本文主要是介绍【MySQL变更】gh-online-schema-change(gh-ost)原理解读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
gh-ost简介
gh-ost是处理MySQL在线表结构变更的工具,与pt-osc 不同,gh-ost不会使用触发器。
gh-ost 可以进行测试,暂停,动态控制和重新配置,审计还有其他许多操作perks。
命名
最初它被命名为gh-osc:GitHub Online Schema Change,
后来将c变为为t。gh-ost(发音:Ghost),代表 GitHub 的 Online Schema Transmogrifier/Translator/Transformer/Transfigurator
原理简介
所有现有的在线表结构变更工具都以相似的的原理:它们创建一个与原始表结构相同的幽灵表,在该表为空时进行表结构变更,缓慢并增量地将数据从原始表复制到幽灵表,同时将正在进行的更改(任何INSERT, DELETE,UPDATE应用于源表)应用到幽灵表。最后,在适当的时候,他们用幽灵表替换原表。
gh-ost使用相同的模式。然而,它与所有现有工具的不同之处在于不使用触发器。因为触发器是许多限制和风险的来源。
gh-ost 使用二进制日志流来捕获表数据变化,并将它们异步应用到ghost表上。gh-ost承担其他工具留给数据库执行的一些任务。因此,gh-ost可以更好地控制迁移过程;可以真正暂停它;可以真正将 migration 的写入负载与 master 的工作负载解耦。
此外,它还提供许多操作优势,使其更安全、更值得信赖且使用起来更有趣。
亮点
- 可以在从库上进行测试 ,从而建立你对gh-ost的信任。gh-ost在从库上表结构变更的过程和主库相同,并不会真正的替换原表。这样在从库上就会保留原始表与幽灵表,你可以对比统计两张表的数据从而验证工具操作的正确性。这也是我们如何在生产环境测试gh-ost的方法
- 真正的暂停 。当gh-ost throttles时,它真正停止在 master 上写入:没有行的拷贝,也没有正在进行事件的处理。通过节流,您可以将 master 恢复到其原始工作负载
- 动态控制。您可以交互式重新配置gh-ost,即使迁移仍在运行。您可以强行启动节流。
- 审计。您可以查询gh-ost状态。gh-ost监听 unix 套接字或 TCP。
- 控制切换时刻。gh-ost可以使用指示推迟可能是最有风险的步骤:交换原始表与幽灵表的表名称。直到您可以舒适地使用。也无需担心预计的切换时间不在办公时间。
- gh-ost可以使用外部钩子脚本。
用法
- noop迁移(仅测试迁移是否有效且可以进行)
- 一个真正的迁移,利用一个副本(迁移在主服务器上运行;gh-ost找出所涉及的服务器的身份。如果您的主服务器使用基于语句的复制,则需要模式)
- 在 master 上运行真正的迁移,(但gh-ost更喜欢前者)
- 在从库上进行真正的迁移(master未受影响)
- 在从库上进行测试迁移,这是您与的操作建立信任的方式。
更多提示
- --exact-rowcount 准确的进度指示
- --postpone-cut-over-flag-file 控制切换时间
- 更多交互式 参考 :交互式命令
基于触发器变更的弊端
- 负载 对于原始表的每个INSERT, DELETE,UPDATE需要在幽灵表/影子表上回放,另外还有触发器的本身的代价。
- 锁 锁竞争问题
- 没有真正的暂停 比如 pt-osc 只能暂停全量的同步,不能暂停触发器的复制
- 没有生产的测试
- 对于多个变更(不同表)的支持
- bound to server
更详细的解读 参考 :https://github.com/github/gh-ost/blob/master/doc/why-triggerless.md
