本文主要是介绍Chipyard中的RTL Generators,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
0.概述
chipyard是一个由伯克利大学开发的RISC-V开发平台,其中包含了诸多的开源器件,其中最重要的便是Generators,下边将对各个生成器做一个简单的介绍。chipyard的介绍可以见 Chipyard------介绍与环境搭建_努力学习的小英的博客-CSDN博客
有条件的也可以去看chipyard官方手册Welcome to Chipyard’s documentation (version “1.9.0”)! — Chipyard 1.9.0 documentation
1. Rocket Chip
Rocket 芯片生成器是由伯克利开发的SoC生成器,现在由SiFive支持。Chipyard使用Rocket芯片生成器作为RISC-V SoC的基础。
Rocket Chip生成器不同于Rocket core,后者是一个顺序的RISC-V CPU生成器。Rocket Chip还包含了除CPU以外的许多SoC部分。虽然Rocket Chip默认使用Rocket core作为CPU,但也可以配置乘BOOM乱序核生成器或者其他自定义的生成器。
典型的Rocket Chip系统的详细图示意图如下:

1.1 Tiles
该图展示的是一个双核Rocket系统。每个Rocket核和一个页表行走器(page-table walker)组合在一起,L1指令缓存和L1数据缓存仅RocketTile。
Rocket核可以被替换为BOOM核,没和核还可以配置一个RoCC加速器,连接到处理器核上作为协处理器。
1.2 存储系统
所有的处理器可信连接到系统总线,系统总线将其连接到L2缓存块。L2缓存快然后连接到内存总线上,其通过一个TileLink转AXI转换器连接到DRAM控制器上。
1.3 MMIO(Memory mapping I/O)
对于MMIO外设,系统总线连接到控制总线和外设总线上。
控制总线连接到标准的外设,比如BootROM、平台级中断(Platform-Level Interrupt Controller ,PLIC)、核本地中断(core-local interrupts ,CLINT)和调试单元。
BootROM包含第一阶段的加载引导程序,当系统重启后从第一条指令开始运行。它还包含设备数,Linux使用它来确定附加的外设。
PLIC聚合和屏蔽设备中断和外部中断。
CLINT包含软件中断和每个CPU的定时器中断。
调试单元用于外部控制芯片。它可以用来将数据和指令加载到内存中或者从内存中提取数据。可以通过自定义的DMI或者标准的JTAG协议进行控制。
外围总线附加了额外的外围设备,比如NIC和块设备。与、它还可以可选的公开一个外部AXI4端口,该端口可以被附加到供应商提供的AXI4 IP。
1.4 DMA
你还可以添加DMA器件,用于直接从存储系统中读写数据。这些被添加到FrontendBus上。DrontendBus还可以通过AXI4到RileLink转换器连接到供应商的AXI4 DMA器件上。
2. Rocket 核
Rocket是一个五级顺序标量处理器核心生成器,最初由UC Berkeley开发,目前由SiFive支持。Rocket被用作Rocket ChipSoC生成器的一个组件。一个Rocket核心与L1缓存组合形成一个Rocket片。Rocket片是Rocket Chip SoC生成器中一个可复制的组件。
