本文主要是介绍对于Syncronized你不知道的秘密,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Syncronized 原理
第一章:并发编程的三个问题
可见性
概念
可见性(visibility):一个线程对共享变量进行修改,其他线程立即得到修改后的最新知
演示
//1、静态成员变量
private static boolean var = true;
public static void main(String[] args) throws InterruptedException {//2、创建一条线程。不断读取共享变量的值new Thread(() -> {while (var) {System.out.println("继续执行");}}).start();Thread.sleep(2000);//3、创建一条新的变量、修改共享变量的值new Thread(() -> var = false ).start();
}
修改3 后 2中没有立即获得 3修改后的值。
原子性
概念:在一次或多次操作中、要么所有操作都执行不会受其他因素干扰而中断。要么所有操作都不执行。
案例演示:
/**** 原子性* 演示5个线程个执行1000次 i++*/
public class Atom {//定义共享变量 numprivate static Integer num = 0;public static void main(String[] args) throws InterruptedException {// 2 对num 进行 1000次 ++ 操作Runnable increment = () -> {for (int i = 0;i< 1000; i++) {num ++;}};//定义list结合Thread t = null;//3 生成5个线程List<Thread> list = new ArrayList<>();for (int i= 0 ;i < 5; i++) {t = new Thread(increment);t.start();list.add(t);}//4等到所有线程都执行完成再执行主线程for (Thread tt: list) {tt.join();}System.out.println(num);}
有序性
概念:
有序性(ordering):是指程序中代码执行顺序,java再编译时和运行时会对代码进行优化,会导致程序最终执行的不一定就是按照我们编写的代码的顺序。
演示:
需要添加pom依赖
org.openjdk.jcstress jcstress-core 0.15 test/**** 有序性*/
@JCStressTest
@Outcome(id={"1","4"} ,expect = Expect.ACCEPTABLE,desc = "ok")
@Outcome(id={"0"} ,expect = Expect.ACCEPTABLE_INTERESTING,desc = "danger")
@State
public class Order {int num = 0;boolean ready = false;@Actionpublic void actor1(I_Result r) {if (ready) {r.r1 = num + num;} else {r.r1 = 1;}}@Actionpublic void actor2(I_Result r) {num = 2;ready = true;}
}
java内存模型(JMM)
计算机结构
冯诺依曼,提出计算机五大部分组成:输入设备、输出设备、存储器、控制器、运算器
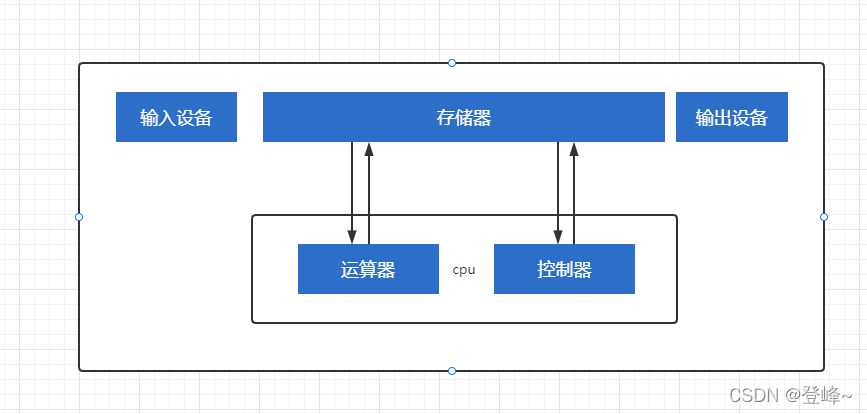
cpu
中央处理器,是计算机控制和运算的核心,我们的程序都会编程指令让cpu去执行,处理程序中的数据。
内存
我们的程序都是在内存中运行的, 内存会保存程序运行时的数据。供cpu处理
缓存
cpu的运算速度和内存的访问速度相差比较大。这就导致cpu每次操作都需要消耗很长时间等待。内存的读写速度成为了计算机运行的瓶颈。于是就有了在cpu 和主内存之间增加缓存的设计。最靠近cpu的换成成为L1,然后依次L2,L3和主内存。
cpu cache 分成三个级别,分别为:L1,L2,L3。级别越小越接近cpu,速度越快。同时也代表着容量越小。
1、L1是最接近cpu的,容量最小例如32k ,速度最快,每个核上都有一个L1 缓存
2、L2更大一些。例如256K,速度要慢一些,一般情况下每个核上都有一个独立的L2缓存。
3、L3最大的一级。例如12MB,同时也是缓存中最慢的一级。在同一个cpu插槽之间的核共享一个L3缓存
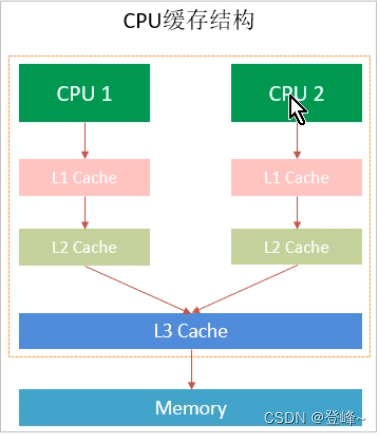
cpu 读取数据先读取 L1缓存。如果拿到数据处理后同步到内存中。如果L1没有对应数据。依次寻找L2缓存 、L3缓存、内存数据。cpu 拿到数据运算后回保存到L1缓存中。
java内存模型
java memory model (java内存模型/JMM), 不要和jiava内存结果混淆。
java内存模型,是java 虚拟机规范中所定义的一种内存模型,java内存模型是标准化的,屏蔽掉了底层不同计算机的区别。
java内存模型是一套规范,描述了java程序中各个变量(线程共享变量)的访问规则,以及在jvm中将变量存储到内存和从内存中读取变量这样的底层细节,具体如下。
- 主内存
主内存是所有线程共享。都能访问的。所有线程变量都存储与主内存中。
- 工作内存
