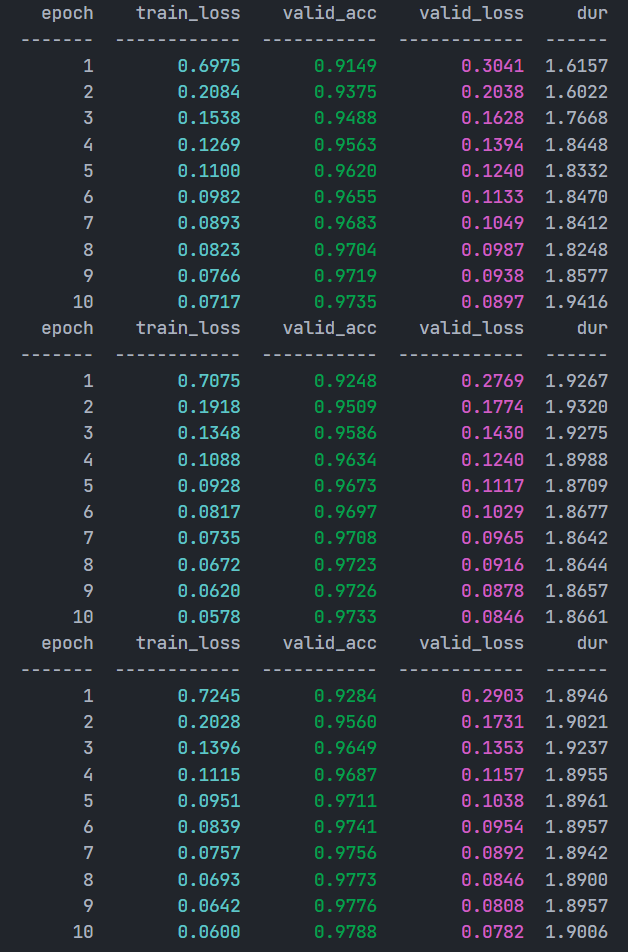
from sklearn.model_selection import cross_val_predictnum_crossval_folds = 3
pred_probs = cross_val_predict(model_skorch,X,y,cv=num_crossval_folds,method="predict_proba",
)这里设置了K=3,交叉训练的结果如下图,其中pred_probs便是后续置信学习所需要的预测概率。
NO.5
交叉训练的整体精度
from sklearn.metrics import accuracy_scorepredicted_labels = pred_probs.argmax(axis=1)
acc = accuracy_score(y, predicted_labels)
print(f"Cross-validated estimate of accuracy on held-out data: {acc}")结果如下:

这个结果将会和去除噪声标签后的结果进行对比。
NO.6
通过cleanlab库寻找噪声标签
from cleanlab.filter import find_label_issuesranked_label_issues = find_label_issues(y,pred_probs,return_indices_ranked_by="self_confidence",
)
#可以通过输入filter_by参数选择筛选方法,默认选择的是方法一,其他一些细节也可以进行调整print(f"Cleanlab found {len(ranked_label_issues)} label issues.")
print(f"Top 15 most likely label errors: \n {ranked_label_issues[:15]}")结果返回了噪声数据的索引列表,这里cleanlab一共找到127个标签错误,其中错误概率排在前15位的错误标签的索引如下所示:

NO.7
对一些结果进行可视化
import matplotlib.pyplot as pltdef plot_examples(id_iter, nrows=1, ncols=1):plt.figure(figsize=(12,8))for count, id in enumerate(id_iter):plt.subplot(nrows, ncols, count + 1)plt.imshow(X[id].reshape(28, 28), cmap="gray")plt.title(f"id: {id} \n label: {y[id]}")plt.axis("off")plt.tight_layout(h_pad=5.0)plot_examples(ranked_label_issues[range(50)], 5, 10)这里展示了前50个有问题的样本,如下所示:

可以看到,其中多半都是确实错误或者有歧义的标签,其他标签也包含了一些书写不规范的情况。
NO.8
去掉噪声标签后re-training
clean_X = np.delete(X, list(ranked_label_issues), 0)
clean_y = np.delete(y, list(ranked_label_issues), 0)
print(clean_X.shape, clean_y.shape)clean_pred_probs = cross_val_predict(model_skorch,clean_X,clean_y,cv=num_crossval_folds,method="predict_proba",
)
clean_predicted_labels = clean_pred_probs.argmax(axis=1)
clean_acc = accuracy_score(clean_y, clean_predicted_labels)
print(f"Cross-validated estimate of accuracy on held-out data: {clean_acc}")去除噪声标签后,数据的尺寸如下图,对比原始数据少了127条数据。

最终的精度如下:

对比前面的精度0.9766,可见精度只有轻微的提升,这是因为MNIST整体70000张图片中去除127条,影响较为轻微,结合论文可以知道MNIST的整体错误率相对较低,如果在面对错误标签较多的数据集时,置信学习应该能有更好的发挥。
NO.9
补充实验
由于上面精度提升不是很明显,考虑到MNIST全部图片有70000张,127张噪声图片的影响较低,所以进行了补充实验,从MNIST数据集中挑选一部分(部分干净数据+127张噪声数据),测试噪声率稍微大一些的数据集上,cleanlab的效果。
● 准备数据集
前面cleanlab找出了127张噪声图片,这里让新数据集的噪声率维持在5%(考虑到找出的127张图片不都是错误图片,实际噪声率应该会低于5%),图片总数应该为127*20张,且其中有127张噪声图片,构造代码如下所示:
import random
small_Num = 127*20
small_clean_index = random.sample(list(range(clean_X.shape[0])), small_Num-len(ranked_label_issues))
#新数据集由127张噪声数据和(2540-127)张干净数据组成
small_X = np.concatenate([clean_X[small_clean_index], X[ranked_label_issues]])
small_y = np.concatenate([clean_y[small_clean_index], y[ranked_label_issues]])#打乱组合后的数据集
random_index = list(range(small_X.shape[0]))
random.shuffle(random_index)
small_X = small_X[random_index]
small_y = small_y[random_index]
print(small_X.shape, small_y.shape)这里得到新的数据集维度如下,数据量降到了2540,其他不变:
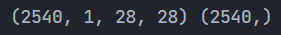
● 交叉验证
model_skorch = NeuralNetClassifier(ClassifierModule)
num_crossval_folds = 3
pred_probs = cross_val_predict(model_skorch,small_X,small_y,cv=num_crossval_folds,method="predict_proba",
)
predicted_labels = pred_probs.argmax(axis=1)
acc = accuracy_score(small_y, predicted_labels)
print("=============================================================")
print(f"Cross-validated estimate of accuracy on held-out data: {acc}")交叉训练的过程和最终精度如下:
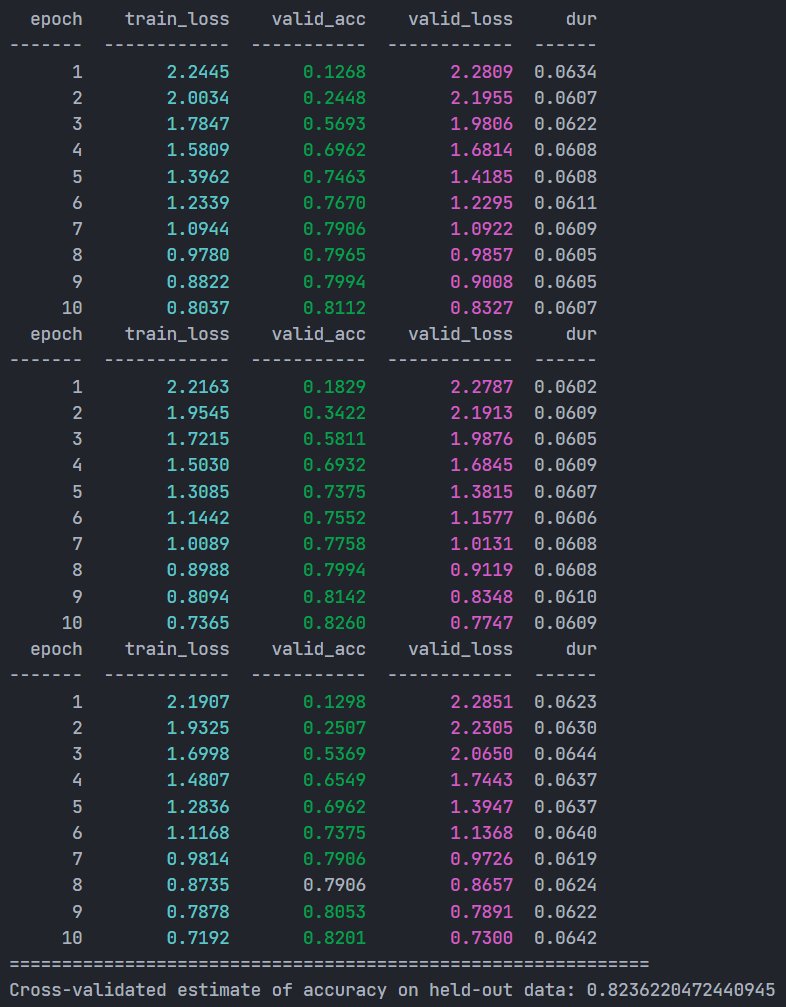
可以看到,随着噪声数据的比例变大以及数据量的变小,交叉验证的精度只有0.8236。
● cleanlab寻找噪声标签
重新在小数据集上进行置信学习:
ranked_label_issues = find_label_issues(small_y,pred_probs,return_indices_ranked_by="self_confidence",
)
print(f"Cleanlab found {len(ranked_label_issues)} label issues.")
print(f"Top 15 most likely label errors: \n {ranked_label_issues[:15]}")这次的寻找结果如下所示:

由于数据集整体发生了改变,找到的噪声数据也有所改变,这一次找到了101张噪声图片。
● re-training
去掉101张噪声数据后重新训练:
small_clean_X = np.delete(small_X, list(ranked_label_issues), 0)
small_clean_y = np.delete(small_y, list(ranked_label_issues), 0)
print(small_clean_X.shape, small_clean_y.shape)clean_small_pred_probs = cross_val_predict(model_skorch,small_clean_X,small_clean_y,cv=num_crossval_folds,method="predict_proba",
)
clean_small_predicted_labels = clean_small_pred_probs.argmax(axis=1)
clean_small_acc = accuracy_score(small_clean_y, clean_small_predicted_labels)
print(f"Cross-validated estimate of accuracy on held-out data: {clean_small_acc}")重新交叉验证的精度如下:
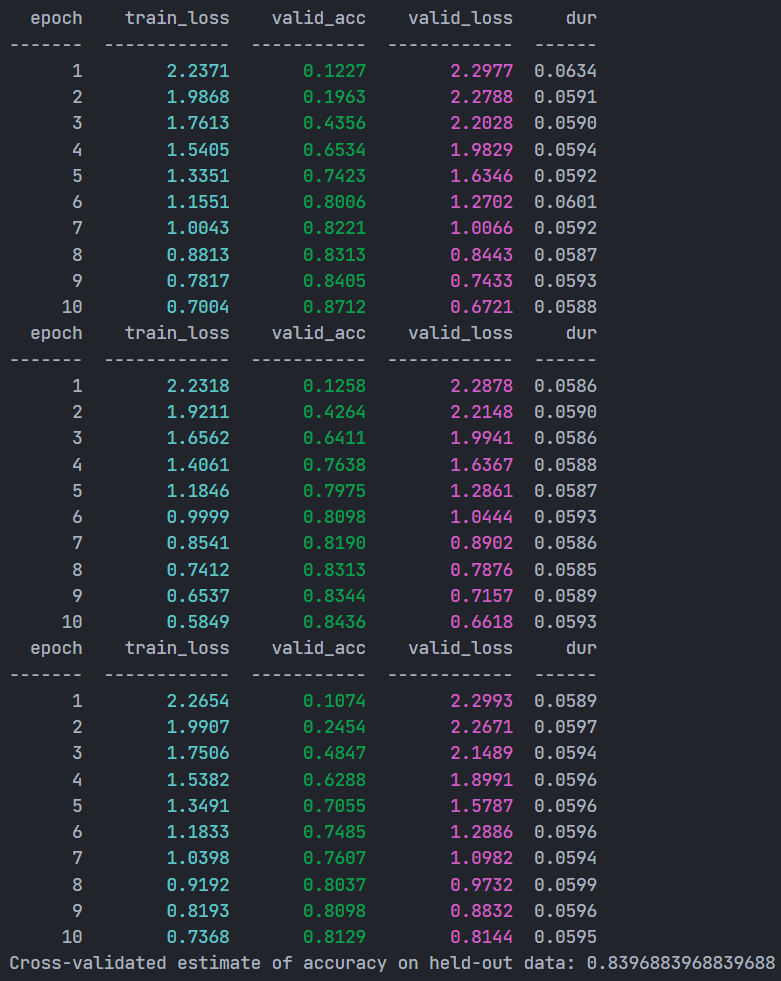
去除101个噪声数据后,精度来到了0.8396,对比0.8236,精度提升了1.6个百分点,可见在数据集噪声率5%左右时,置信学习能发挥比较明显的作用。
三、后记
本文介绍了利用置信学习的基本流程,并针对MNIST数据集尝试了cleanlab的使用,希望能帮助读者理解置信学习的原理和实际使用流程。后续也会继续推出其他寻找噪声标签的方法,并尝试在目标检测数据集上进行实验。
参考文献
[1] C. G. Northcutt, L. Jiang, and I. Chuang. Confident learning: Estimating uncertainty in dataset labels. Journal of Artificial Intelligence Research, 70:1373–1411, 2021.
[2] C. G. Northcutt, Anish Athalye, and Jonas Mueller. Pervasive Label Errors in Test Sets Destabilize Machine Learning Benchmarks, arXiv:2103.14749v4. 2021.
更多数据集上架动态、更全面的数据集内容解读、最牛大佬在线答疑、最活跃的同行圈子……欢迎添加微信opendatalab_yunying 加入OpenDataLab官方交流群。
这篇关于错误标注太多,不想人工检查?试试置信学习来自动找错的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