Rocket核支持开源RV64GC RISC-V指令集,并使用Chisel硬件构造语言所编写。其有一个支持页面的虚拟内存的MMU,一个无阻塞的数据缓存和一个具有前端的分支预测。分支预测是可配置的,可配成:分支目标缓存(BTB)、分支历史表(BHT)和返回地址堆栈(RAS)。对于浮点运算来说,Rocket使用了伯克利的Chisel浮点单元实现。Rocket还支持RISC-V及其、管理员和用户特权级别。有许多参数可以配置,包括对某些ISA扩展(M,A,F,D)的可选支持、浮点流水线级数,以及缓存和TLB的大小。
3.BOOM(Berkeley Out-of-Order Machine)
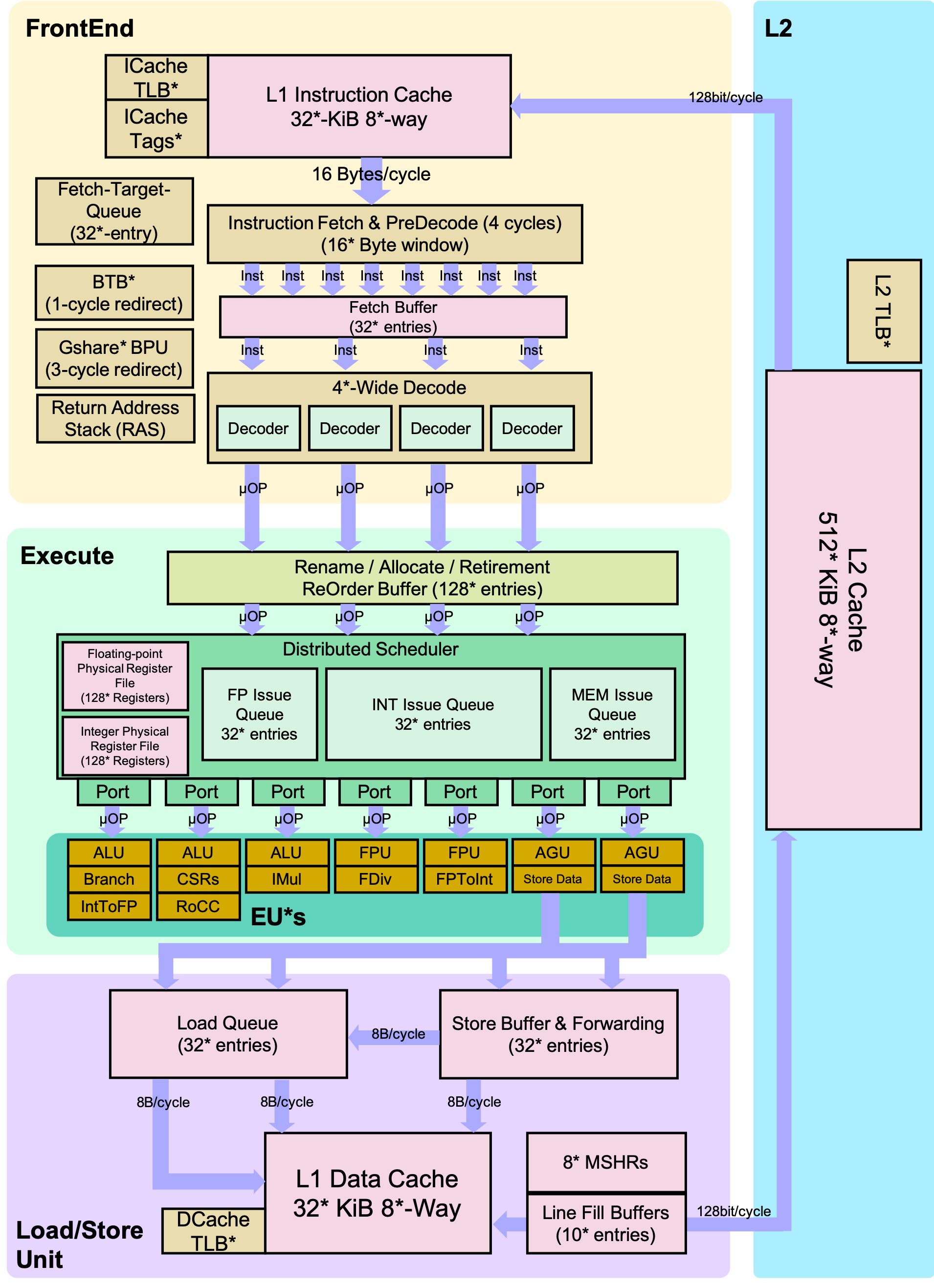
BOOM是一个可综合可参数化的开源RV64GC RISC-V核,使用Chisel硬件构造语言编写。它是服务于Rocket Chip,可以用作Rocket核的替代(即将Rocket片变为BOOM片)。BOOM在很大程度上受到MIPS R10K和Alpha 21264乱序处理器的启发。与R10K和21264一样,BOOM采用了同一的物理寄存器文件设计(也称为“显式的寄存器重命名”)。概念上讲,BOOM分为10个阶段:获取,解码,寄存器重命名,分派,发射。寄存器读,执行,内存,写回和提交。然而,当前的设计中,一些步骤被组合,现一共包括7个阶段:获取,译码/重命名,重命名/分派,发射/寄存器读,执行,内存和写回(提交是异步发生,所以不算在流水中)。
更多关于BOOM的信息,可以查阅RISC-V BOOM - RISC-V BOOM (boom-core.org)
4. Constellation
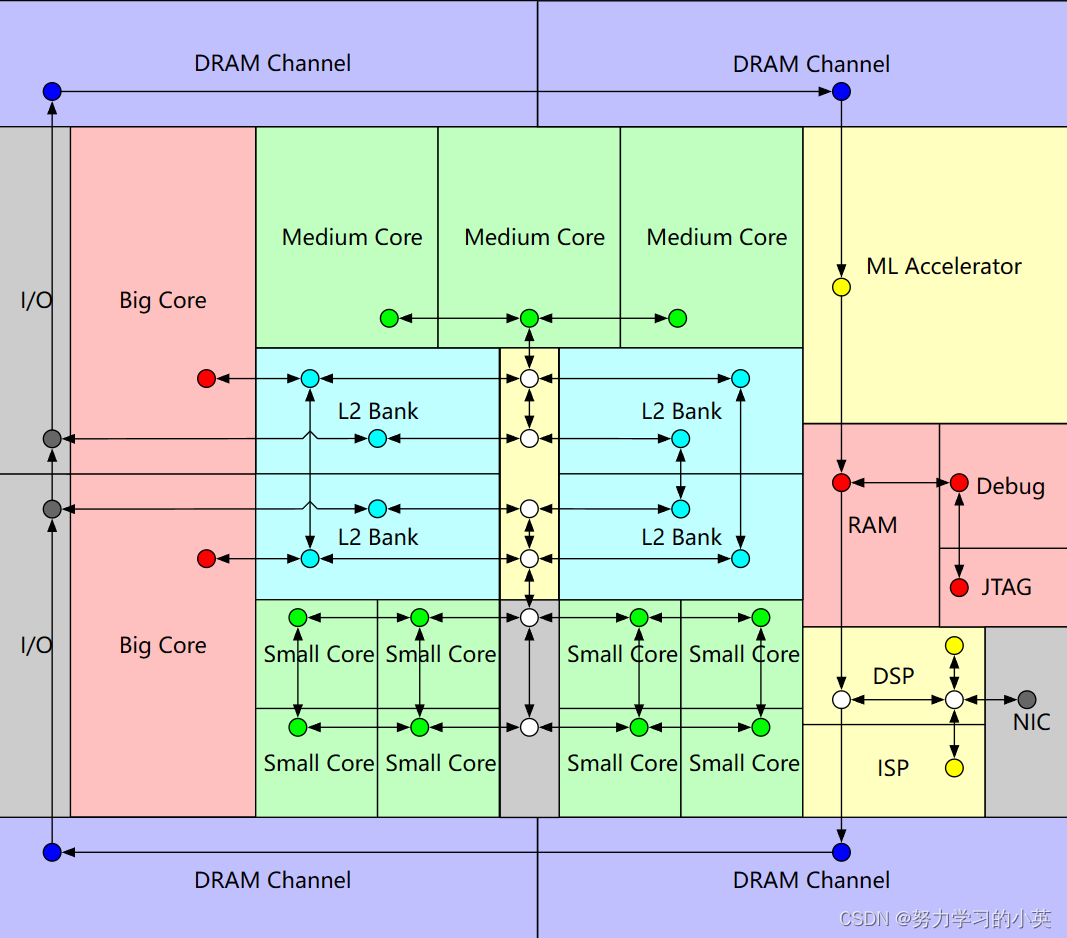
Constellation是一个Chisel NoC的RTL生成器框架,旨在支持异构SoC的集成和高度不规则NoC架构的评估上。
- Constellation通过虚拟网络和基于信用的流量控制生成包交换的虫洞路由网络
- Constellation支持任意有向图网络拓扑,包括不规则网络拓扑和分层网络拓扑
- Constellation包括路由算法验证器和路由表编译器,可以验证和生成任意拓扑的无死锁路由表
- Constellation是一个独立于协议的传输层,但能够兼容AXI-4和TileLink等协议的无死锁传输
- Constellation支持在Chipyard/Rocket Chip SoC上集成
- Constellation经过严格的测试,在许多网络配置中进行了近100种不同的测试
Constellation被完全的集成到了Chipyard中,可用于生成几乎任意基于Chipyard/RocketChip的SoC的互联。
要查阅更多有关Constellation的信息,可以查看Welcome to Constellation’s Documentation! — Constellation documentation
5. Hwacha
Hwacha项目正在为未来的计算机系统开发一种新的适量加购,该系统在功率和能源消耗方面受到限制。Hwacha项目的灵感来自于70年代和80年代的传统向量机,以及从我们之前的向量线程架构(如Scala和Maven中吸取的教训)。Hwacha项目包括Hwacha微架构生成器,以及Xhwacha非标准RISC-V扩展。Hwacha并没有实现RISC-V标准的向量扩展协议。
要了解Hwacha项目更多的信息,可以查看