每个线程都有自己的工作内存,工作内存只存储改线城对共享变量的副本。线程对变量的所有操作(读,写)都必须在工作内存中完成,而不是直接读写主内存中的变量,不同线程之间也不能直接访问对方的工作内存变量。
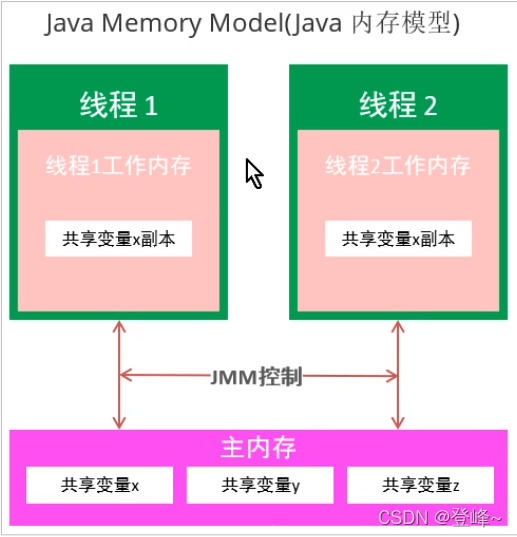
线程读取共享内存中的变量。先把主内存中的共享变量拷贝的线程内存中的贡献共享变量副本。操作共享变量副本,然后再把副本同步回主内存中的共享变量。
java内存模型的作用
java 内存模型是一套多线程读写共享数据时,对共享数据的可见性、有序性、和原子性的规则和保障。
synchronized、volatile
CPU缓存和内存和java内存模型的关系
通过上面cpu内存、java内存模型、java多线程的实现原理的了解。我们已经意识到,多线程的执行最终都会映射到硬件处理器上进行执行。
但java内存模型和硬件内存结构完全不一致。对于硬件内存来说只有寄存器、缓存内存、主内存的概念,并没有工作内存和主内存之分,也没有说java内存模型的划分对硬件来说并没有任何影响,因为JMM只是一种抽象的概念,是一组规则,不管是工作内存的数据还是主内存的数据,对于计算机来说都会存储到计算机主内存中,当然也有可能存储到cup缓存或寄存器中,依次总体上来说,java内存模型和计算机硬件内存架构是一个相互交叉的关系,是一种抽象概念划分与真是物理硬件的交叉。
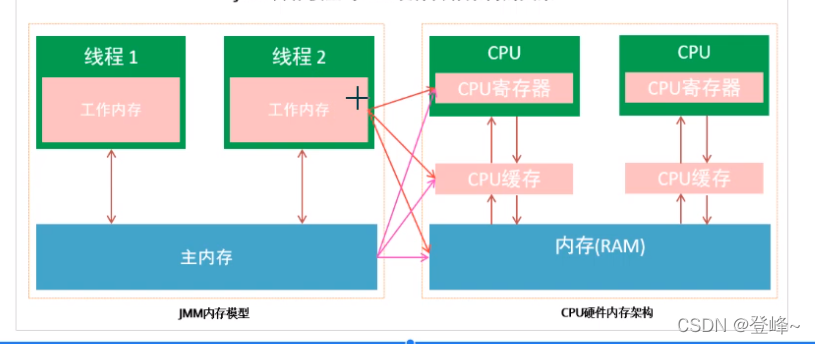
主内存与工作内存之间的交互
java内存中定义了8中操作来完成,主内存与工作内存之间具体的交互协议,即一个变量如何从主内存拷贝到工作内存、如何从工作内存同步主内存之类的实现细节,虚拟机实现时必须保证下面提及的每一种操作都是原子的,不可再分的。
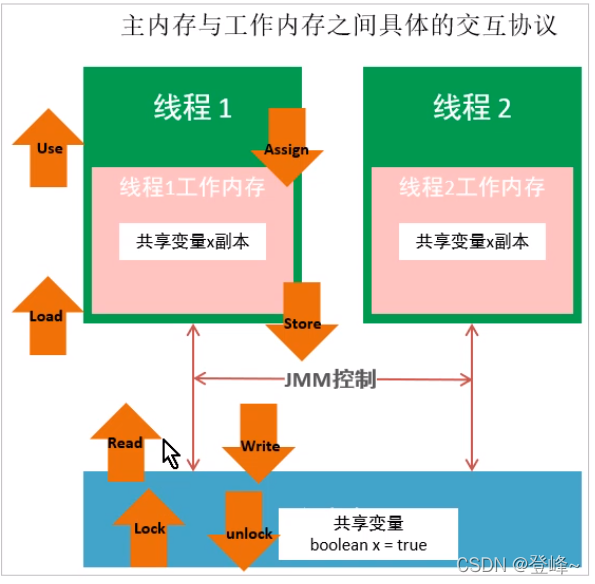
注意:
1、如果对一个变量执行lock操作,将会清空工作内存此变量的值。
2、对一个变量执行unlock操作之前,必须先把此变量同步到主内存中。
8个原子操作
lack -> read ->load -> use -> assign -> store -> write -> unlock
第三章:synchronized保证三大特性
synchronized 能够保证在同一个时刻最多只有一个线程执行该段代码,以达到保证并发安全的效果。
synchronized (锁对象) {//受保护的资源;
}
synchronized保证原子性
演示:
/**** 原子性* 演示5个线程个执行1000次 i++*/
public class Atom {//定义共享变量 numprivate static Integer num = 0;private static Object obj = new Object();public static void main(String[] args) throws InterruptedException {// 2 对num 进行 1000次 ++ 操作Runnable increment = () -> {for (int i = 0;i< 1000; i++) {synchronized (obj) {num++;}}};//定义list结合Thread t = null;//3 生成5个线程List<Thread> list = new ArrayList<>();for (int i= 0 ;i < 5; i++) {t = new Thread(increment);t.start();list.add(t);}//4等到所有线程都执行完成再执行主线程for (Thread tt: list) {tt.join();}System.out.println(num);}
}
synchronized原理:
保证同一个时间只有一个线程操作,就不会出现安全问题。保证一个线程拿到锁,才能进入同步代码块。
synchronized保证可见性
1、使用volatile
private static volatile boolean var = true;
原理:线程修改主线程中的变量。其他已经线程内存会重置这个变量的副本。导致其他线程重新读取该变量。
2、使用synchronized
/**** 可见性问题*/
public class Visibility {//1、静态成员变量//第一种方案
// private static volatile boolean var = true;private static boolean var = true;private static Object obj = new Object();public static void main(String[] args) throws InterruptedException {//2、创建一条线程。不断读取共享变量的值new Thread(() -> {while (var) {synchronized (obj) {System.out.println("继续执行");}}}).start();Thread.sleep(2000);//3、创建一条新的变量、修改共享变量的值new Thread(() -> var = false ).start();}
synchronized保证可见性,执行synchronized时,会对lock原子操作会刷新工作内存中共享变量的值。
synchronized保证有序性
as-if-serial 语义的意思:不管编译器和cpu如何重新排序,必须保证在单线程的情况下程序的结果都是正确。
一下数据有依赖关系,不能重新排序。
写后续:
int a = 1;
int b = a;
写后写:
int a = 1;