无触发器的设计
pt-online-schema-change 在原始表创建三个触发器 (AFTER INSERT, AFTER UPDATE, AFTER DELETE) ,触发器的操作与原表的操作在同一事务中
基于无触发器的异步迁移
gh-ost的无触发设计采用异步方法。但是它不需要触发器,因为它不需要像 Facebook ost 工具那样有一个变更日志表。它不需要变更日志表的原因是它在另一个地方找到变更日志:二进制日志。
特别是,它读取基于行的复制 (RBR) 条目(您仍然可以将它与基于语句的复制一起使用!)并搜索适用于原始表的条目。
RBR 条目对于这项工作非常方便:它们将复杂的语句(可能是多表)分解为不同的、每表、每行的条目,这些条目易于阅读和应用。
gh-ost伪装为一个 MySQL 从副本:它连接到 MySQL 服务器并开始请求 binlog 事件,就好像它是一个真正的从副本一样。因此,它获得二进制日志的连续流,并过滤掉适用于原始表的那些事件。
gh-ost可以直接连接到主服务器,但更建议连接到主服务器的从副本之一。副本需要设置参数:log-slave-updates和binlog-format=ROW(gh-ost可以此设置)。
从二进制日志中读取,特别是在副本上读取二进制日志的情况,进一步强调了算法的异步性质。虽然事务可能(基于配置)与 binlog 条目写入同步,但它需要时间gh-ost- 假装是副本 - 会收到通知,将事件复制到下游并应用它。
异步设计意味着许多值得注意的结果,稍后将讨论。
工作流程
流程图
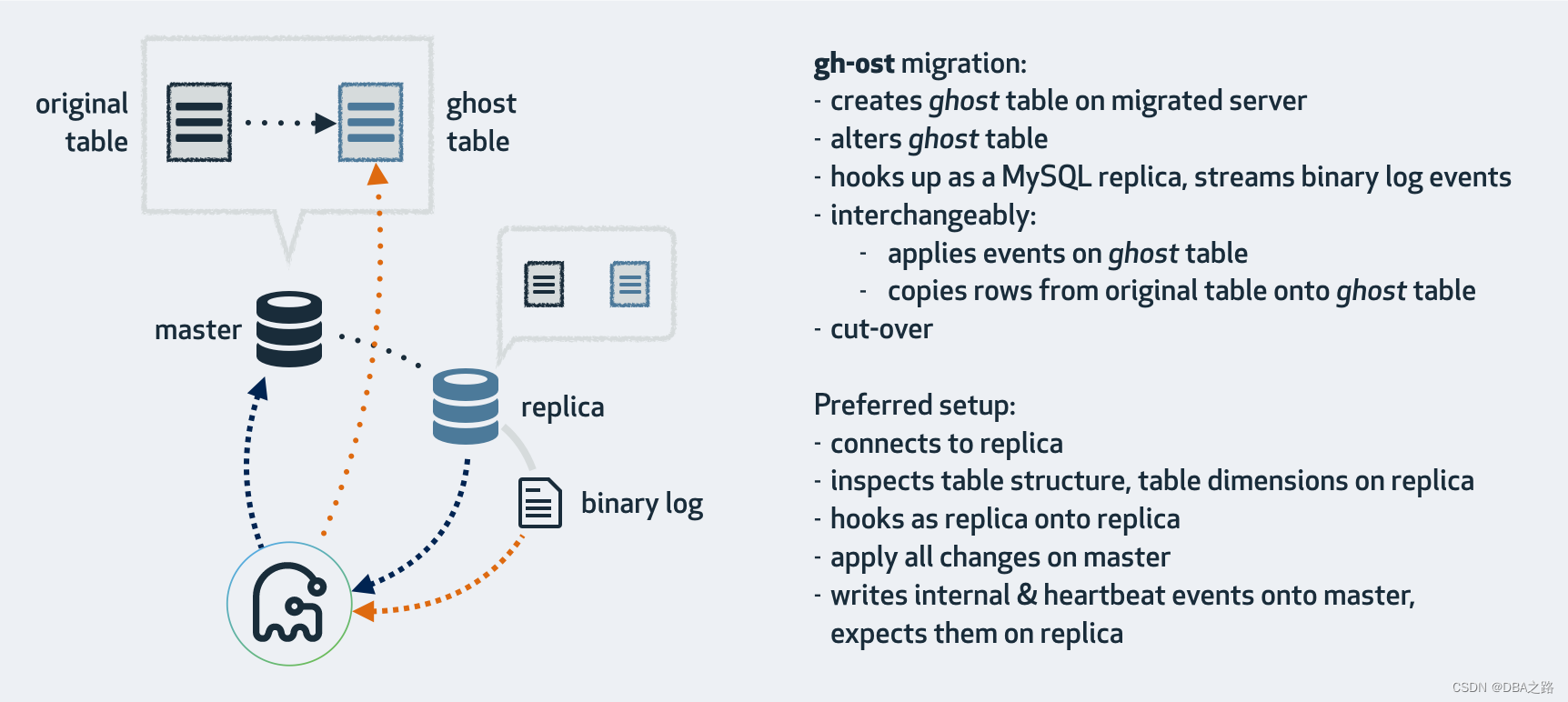
该工作流程包括从服务器读取表数据、从二进制日志读取事件数据、检查复制延迟或其他节流参数、将增量的表更应用到服务器(通常是主服务器)、通过二进制日志流发送提示等等。
初始化阶段
- 连接到主库或者从库
- 预验证 alter语句
- 验证权限,表存在
- 创建changelog 与 ghost 表(变更日志表与幽灵表)
- 对比原始表与幽灵表的结构差异,找到两张表都有的列,都有的唯一索引,验证外键。选择一个都有的唯一索引后续根据该字段对该表进行分块等处理。
- 设置binlog监听 开始监听changelog envents
- 将good to go 插入到changlog 表
- 开始监听原始表DML的二进制日志事件
- 读取原始表被选取我的唯一索引最大/最小的值
拷贝阶段
- 设置心跳机制:频繁写入 change log 表(我们认为这是低的,出于节流目的可忽略的写入负载)
- 持续更新状态
- 定期(经常)检查潜在的节流场景或提示
- 逐块(chunk)处理原始表的全量数据,将复制任务排队到 ghost 表上
- 从binlog中读取 DML 事件,将应用任务排队到 ghost 表
- 处理复制任务队列和应用任务队列并依次应用到ghost表 按节流状态暂停
- 一旦全表复制完成,注入/拦截“"copy all done”
- 存在postpone-cut-over-flag-file文件标识时 ,停止/推迟cut-over(我们继续应用正在进行的 DML)
切换完成阶段
- 原始表 write lock ,禁止写入
- 交换原始表与幽灵表名称
- 清理阶段 删除表
使用要求
gh-ost目前需要 MySQL 5.7 及更高版本。
服务器需要设置参数binlog 格式为 binlog_format=ROW 基于row的复制 与 binlog_row_image=FULL。将来 binlog_row_image=MINIMAL 可能会被支持
如果是复制的架构,需要变更的表的表结构 在主从上需要完全相同。
账号权限