要将Hwacha向量单元增加到SoC中,需要添加hwacha.DefaultHwachaConfig配置片段到SoC配置中去。Hwacha向量单元使用Rocket或者BOOM片的RoCC端口,默认情况下通过系统总线连接到内存系统(即直接连接到L2缓存)。
要更改Hwacha箱梁单元的配置,可以编写一个自定义的配置来替代DefaultHwachaConfig。可以在generators/hwacha/src/main/scala/configs.scala下查看可能的配置参数。
由于Hwacha实现的是一个非标准的RISC-V扩展,所以其需要一个特别的软件工具量来编译和组装它的向量指令。要安装Hwacha工具链,需要在Chipyard的根目录下执行./scripts/build-toolchains.sh esp-tools命令。这可能需要一段时间,它将在Chipyard根目录下安装esp-tools-install目录。esp-tools是riscv-tools(以前是RISC-V相关软件工具的集合)的一个分支,它增加了额外的非标准矢量指令。然而,由于等效RISC-V工具链的升级,esp-tools可能不会与其中包含的工具的最新主线版本保持一致。
6. Gemmini
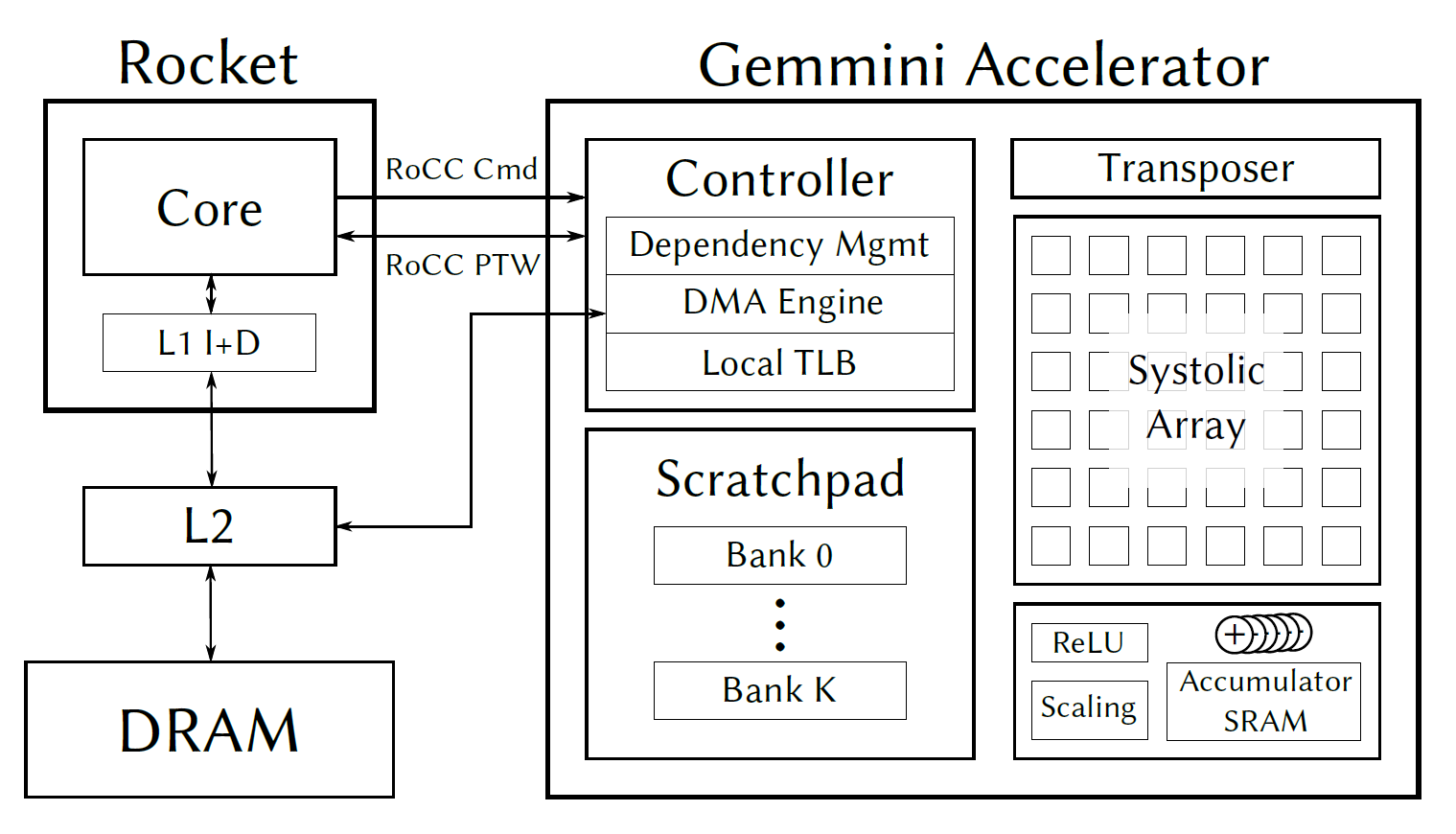
Gemmini项目是一个正在开发的全系统、全堆栈DNN硬件探索和评估平台。Gemmini使架构师可以深入了解系统和软件堆栈的不同组件(除了加速器本身外)是如何相互作用而影响DNN的整体性能的。
通过查看Gemmini的手册,可以更多的了解如何使用Gemmini和Chipyard的生成、模拟和配置DCC加速器:https://github.com/ucb-bar/gemmini/blob/master/README.md
7. IceNet
IceNet是一个与网络有关的Chisel库。IceNet的主要组件是IceNIC,是一个网络接口控制器,主要用于FireSim中进行多节点的网络模拟。IceNet的微架构图如下所示:

NIC有四个基本的组成部分:控制器,其接收并向CPU发送请求;发送路径,从内存中读取数据并将其发送到网络;接收路径,接收来自网络的数据并将其写入内存,是可选的;暂停处理城西,其为流控制的目的生成以太网暂停帧。
7.1 控制器
控制器向CPU提供了一组MMIO寄存器。设备驱动程序写入寄存器以请求发送数据包或提供内存位置以写入接收到的数据。当一个发送请求或包接收完成后,控制器向CPU发送一个中断,CPU通过从另一个寄存器读取来清除完成操作。
7.2 发送路径
发送路径开始于读取器,读取器接收来自控制器的请求并从内存中读取数据。
因为TileLink响应可能是乱序的,所以使用一个保留队列来重排序响应,以便数据包可以按适当的顺序发送出去。然后包数据进入到仲裁程序,仲裁程序可以仲裁NIC和一个或多个“tap in”的出站网络接口,这些接口来自其他可能想要发送以太网数据包的硬件模块。默认情况下,没有tap in接口,所以中采取知识简单地将保留缓冲区中的输出传递出去。
7.3 接收路径
接收路径开始于包缓冲区,其缓冲来自于网络的数据。如果缓冲区空间不足,它将以包粒度丢弃数据,以确保网卡不会发送不完整的数据包。
从数据缓冲区中,数据可以有选择性的进行网络抽头,可以用于检查以太网包头,并通过一个或者多个“抽头”选择要从NIC重定向到外部模块的数据包。默认情况下,没有输出接口,因此数据直接写入写入器,将数据谢润结存然后想控制器发送补全。
7.4 暂停处理程序