int a = 2;
读后写:
int a = 1;
int b = a;
int a = 2;
编译器和处理器不会对存在的数据依赖关系的操作冲排序,因为这种重排序会改变执行结果。但是,如果操作之间不存在数据依赖关系,这些操作就可能被编译器冲排序。
int a = 1;
int b = 2;
int c = a + b;
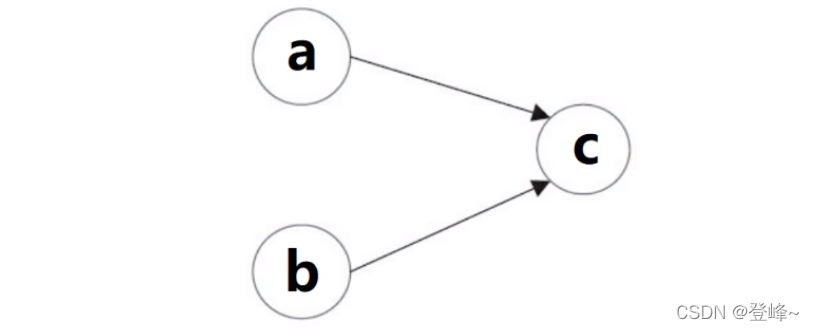
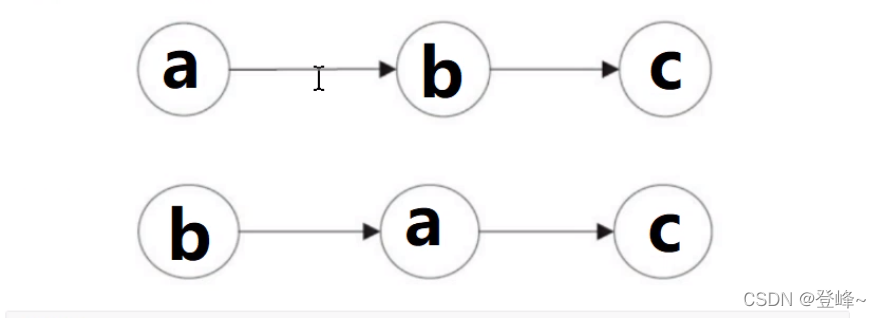
上图所示a和c之间存在依赖关系,b和c之间存在依赖关系。因此在最终执行的指令中,c不能被冲排序到a和b前面。但是a和b之间没有依赖关系,编译器和处理器是可以重新排序a和b之间的执行顺序。下面的改图的两种执行顺序。
synchronized解决冲排序方法
/**** 有序性*/
//@JCStressTest
//@Outcome(id={"1","4"} ,expect = Expect.ACCEPTABLE,desc = "ok")
//@Outcome(id={"0"} ,expect = Expect.ACCEPTABLE_INTERESTING,desc = "danger")
//@State
public class Order {int num = 0;boolean ready = false;private static Object obj = new Object();
// @Actionpublic void actor1(I_Result r) {synchronized (obj) {if (ready) {r.r1 = num + num;} else {r.r1 = 1;}}}
// @Actionpublic void actor2(I_Result r) {synchronized (obj) {num = 2;ready = true;}}
synchronized保证重排序原理
相当于单线程执行代码块。
第四章:synchronized特性
1、可重入
一个线程可以多次执行synchronized操作,重复获取同一把锁。
原理: synchronized的锁对象中有一个计数器(recursions变量)会记录线程获得第几次锁.在执行完代码块时,计数器会-1,计数器的数量为0,就释放这个锁。
优点:避免死锁。
2、不可中断
一个线程获得锁后,另一个线程想要获得锁,必须处于阻塞或等待状态,若果第一个线程不释放锁,第二个线程就会一直阻塞或等待,不可以被中断。
synchronized 属于不可被中断。
Lock 的lock方法是不可以被中断。
Lock 的trylock方法是可以被中断。
第五章:synchronized原理
同步代码块
源码:
package com.cn.java;
public class Main {private static Object object = new Object();public static void main(String[] args) {synchronized (object) {System.out.println(1);}}public synchronized void test() {synchronized (object) {System.out.println("a");}}
}
找到对应的文件,在地址栏中输出cmd 进入dos命令
javap -p -v Main.class
public static void main(java.lang.String[]);descriptor: ([Ljava/lang/String;)Vflags: ACC_PUBLIC, ACC_STATICCode:stack=2, locals=3, args_size=10: getstatic #2 // Field object:Ljava/lang/Object;3: dup4: astore_15: monitorenter6: getstatic #3 // Field java/lang/System.out:Ljava/io/PrintStream;9: iconst_110: invokevirtual #4 // Method java/io/PrintStream.println:(I)V13: aload_114: monitorexit15: goto 2318: astore_219: aload_120: monitorexit21: aload_222: athrow23: return 5: monitorenter //获取锁6: getstatic #3 // Field java/lang/System.out:Ljava/io/PrintStream;9: ldc #5 // String a11: invokevirtual #6 // Method java/io/PrintStream.println:(Ljava/lang/String;)V14: aload_115: monitorexit //释放锁
jvm中对于monitorenter的描述
每个对象都会和一个监视器monitor关联。监视器被占用时会被锁住,其他线程午饭获取该monitor。当jvm执行某个线程的摸个方法的monitorenter时,他会尝试去获取当前对象的对应的monitor所有权。其过程如下:
1、若monitor的进入数为0,线程可以进入monitor,并将monitor的进入设置为1.当钱线程为monitor的拥有者。
2、若线程已拥有monitor的所有权,允许他重入monitor,这进入monitor进入数加1.