对需要变更的表具有一下权限 ALTER, CREATE, DELETE, DROP, INDEX, INSERT, LOCK TABLES, SELECT, TRIGGER, UPDATE- 下面任选其一:
SUPER, REPLICATION SLAVE ON*.*,或:REPLICATION CLIENT, REPLICATION SLAVE ON*.*
MySQL需要设置参数 binlog_format=ROW,如果不是row格式,在使用gh-ost时需要指定参数 --switch-to-rbr
无论服务器上设置什么隔离级别, gh-ost连接MySQL服务器时 ,使用 REPEATABLE_READ 事务隔离级别
使用参数 --test-on-replica 时,在cut-over 阶段之前,gh-ost会停止主从复制,以便于你能比较两个表确认迁移是否正确
限制
外键约束不被支持
触发器不被支持
支持MySQL 5.7 JSON 列,但不作为PRIMARY KEY 其一部分
变更前后的 两张表 必须有相同的主键或者唯一索引,当拷贝数据时,这个key 被gh-ost用来迭代循环迭代
迁移用的字段必须不能包含 NULL 的值,意味着:
- 这个列是 NOT NULL 或者 这个列 可以为 NULL 但不包含任何 NULL值
- 默认情况下 ,如果唯一索引的列包含NULL 值,gh-ost 是 不会运行的。
不能迁移存在另外一张表名相同但是大小不同的表。例如,MyTable 和 MYtable。
Amazon RDS 可以使用给工具,但是有他自己的一些限制
可以兼容谷歌的 RDS ,需要使用参数 --gcp
可以兼容Aliyun 的RDS,但是需要使用参数 --aliyun-rds。
Azure MySQL数据库 可以使用该工具,但是需要参数 --azure
多源复制 (Multisource) 不被支持,他只能工作只有一个主的时候 (--allow-on-master)
双主模式 (Master-master ) 只有在模式(active-passive)下工作 ,.双写模式 (Active-active ) 不被支持。
如果有一个enum字段作为迁移键的一部分(通常是PRIMARY KEY),则迁移性能将会降低并且可能会很糟糕。
不支持迁移FEDERATED表,并且与gh-ost问题解决无关。
不支持加密二进制日志
ALTER TABLE ... RENAME TO some_other_name 不被支持
常见问题
cut-over 阶段是如何工作的? 是你真的原子性的吗?
cut-over 阶段 即 原表与 幽灵表交换的阶段 是一个原子的,阻塞的 ,受控的阶段。
Atomic(原子性):老表 与 幽灵表交互表名是一起的。不会存在老表的表名不存在的情况。
Blocking(阻塞的):应用的查询要不对老表进行操作,要不被阻塞,要不继续对新表进行操作。
Controlled(受控的):cut-over的超时时间可以预先定义阈值,超过该时间可以自动终止然后重试, cut-over只有在从库不延迟的情况下进行,
是否可以添加唯一索引?
在确保表中该字段不存在重复数据是可以添加的。
是否可以并发迁移?
可以 ,但是要需要注意添加参数 --replica-server-id
为什么更推荐 Connect to Replica
避免对主库超声额外的负载影响 。gh-ost作为复制客户端连接。每个额外的副本都会给主服务器增加一些负载。
方便监控复制延迟,--max-lag-millis 参数可以监控从副本的延迟
下载
Release GA release v1.1.6 · github/gh-ost · GitHub
参数解读
这篇关于【MySQL变更】gh-online-schema-change(gh-ost)原理解读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