IceNic可以配置为具有暂停处理程序,该处理程序位于发送路径、接收路径以及以太网接口之间。该模块追踪接收数据包缓冲区的占用情况。如果发现缓冲区被填满,它将向网络发送一个以太网暂停帧来组织进一步的数据包发送。如果网卡接收到以太网暂停帧,暂停处理程序将组织来自于NIC的发送。
7.5 Linux驱动器
有firesim软件提供的默认Linux配置中包含了IceNet驱动器。如果你启动一个带有IceNIC的FireSim影响,驱动程序会自动检测到该设备,并且你将能够在用户空间中使用完整的Linux网络堆栈。
7.6 配置
要将IceNIC添加到你的设计中,请将HasPeripheryIceNIC添加到lazy模块中,并将HasPeripheryIceNICModuleImp添加到模块实现中。然后将WithIceNIC配置片段添加到配置中。这将定义NICKey,IceNIC使用它来确定其参数。配置片段有两个参数。inBufFlits参数是输入数据包缓冲区可以容纳的64位flits的数量,usePauser参数确定是否NIC有暂停处理程序。
8. 芯片测试IP
Chipyard提供了一个芯片测试IP库,提供了设计soc时可能会用到的各种硬件小部件。包括串行适配器、块设备控制器、TileLink SERDES,TileLink切换器、TileLink环形网络和UART是配置。
8.1 串行适配器
串行适配器被用于测试与主机处理器的通信。运行在主机CPU上的RISC-V前端服务器示例可以向串行适配器发送命令,从内存系统读取和写入数据。前端服务器使用这个功能来加载测试程序到内存中,并轮询程序的完成情况。
8.2 块设备控制器
块设备控制器提供了一个通用的二级存储接口。该接口主要用于FireSim与块设备软件仿真模型的接口上。默认的Linux配置在firesim/FireMarshal: Software workload management tool for RISC-V based SoC research. This is the default workload management tool for Chipyard and FireSim. (github.com)
要在你的设计中添加这样一个块设备,在你的配置中添加WithBlockDevice配置片段。
8.3 TileLink 串并转换器
芯片测试IP库中的TileLink 串并转换器允许将TileLink内存请求序列化,以便它们可以通过串行链路从芯片中取出。五个TileLink通道在两个SERDES通道上多路复用,每个方向一个。
库中提供了三个不同的变体,TLSerdes有一个管理器接口,在其出站链路上有通道A、C和E,入站链路上有通道B、D。TLDesser有一个客户端接口,入站链路上有A、C、E通道,出站链路上有B、D通道。最终,TLSerdesser同时具有管理借口而和客户端接口,并且开放了双向的所有通道。
8.4 TileLink切换器
当芯片有多个可能的内存接口,并且你想在启动时选择使用哪个通道来映射内存请求时,会使用到TileLink切换器。它具有一个客户节点、多个管理器节点和一个选择信号。根据选择信号的设置,来自客户端节点的请求将被重定向到一个管理器节点。必须在TileLink发送任何下次前选择设置信号,并在整个操作过程中保持未定。一旦TileLink开始发送消息,更换选择信号是不安全的。
8.5 TileLink环形网络
芯片测试IP提供了一个TLRingNetwork生成器,它具有个RocketChip提供的TLXbar类似的接口,但是在内部使用环形网络而不是较差网络。这对于具有非常宽的TileLink网络(有许多核心和L2 bank)的芯片是非常有用的,这些芯片牺牲横截面带宽来环节线路的路由阻塞。