3、若其他线程已经占有monitor所有权,那么当前尝试获取monitor的所有权的线程会被堵塞,知道monitor的拥有者的进入数为0,才重新尝试获取monitor的所有权。
同步代码块中出现异常会释放锁。
同步方法
public synchronized void test();descriptor: ()Vflags: ACC_PUBLIC, ACC_SYNCHRONIZEDCode:stack=2, locals=3, args_size=10: getstatic #2 // Field object:Ljava/lang/Object;3: dup4: astore_15: monitorenter6: getstatic #3 // Field java/lang/System.out:Ljava/io/PrintStream;9: ldc #5 // String a11: invokevirtual #6 // Method java/io/PrintStream.println:(Ljava/lang/String;)V14: aload_115: monitorexit16: goto 2419: astore_220: aload_121: monitorexit22: aload_223: athrow24: return
会增加ACC_PUBLIC, ACC_SYNCHRONIZED 修饰。会隐式调用monitorenter 和 monitorexit。在执行同步方法钱会调用 monitorenter 。执行完成之后调用monitorexit。
每个锁对象都会关联一个monitor(监视器),他内部有两个重要成员变量owner 会保存获得锁的线程,recursions会保存获得锁的次数。
当 执行 monitorenter 时,recursions 会 + 1 。当执行monitorexit时 recursions 会 - 1。当recursions = 0 这个线程就会释放锁。
常见面试题:synchronized 和lock 的区别。
1、synchronized 是常用关键字。 Lock 是接口。
2、synchronized 会自动释放锁。 Lock 必须手动释放锁。
3、synchronized 是不可中断的。Lock可以中断也可以不中断。
4、通过Lock 可以知道线程有没有拿到锁。synchronized 不能。
5、synchronized 锁住对象和代码块。lock智能锁住代码块。
6、Lock可以使用读写锁提高线程读效率。
7、synchronized 是非公平锁,ReetrantLock可以空值是否公平锁。
深入JVM源码
jvm源码下载
http://openjdk.java.net/ --> mercurial --> jdk8 --> hotspot --> zip
IDE(Clion)下载
https://www.jetbrains.com/
monitor监视器锁
无论是synchronized代码块还是synchronized方法,其线程安全的语义实现最终依赖一个叫monitor的东西。那么这个什么的monitor 是什么呢?下面我们来详细介绍一下。
在hotspot虚拟机中,monitor是由objectmonit实现,其源代码是c++来实现的,位于hostpot源码ObjectMonitor.hpp文件中(src/share/vm/runtime/objectMonitor.hpp)。ObjectMonitor主要数据结构如下:
ObjectMonitor() {_header = NULL;_count = 0;_waiters = 0,_recursions = 0; //线程重入的次数_object = NULL;//存储该monitor对象的线程_owner = NULL;//标识拥有该monitor的线程_WaitSet = NULL;//处于wait状态的线程,会被加入到_waitset_WaitSetLock = 0 ;_Responsible = NULL ;_succ = NULL ;_cxq = NULL ;//多线程竞争锁是的单项列表FreeNext = NULL ;_EntryList = NULL ;//处于等待锁block状态线程,会被加入到该列表_SpinFreq = 0 ;_SpinClock = 0 ;OwnerIsThread = 0 ;_previous_owner_tid = 0;}
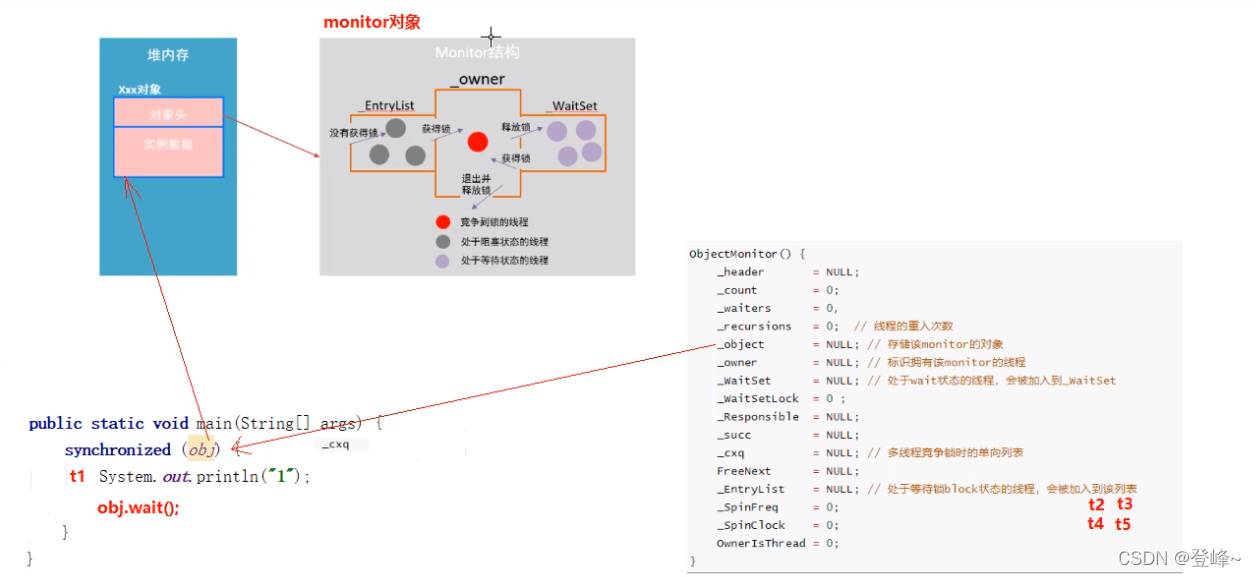
两个线程 t1与 t2、t3 ,t1到锁后 t2与t3 进入_cxq 进行等待。 如果t1执行完成后,t1有抢到锁 ,t2和t3 进入到 _EntryList等待。
有来了两个线程 t4和t5、t1执行完成后 t1又抢到锁 。 t4和t5则进入 _EntryList中等待。
monitor竞争
1、执行monitorenter时,会调用InterpreterRuntime.cpp
位于(src/share/vminterpreter/interpreterRuntime.cpp)的interpreterRuntime::monitorenter函数,具体代码请参见HotSpot源码。
//%note monitor_1
IRT_ENTRY_NO_ASYNC(void, InterpreterRuntime::monitorenter(JavaThread* thread, BasicObjectLock* elem))
#ifdef ASSERTthread->last_frame().interpreter_frame_verify_monitor(elem);
#endifif (PrintBiasedLockingStatistics) {Atomic::inc(BiasedLocking::slow_path_entry_count_addr());}Handle h_obj(thread, elem->obj());assert(Universe::heap()->is_in_reserved_or_null(h_obj()),"must be NULL or an object");if (UseBiasedLocking) { //是否设置偏向锁// Retry fast entry if bias is revoked to avoid unnecessary inflationObjectSynchronizer::fast_enter(h_obj, elem->lock(), true, CHECK);} else { //调用重量级锁ObjectSynchronizer::slow_enter(h_obj, elem->lock(), CHECK);}assert(Universe::heap()->is_in_reserved_or_null(elem->obj()),"must be NULL or an object");
#ifdef ASSERTthread->last_frame().interpreter_frame_verify_monitor(elem);
#endif
IRT_END
2、对于重量级锁,monitorenter函数中会调用ObjectSynchronizer::slow_enter
3、最终调用ObjectMonitor::enter(位于src/share/vm/runtime/objectMonitor.cpp)
void ATTR ObjectMonitor::enter(TRAPS) {// The following code is ordered to check the most common cases first// and to reduce RTS->RTO cache line upgrades on SPARC and IA32 processors.Thread * const Self = THREAD ;void * cur ;//通过cas操作尝试吧monitor的_owner字段设置为当前线程。cur = Atomic::cmpxchg_ptr (Self, &_owner, NULL) ;if (cur == NULL) {// Either ASSERT _recursions == 0 or explicitly set _recursions = 0.assert (_recursions == 0 , "invariant") ;assert (_owner == Self, "invariant") ;// CONSIDER: set or assert OwnerIsThread == 1return ;}//如果抢到锁if (cur == Self) {_recursions ++ ; //吧_recursions 属性加1return ;}if (Self->is_lock_owned ((address)cur)) {assert (_recursions == 0, "internal state error");_recursions = 1 ;_owner = Self ; //如果抢到锁 把线程拥有者 设置为selfOwnerIsThread = 1 ;return ;}assert (Self->_Stalled == 0, "invariant") ;Self->_Stalled = intptr_t(this) ;if (Knob_SpinEarly && TrySpin (Self) > 0) {assert (_owner == Self , "invariant") ;assert (_recursions == 0 , "invariant") ;assert (((oop)(object()))->mark() == markOopDesc::encode(this), "invariant") ;Self->_Stalled = 0 ;return ;}assert (_owner != Self , "invariant") ;assert (_succ != Self , "invariant") ;assert (Self->is_Java_thread() , "invariant") ;JavaThread * jt = (JavaThread *) Self ;assert (!SafepointSynchronize::is_at_safepoint(), "invariant") ;assert (jt->thread_state() != _thread_blocked , "invariant") ;assert (this->object() != NULL , "invariant") ;assert (_count >= 0, "invariant") ;Atomic::inc_ptr(&_count);EventJavaMonitorEnter event;{ JavaThreadBlockedOnMonitorEnterState jtbmes(jt, this);DTRACE_MONITOR_PROBE(contended__enter, this, object(), jt);if (JvmtiExport::should_post_monitor_contended_enter()) {JvmtiExport::post_monitor_contended_enter(jt, this);}OSThreadContendState osts(Self->osthread());ThreadBlockInVM tbivm(jt);Self->set_current_pending_monitor(this);//如果没有抢到锁。会执行下列代码。for (;;) {jt->set_suspend_equivalent();//获取锁失败。EnterI (THREAD) ;if (!ExitSuspendEquivalent(jt)) break ;_recursions = 0 ;_succ = NULL ;exit (false, Self) ;jt->java_suspend_self();}Self->set_current_pending_monitor(NULL);}Atomic::dec_ptr(&_count);assert (_count >= 0, "invariant") ;Self->_Stalled = 0 ;// Must either set _recursions = 0 or ASSERT _recursions == 0.assert (_recursions == 0 , "invariant") ;assert (_owner == Self , "invariant") ;assert (_succ != Self , "invariant") ;assert (((oop)(object()))->mark() == markOopDesc::encode(this), "invariant") ;DTRACE_MONITOR_PROBE(contended__entered, this, object(), jt);if (JvmtiExport::should_post_monitor_contended_entered()) {JvmtiExport::post_monitor_contended_entered(jt, this);}if (event.should_commit()) {event.set_klass(((oop)this->object())->klass());event.set_previousOwner((TYPE_JAVALANGTHREAD)_previous_owner_tid);event.set_address((TYPE_ADDRESS)(uintptr_t)(this->object_addr()));event.commit();}if (ObjectMonitor::_sync_ContendedLockAttempts != NULL) {ObjectMonitor::_sync_ContendedLockAttempts->inc() ;}
}
monitor等待
void ATTR ObjectMonitor::EnterI (TRAPS) {Thread * Self = THREAD ;assert (Self->is_Java_thread(), "invariant") ;assert (((JavaThread *) Self)->thread_state() == _thread_blocked , "invariant") ;// Try the lock - TATASif (TryLock (Self) > 0) {assert (_succ != Self , "invariant") ;assert (_owner == Self , "invariant") ;assert (_Responsible != Self , "invariant") ;return ;}DeferredInitialize () ;if (TrySpin (Self) > 0) {assert (_owner == Self , "invariant") ;assert (_succ != Self , "invariant") ;assert (_Responsible != Self , "invariant") ;return ;}assert (_succ != Self , "invariant") ;assert (_owner != Self , "invariant") ;assert (_Responsible != Self , "invariant") ;ObjectWaiter node(Self) ;Self->_ParkEvent->reset() ;node._prev = (ObjectWaiter *) 0xBAD ;node.TState = ObjectWaiter::TS_CXQ ;ObjectWaiter * nxt ;for (;;) {node._next = nxt = _cxq ;if (Atomic::cmpxchg_ptr (&node, &_cxq, nxt) == nxt) break ;if (TryLock (Self) > 0) {assert (_succ != Self , "invariant") ;assert (_owner == Self , "invariant") ;assert (_Responsible != Self , "invariant") ;return ;}}if ((SyncFlags & 16) == 0 && nxt == NULL && _EntryList == NULL) {Atomic::cmpxchg_ptr (Self, &_Responsible, NULL) ;}TEVENT (Inflated enter - Contention) ;int nWakeups = 0 ;int RecheckInterval = 1 ;for (;;) {if (TryLock (Self) > 0) break ;assert (_owner != Self, "invariant") ;if ((SyncFlags & 2) && _Responsible == NULL) {Atomic::cmpxchg_ptr (Self, &_Responsible, NULL) ;}if (_Responsible == Self || (SyncFlags & 1)) {TEVENT (Inflated enter - park TIMED) ;Self->_ParkEvent->park ((jlong) RecheckInterval) ;RecheckInterval *= 8 ;if (RecheckInterval > 1000) RecheckInterval = 1000 ;} else {TEVENT (Inflated enter - park UNTIMED) ;Self->_ParkEvent->park() ;}if (TryLock(Self) > 0) break ;TEVENT (Inflated enter - Futile wakeup) ;if (ObjectMonitor::_sync_FutileWakeups != NULL) {ObjectMonitor::_sync_FutileWakeups->inc() ;}++ nWakeups ;if ((Knob_SpinAfterFutile & 1) && TrySpin (Self) > 0) break if ((Knob_ResetEvent & 1) && Self->_ParkEvent->fired()) {Self->_ParkEvent->reset() ;OrderAccess::fence() ;}if (_succ == Self) _succ = NULL ;OrderAccess::fence() ;}assert (_owner == Self , "invariant") ;assert (object() != NULL , "invariant") ;UnlinkAfterAcquire (Self, &node) ;if (_succ == Self) _succ = NULL ;assert (_succ != Self, "invariant") ;if (_Responsible == Self) {_Responsible = NULL ;OrderAccess::fence(); // Dekker pivot-point}if (SyncFlags & 8) {OrderAccess::fence() ;}return ;
}
具体代码流程概括如下:
1、当前线程被封装ObjectWaiter对象的node,状态设置成ObjectWaiter:TS_CXQ.