8.6 UART适配器
UART适配器是一个存在于TestHarness中的设备,它连接到DUT的UART端口,模拟UART上的通信(例如,在Linux引导器件打印到UART)。除了使用主机的stdin/stdout外,还能够在模拟期间使用+uartlog=<NAME_OF_FILE>将UART日志输出到特定文件。
默认情况下,通过添加WithUART和WithUARTAdapter配置,可以将UART适配器添加到Chipyard的所有系统中。
8.7 SPI Flash 模型
SPI Flash模型是一个对简单SPI Flash设备进行建模的设备。目前仅支持单独、四读、单写和四写指令。内存由一个文件支持,该文件使用+spiflash#=<NAME_OF_FILE>提供,其中#是SPI Flash的ID(通常为0)。
9. SiFive生成器
Chipyard包含了几个有SiFive开发和维护的几个开源生成器。它们现在被组织在两个子模块sifive-blocks和sifive-cache中。
9.1 最后一级缓存生成器
sifive-cache包含了最后一级缓存生成器。Chipyard框架使用最后一层缓存作为L2缓存。要使用这个L2缓存,你应该添加freechips.rocketchip.subsystem.WithInclusiveCache配置片段到你的SoC配置中。
9.2 外设
sifive-blocks包含了多个外设生成器,比如UART、SPI、PWM、JTAG、GPIO等。这些外围设备通常会影响SoC的内存映射,以及它的顶层IO。为了将这些设备集成到SoC中,您需要使用Rocket Chip参数系统为该设备定义一个具有适当地址的自定义配置片段。例如,对弈GPIO设备,可以添加如下的配置片段来将GPIO地址设置为0x10012000。这个地址是GPIO配置寄存器的起始地址。
class WithGPIO extends Config((site, here, up) => {case PeripheryGPIOKey => Seq(GPIOParams(address = 0x10012000, width = 4, includeIOF = false))
})此外,如果设备需要顶层IOs,则需要定义一个配置片段来更改SoC的顶层配置。在添加顶层IO时,还需注意其是否与测试工具交互。
这个例子礼花了一个包含GPIO端口的顶层模块,然后将GPIO端口输入连接到0.最终,可以将相关的配置片段添加至SoC配置中。例子如下:
class GPIORocketConfig extends Config(new chipyard.config.WithGPIO ++ // add GPIOs to the peripherybusnew freechips.rocketchip.subsystem.WithNBigCores(1) ++new chipyard.config.AbstractConfig)Chipyard的示例项目中,一些器件设备,比如GPIO,可能已经在预定义在配置字段中。你可以直接使用这些配置字段,但是你应该直到它们在SoC中的地址映射。
10. SHA3 RoCC加速器
SHA3加速器是用于SHA3哈希算法的基本RoCC加速器。
我们喜欢在Chipyard教程内容中使用SHA3,因为它是将自定义加速器集成到Chipyard的一个独立的简单示例。
10.1 介绍
安全哈希算法代表了一类哈希函数,它们提供四个属性:哈希计算的简单性、无法从散列中生成消息(单向属性)、无法更改消息而不是哈希值(弱无冲突属性)以及无法找到具有相同散列的两条消息(强无冲突属性)。美国国家标准与技术研究院(NIST)最近举办了一场竞赛,希望将一种新算法添加到其安全哈希算法集(SHA)中。2012年,获胜者被确定为Keccak哈希函数,并建立了SHA3的粗略规范。该算法使用海绵函数对可变长度的消息进行操作,因此在将消息块吸收到一组状态位和排列状态之间进行交替。吸收是一个简单的位异或,而排列是一个更复杂的函数,由几个操作组成,χ, θ, ρ, π, ι,它们都执行各种位操作,包括旋转,奇偶校验计算,XOR等。Keccak哈希函数针对不同大小的状态和消息块进行了参数化,但对于这个加速器,我们只支持具有1600位状态和1088位消息块的Keccak-256变体。SHA3加速器的示意图如下所示。

10.2 技术细节
加速器是围绕三个子系统设计的,一个与处理器的接口,一个与内存的接口,以及实际的哈希计算系统。处理器接口采用ROCC接口设计,用于与RISC-V Rocket/BOOM处理器集成的协处理器。包括向协处理器传输两个64位字、请求返回值和请求函数的一个小字段的能力。加速器使用ready/valid接口接收这些请求。ROCC指令被解析,所需的信息被存储到执行上下文中。执行上下文包含被散列的消息的内存地址、用于存储结果散列的内存地址、消息的长度和其他几个控制字段。
一旦执行上下文有效,内存子系统就开始获取消息块。内存子系统与其他子系统完全分离,并维护一个完整的内存缓冲区。加速器内存接口每个周期最多可以提供一个64位字,对应17个请求来填充缓冲区(大小由SHA3算法决定)。填充这些缓冲区的内存请求以内存接口所能处理的最快速度发送出去,并设置了一个标记字段,以区分不同的内存缓冲区请求,因为它们可能会按顺序返回。一旦内存子系统填满了缓冲区,控制单元将缓冲区吸收到执行上下文中,此时执行上下文可以自由地开始排列,内存缓冲区可以自由地发送更多的内存请求。
缓冲区被吸收后,哈希计算子系统开始排列操作。一旦消息被完全散列,散列就会用一个简单的状态机写入内存。
10.3 使用一个SHA3加速器
由于SHA3加速器被设计为RoCC加速器,因此可以通过覆盖BuildRoCC键将其混合到Rocket或BOOM核心中。配置片段在SHA3生成器中定义。这里显示了一个突出显示此配置片段使用的示例配置:
class Sha3RocketConfig extends Config(new sha3.WithSha3Accel ++ // add SHA3 rocc acceleratornew freechips.rocketchip.subsystem.WithNBigCores(1) ++new chipyard.config.AbstractConfig)SHA3示例baremetal和Linux测试位于SHA3存储库中。请参阅其README。Md获取有关如何运行/构建测试的详细信息。
11. CVA6 核
CVA6(之前称之为Ariane)是一个6级顺序标量处理器核,最初由F. Zaruba和L. Benini在苏黎世联邦理工学院开发。CVA6核心被打包为CVA6片,因此它可以用作Rocket Chip SoC生成器中的一个组件。该核具有一个AXI接口、中断端口和其他的杂项端口,这些端口从tile内部连接到TileLink总线和其他参数化信号。
由于内核使用了AXI接口连接到内存,所以强烈推荐在单核设置中使用单核(因为AXI是一个非一致性的内存接口)