2、在for循环中,通过cas把node节点push到_cxq列表中,同一时刻可能有多个线程吧自己的node节点push到 _cxq列表中。
3、node节点push到_cxq列表之后,通过自旋尝试获取锁,如果还是获取不到锁,则通过park将当前线程挂起,等待被唤醒。
4、当该线程被唤醒时,会从挂起的点继续执行,通过ObjectMonitor::TryLock尝试获取锁。
monitor释放
当某个持有锁的执行代码块或方法执行完成,会释放锁,给其他线程机会执行同步代码块或同步方法,在hotspot,通过退出monitor的方式来实现锁释放,并通知被阻塞的线程,具体实现位于ObjectMonitor的exit方法中。位于:(/src/share/vm/runtime/objectMonitor.cpp),源码如下所示。
void ATTR ObjectMonitor::exit(bool not_suspended, TRAPS) {Thread * Self = THREAD ;if (THREAD != _owner) {if (THREAD->is_lock_owned((address) _owner)) {// Transmute _owner from a BasicLock pointer to a Thread address.// We don't need to hold _mutex for this transition.// Non-null to Non-null is safe as long as all readers can// tolerate either flavor.assert (_recursions == 0, "invariant") ;_owner = THREAD ;_recursions = 0 ;OwnerIsThread = 1 ;} else {// NOTE: we need to handle unbalanced monitor enter/exit// in native code by throwing an exception.// TODO: Throw an IllegalMonitorStateException ?TEVENT (Exit - Throw IMSX) ;assert(false, "Non-balanced monitor enter/exit!");if (false) {THROW(vmSymbols::java_lang_IllegalMonitorStateException());}return;}}ObjectWaiter * w = NULL ;int QMode = Knob_QMode ;//qmode = 2;直接绕过entrylist队列,从cxq队列中获取线程用于竞争锁。if (QMode == 2 && _cxq != NULL) {w = _cxq ;assert (w != NULL, "invariant") ;assert (w->TState == ObjectWaiter::TS_CXQ, "Invariant") ;ExitEpilog (Self, w) ;return ;} //qmode = 3;从 cxq队列插入entrylist队列尾部if (QMode == 3 && _cxq != NULL) {w = _cxq ;for (;;) {assert (w != NULL, "Invariant") ;ObjectWaiter * u = (ObjectWaiter *) Atomic::cmpxchg_ptr (NULL, &_cxq, w) ;if (u == w) break ;w = u ;}assert (w != NULL , "invariant") ;ObjectWaiter * q = NULL ;ObjectWaiter * p ;for (p = w ; p != NULL ; p = p->_next) {guarantee (p->TState == ObjectWaiter::TS_CXQ, "Invariant") ;p->TState = ObjectWaiter::TS_ENTER ;p->_prev = q ;q = p ;}ObjectWaiter * Tail ;for (Tail = _EntryList ; Tail != NULL && Tail->_next != NULL ; Tail = Tail->_next) ;if (Tail == NULL) {_EntryList = w ;} else {Tail->_next = w ;w->_prev = Tail ;}}//qmode = 3;从 cxq队列插入entrylist队列头部if (QMode == 4 && _cxq != NULL) {w = _cxq ;for (;;) {assert (w != NULL, "Invariant") ;ObjectWaiter * u = (ObjectWaiter *) Atomic::cmpxchg_ptr (NULL, &_cxq, w) ;if (u == w) break ;w = u ;}assert (w != NULL , "invariant") ;ObjectWaiter * q = NULL ;ObjectWaiter * p ;for (p = w ; p != NULL ; p = p->_next) {guarantee (p->TState == ObjectWaiter::TS_CXQ, "Invariant") ;p->TState = ObjectWaiter::TS_ENTER ;p->_prev = q ;q = p ;}if (_EntryList != NULL) {q->_next = _EntryList ;_EntryList->_prev = q ;}_EntryList = w ;}//唤醒线程。w = _EntryList ;if (w != NULL) {assert (w->TState == ObjectWaiter::TS_ENTER, "invariant") ;ExitEpilog (Self, w) ;return ;}
}1、退出同步时会让_recursions减1,当recursions的值减为0,说明程序释放锁。
2、根据不同的策略(由QMode指定),从cxq或Entrylist中获得头结点,通过OjbectMonitor::ExitEpilog方法唤醒该节点封装的线程,唤醒操作最终由unpark完成,实现如下:
void ObjectMonitor::ExitEpilog (Thread * Self, ObjectWaiter * Wakee) {assert (_owner == Self, "invariant") ;_succ = Knob_SuccEnabled ? Wakee->_thread : NULL ;ParkEvent * Trigger = Wakee->_event ;Wakee = NULL ;OrderAccess::release_store_ptr (&_owner, NULL) ;OrderAccess::fence() ; // ST _owner vs LD in unpark()if (SafepointSynchronize::do_call_back()) {TEVENT (unpark before SAFEPOINT) ;}DTRACE_MONITOR_PROBE(contended__exit, this, object(), Self);Trigger->unpark() ; //唤醒之前被pack挂起的线程。if (ObjectMonitor::_sync_Parks != NULL) {ObjectMonitor::_sync_Parks->inc() ;}
}
monitor是重量级锁
ObjectMonitor的函数调用中会设计到Atomic:;cmpxchg_ptr,Atomic::inc_ptr等内核函数,执行同步代码块,没有竞争到锁的对象会被park()挂起,竞争到锁的线程会unpark()唤醒。这个时候就会存在操作系统用户和内核态转换,这种切换消耗大量系统资源。所有syncronized是java一个重量级(heavyweight)锁
用户态和内核态是什么东西?想要了解用户态和内核态还需要了解一下linux系统的体系架构:
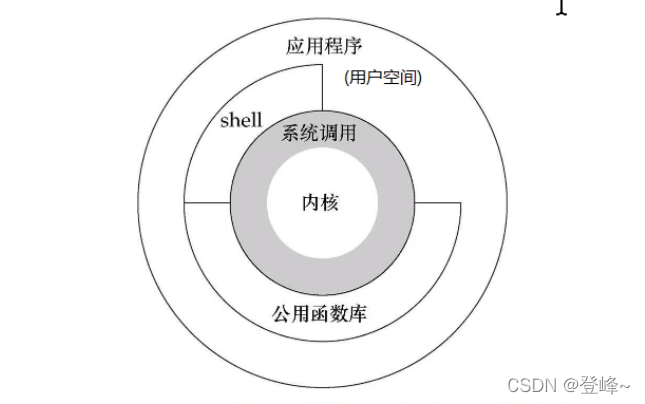
从上可以看出,linux操作系统的体系架构分为:用户空间(应用程序活动空间)和内核。
内核:卑职可以理解为一种软件,空值计算机的硬件资源,并提供上层应用程序运行环境。
用户空间:上层应用程序活动的空间。应用程序的执行必须依托于内核提供的资源,包括cpu资源、存储资源、I/O资源等。
系统调用:为了使上层应用程序能够方位到这些资源,内核必须为上层应用程序提供的接口:即系统调用。
素有进程舒适化都运行与用户空间,此时即为用户运行状态(简称:用户态);但是当它调用执行某些操作时,例如I/O调用,此时需要陷入内核中运行,我们就成进程处于内核运行态(或简称内核态)。系统调用的过程可以理解为:
1 .用户条序将一些数据值放在寄存器中,或者使用参数创建一个堆栈,以此表明需要操作系统提供的服务。
2 .用户态程序执行系统调用。
3 . CPU切换到内核态,并跳到位于内存指定位置的指令。
4 .系统调用处理器(system call handler)会读取程序放入内存的数据参数,并执行程序清求的服务。
5 .系统调用完成后,操作系统会重置CPU为用户态并返回系统调用的结果。
由此可见用户态切换至内核态需要传递许多变量,同时内核还需要保护好用户态在切换时的一些寄存器值、变量
等,以备内核态切换回用户态。这种切换就带来了大量的系统资源消耗,这就是在synchronized未优化之前,效率低的原因。
第六章:JDK6 synchronized优化
CAS概述和作用:
CAS的全是:Compare And Swap(比较相同再交换)。是现代CPU广泛的一种内存中的共享数据进行的一种特殊指令。
CAS的作用:CAS可以将比较和交换转为原子操作,这个原子操作直接由CPU保证。CAS可以保证共享变量赋值时的原子操作。CAS操作依赖3个值:内存中的值V,旧的值X,要修改的值B,如果旧值的预估值X等于内存中的值V,就讲新的值B保存到内存中。
*** cas* 使用AtomicInteger*/
public class Cas01 {//定义共享变量 numprivate static AtomicInteger num = new AtomicInteger(0);public static void main(String[] args) throws InterruptedException {// 2 对num 进行 1000次 ++ 操作Runnable increment = () -> {for (int i = 0;i< 1000; i++) {num.incrementAndGet();}};//定义list结合Thread t = null;//3 生成5个线程List<Thread> list = new ArrayList<>();for (int i= 0 ;i < 5; i++) {t = new Thread(increment);t.start();list.add(t);}//4等到所有线程都执行完成再执行主线程for (Thread tt: list) {tt.join();}System.out.println(num.get());}
}
CAS原理
通过刚才AtomicInteger的,Unsafe类提供原子操作。
Unsafe类介绍
Unsafe类使java拥有了像c语言指针一样操作内存空间的能力,同时也带来了指针的问题,过度使用Unsafe类会使得Unsafe类会使得出错的几率变大,因此java官方不建议使用。官方文档几乎没有。Unsafe对象不能直接调用,智能通过反射获得。

1、t1线程 执行 内存中值0 ,旧的值 0 比较相等 -->var4 + var 5 结果更新到内存
2、同时t2线程拿到内存中的值1 ,就得值0 不相等返回false ,继续执行循环 。内存中的1 和预估值1 相等 var4 + var 5 结果更新到内存。
悲观锁和乐观锁
悲观锁从悲观的角度出发:
总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿 这个数据就会阻塞。因此synchronized我
们也将其称之为悲观锁。JDK中的ReentrantLock也是一种悲观锁。性能 较差!
乐观锁从乐观的角度出发:
总是假设最好的情况,每次去拿数据的时候都认为别人不会修改,就算改了也没关系,再重试即可。所以不会上 锁,但是在更新的时候会判断一下在此期间
别人有没有去修改这个数据,如何没有人修改则更新,如果有人修改则 重试。
CAS这种机制我们也可以将其称之为乐观锁。综合性能较好!
CAS获取共享变量时,为了保证该变量的可见性,需要使用volatile修饰。结合CAS和volatile可以实现无锁并 发,适用于竞争不激烈、多核CPU的场景下"
1.因为没有使用synchronized,所以线程不会陷入阻塞,这是效率提升的因素之一。
2.但如果竞争激烈,可以想到重试必然频繁发生,反而效率会受影响。
小结I
CAS的作用? Compare And Swap, CAS可以将比较和交换转换为原子操作,这个原子操作直接由处理器保证。
CAS的原理? CAS需要3个值:内存地址V,旧的预期值A,要修改的新值B,如果内存地址/口旧的预期值A相等就修 改内存地址值为B
锁升级过程
高效并发是从JDK 1.5到JDK 1.6的一个重要改进,HotSpot虚拟机开发团队在这个版本上花费了大量的精力去实现 各种锁优化技术,包偏向锁(Biased Locking )、
括轻量级锁(Lightweight Locking )和如适应性自旋(Ad叩tive Spinning).锁消除(Lock Elimination)、锁粗化(Lock Coarsening管,这些技术都是为了在线程之间更
高效地共 享数据,以及解决竞争问题,从而提高程序的执行效率。
无锁–》偏向锁-》轻量级锁-》重量级锁 (java15 废弃偏向锁)
偏向锁
原理