虽然CVA6核心并不是生成器,但是公开了CVA6核心提供的相同参数化(即更改分支预测参数)。
该项目不支持Verilator仿真,请使用VCS。
要查阅更多相关知识,见openhwgroup/cva6: The CORE-V CVA6 is an Application class 6-stage RISC-V CPU capable of booting Linux (github.com)
12. Ibex 核
Ibex是一个用Systemverilog编写的可参数化RV32IMC嵌入式核心,目前由lowRISC维护。Ibex核被打包在Ibex片中,所以它可以与Rocket Chip SoC生成器一起使用。该核具有一个AXI接口、中断端口和其他的杂项端口,这些端口从tile内部连接到TileLink总线和其他参数化信号。
Ibex mtvec是256字节对齐的。在编写/运行测试时,确保trap向量时256字节对齐的。
Ibex的复位向量位于BOOT_ADDR + 0x80
虽然这个核本身不是生成器,但是我们公开了Ibex核提供的相同的参数化,以便于所有受支持的Ibex配置都可以使用。
要查阅更多相关信息,见lowRISC/ibex: Ibex is a small 32 bit RISC-V CPU core, previously known as zero-riscy. (github.com)
13. FFT生成器
FFT生成器是一个参数化的FFT加速器。
13.1 配置
下面的配置创建一个8点FFT:
class FFTRocketConfig extends Config(new fftgenerator.WithFFTGenerator(numPoints=8, width=16, decPt=8) ++ // add 8-point mmio fft at the default addr (0x2400) with 16bit fixed-point numbers.new freechips.rocketchip.subsystem.WithNBigCores(1) ++new chipyard.config.AbstractConfig)baseAddress指定FFT读写通道的起始地址。FFT写通道总是位于baseAddress。每个输出点有1个读通道;因为这个配置指定了8点FFT,所以会有8个读通道。读取通道i(可以从读取输出点i加载)将位于baseAddr + 64bits(假设64bit系统)+ (i * 8)。baseAddress应该是64位对齐的。
width是二进制输入点的大小。宽度为w意味着每个点的实分量为w位,虚分量为w位,每个点总共有2w位。decPt是小数点在每个点的实值和虚值的固定精度表示中的位置。在上面的Config中,每个点的宽度为32位,其中16位用于表示实组件,16位用于表示虚组件。在每个分量的16位中,8lsb用于表示值的十进制分量,其余(8)MSB用于表示整数分量。实分量和虚分量都使用固定精度的表示。
要构建这个示例Chipyard配置的模拟,运行以下命令:
cd sims/verilator # or "cd sims/vcs"
make CONFIG=FFTRocketConfig13.2 使用和测试
点通过单写通道传递到FFT。在C伪代码中,这可能是这样的:
for (int i = 0; i < num_points; i++) {// FFT_WRITE_LANE = baseAddressuint32_t write_val = points[i];volatile uint32_t* ptr = (volatile uint32_t*) FFT_WRITE_LANE;*ptr = write_val;