在大多情况下,锁不紧不存在多线程竞争,而且总是由同一个线程多次获得,为了让线程获得锁的代价更低,引入偏向锁。
偏向锁就是偏,偏心,偏袒。他的意思就是这个锁偏向于第一个获得他的线程,会对对象存储锁偏向的线程id,以后改线程进入和离开同步代码块只需要检查是否是偏向锁,锁标志位于以及ThreadId即可。
一旦有其他线程来竞争,立即撤销偏向锁。
偏向锁撤销
一旦有其他线程竞争线程锁。偏向锁自动撤销
1、偏向锁的撤销动作必须等待全局安全点。
2、暂停拥有偏向锁的线程,判断锁对象是否处于被锁状态。
3、撤销片线索,恢复到无锁或轻量级锁的状态。
偏向锁在java1.6之后默认启动,但是在应用该程序启动几秒钟之后才激活,可以使用XX:biasedLockingStartupDelay=0 参数关闭延迟,如果确定从应用该程序中所有锁通常情况下处于竞争状态,可以通过XX:-UseBiasedLocking=false参数关闭偏向锁。
偏向锁的好处
1 .偏向锁的撤销动作必须等待全局安全点
2 .暂停拥有偏向锁的线程,判断锁对象是否处于被锁定状态
3 .撤销偏向锁,恢复到无锁(标志位为01)或轻量级锁(标志位为00)的状态
偏向锁在Java 1.6之后是默认启用的,但在应用程序启动几秒钟之后才激活,可以使用-
XX: Bi asedLocki ngStartupDel ay=0参数关闭延迟,如果确定应用程序中所有锁通常情况下处于竞争状态,可以 通过XX: -UseBi
asedLocki ng=false参数关闭偏向锁。
轻量级锁
什么是轻量级锁
轻量级锁是JDK1.6之中加入的新型锁机制,它名字中的“轻墨级”是相对于使用monitor的传统锁而言的,因此传统 的锁机制就称为"重量级"锁。首先需要强调一点的是,轻量级锁并不是用来代普重量级锁的。
引入轻量级锁的目的:在多线程交替执^同步块的情况下,尽量避免重量级锁引起的性能消耗,但是如果多个线程 在同一时刻进入临
界区,会导致轻量级锁膨胀升级重量级锁,所以轻量级锁的出现并非是要替代重量级领。
轻量级锁原理
当关闭偏向锁功能或者多个线程竞争偏向锁导致偏向锁升级为轻量级锁,则会尝试获取轻量级锁,其步骤如下: 获取锁
1 .判断当前对象是否处于无锁状态(hashcode、0、01),如果是,则JVM首先将在当前线程的栈帧中建立一个 名为锁记录(Lock
Record)的空间,用于存储锁对象目前的Mark Word的拷贝(官方把这份拷贝加了一个 Displaced前缀,即Displaced Mark Word),将
对象的Mark Word复制到栈帧中的Lock Record中,将Lock Reocrd中的owner指向当前对象。
2 . JVM利用CAS操作尝试将对象的Mark Word更新为指向Lock Record的指针,如果成功表示竞争到锁,则将锁 标志位变成00,执行同步操作。
轻量级锁释放
羟量级锁的释放也是通过CA麋作来进行的,主要步噱如下:
1 .取出在获取轻星级锁保存在Displaced Mark Word中的数据。
2 .用CAS操作将取出的数据替换当前对象的Mark Word中,如果成功,则说明程放锁成功。
3 .如果CAS操作替换失败,说明有其他线程尝试获取该锁,则需要将轻量级锁需要澎胀升级为重量级锁。
对于轻量级锁,其性能提升的依据是“对于绝大部分的锁,在整个生命周期内都是不会存在竞争时”,如果打破这个 依据则除了互斥的开销外,还有额外的CAS操作,因此在有多线程竞争的情况下,轻量级锁比重量级锁更慢。
轻量级锁好处
在多线程交替执行同步块的情况下,可以避免重量级锁引起的性能消耗。
小结
轻量级锁的原理是什么?
将对象的Mark Word复制到栈*贞中的Lock Recod中。Mark Word更新为指向Lock Record的指针。
轻量级锁好处是什么?
在多线程交替执行同步块的情况下,可以避免重量级锁引起的性能消耗.
自旋锁
前面我们讨论monitor实现锁的时候,知道monitor会阻塞和唤醒线程,线程的阻塞和唤醒需要CPU从用户态转为 核心态,频繁的阻塞和唤醒对CPU来说是负担很重的工作,这些操作给系统的并发性能带来了很大的压力。同 时,虚拟机的开发团队也注意到在许多应用上,共享数据的锁定状态只会持续很短的一段时间,为了这段时间阻塞 和唤醒线程并不值得。如果物理机器有一个以上的处理器,能让两个或以上的线程同时并行执行,我们就可以让后 面请求锁的那个线程“稍等一下",但不放弃处理器的执行时间,看看持有锁的线程是否很快就会释放锁。为了让线 程等待,我们只需让线程执行一个忙循环(自旋),这项技术就是所谓的自旋锁。
自旋锁在JDK1.4.2中就酒引入,只不过默认是关闭的,可以使用-XX:+UsRSpinning参数来开启,在JDK 6中就 已经改为默认开启了。自旋等待不能代替阻塞,且先不说对处理器数量的要求,自旋等待本身虽然避免了线程切换 的开销,但它是要占用处理器时间的,因此,如果锁被占用的时间很短,自旋等待的效果就会常好,反之,如果 锁被占用的时间很长。那么自旋的线程只会白白消耗处理器资源,而不会做任何有用的工作,反而会带来性 能上的浪费。因此,自旋等待的时间必须要有一定的限度,如果自旋超过了限定的次数仍然没有成功获得锁,就应 当使用传统的方式去挂起线程了。自旋次数的默认值是10次,用户可以使用参数-XX: PruBlockSpin来更改
锁消除
锁消除是指虚拟机即时编译器(JIT)在运行时,对一些代码上要求同步,但是被检测到不可能存在共享数据竞争 的锁进行消除。锁消除的主要判定依据来源于逃逸分析的数据支持,如果判断在一段代码中,堆上的所有数据都不 会逃逸出去从而被其他线程访问到,那就可以把它们当做栈上数据对待,认为它们是线程私有的,同步加锁自然就 无须进行。变量是否逃逸,对于虚拟机来说需要使用数据流分析来确定,但是程序员自己应该是很清楚的,怎么会 在明知道不存在数据争用的情况下要求同步呢?实际上有许多同步措施并不是程序员自己加入的,同步的代码在 Java程序中的普遍程度也许超过了大部分读者的想象。下面这段非常简单的代码仅仅是输出3个字符串相加的结 果,无论是源码字面上还是程序语义上都没有同步。
粗化锁
JVM探测到一连串细小的操作都使用了同一个对象加锁。将同步代码块的范围放大。放到这串操作的外面,这样只需要加一次锁即可。
平时写代码如何对synchronized优化
1、减少synchronized的范围。
2、降低synchronized锁的力度。
hashtable 对所有操作都加锁。 ConcurrentHashMap 对部分加锁。使用ConcurrentHashMap
3、进行读写分离。
读时不加锁,写入和删除时加锁。
ConcurrentHashMap CopyOnWriteArrayList 和ConyOnWriteSet都是读不加锁,写的时候不加锁。
这篇关于对于Syncronized你不知道的秘密的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



![[情商-13]:语言的艺术:何为真实和真相,所谓真相,就是别人想让你知道的真相!洞察谎言与真相!](https://i-blog.csdnimg.cn/direct/4e5ed3724fee417cadec420535421736.png)