}一旦传入正确的输入数量(在上面的配置中,将传入8个值),就可以从读通道读取(同样是在C伪代码中):
for (int i = 0; i < num_points; i++) {// FFT_RD_LANE_BASE = baseAddress + 64bits (for write lane)volatile uint32_t* ptr_0 = (volatile uint32_t*) (FFT_RD_LANE_BASE + (i * 8));uint32_t read_val = *ptr_0;
}测试/目录中的fft.c测试文件可用于验证fft在使用FFTRocketConfig构建的SoC上的功能。
14. NVDLA
NVDLA是有NVDIA开发的一个开源的深度学习加速器。NVDLA是作为TileLink外设连接的,因此它可以作为Rocket芯片SoC生成器中的组件使用。加速器本身公开了一个AXI内存接口(如果使用“Large”配置,则是两个)、一个控制接口和一条中断线。在Chipyard中使用加速器的主要方式是使用移植到FireSim Linux上的NVDLA SW存储库。但是,您也可以在裸金属模拟中使用加速器(请参阅tests/nvdla.c)。
有关硬件架构和软件的更多信息,请访问他们的网站:NVIDIA Deep Learning Accelerator (nvdla.org)
14.1 NVDLA软件与FireMarshal
位于software/ NVDLA -workload的是一个基于firemarshal的工作负载,用于用适当的NVDLA驱动程序引导Linux。参考README.md获取有关如何运行模拟的更多信息。
15. Sodor 核
Sodor是5个简单的RV32MI内核的集合,专为教育目的而设计。生成过程中Sodor和被打包在片中,所以它可以作为Rocket Chip SoC生成器中的组件。内核包含一个小的临时存储器,程序通过TileLink从端口加载到该存储器,并且内核不支持外部存储器。
5个可用的核心及其对应的生成器配置为:
- 1级(本质上是1个ISA模拟器)-Sodor1StageConfig
- 2级(演示了在Chisel中使用流水线)-Sodor2StageConfig
- 3级(使用了顺序内存;支持哈佛版本(Sodor3StageConfig)和普林斯顿版本(Sodor3StageSinglePortConfig))
- 5级(可以在bypass和全连锁间切换)-Sodor5StageConfig
- 基于“总线”的微编码实现-SodorUCodeConfig
更多相关信息,可以查阅:ucb-bar/riscv-sodor: educational microarchitectures for risc-v isa (github.com)
16. Mempress
Mempress是一个RoCC加速器,通过TileLink生成内存请求。它尽可能地发出请求,以压力测试基于Chipyard/ rocketchip的SoC的内存层次结构。
Mempress可以生成多个内存请求流。可以设置每个流以生成读或写请求,并配置为生成跨步或随机访问模式。此外,每个流的内存占用也是可配置的。
要将Mempress单元添加到SoC中,您应该添加Mempress.WithMemPress配置片段到SoC配置。
这篇关于Chipyard中的RTL Generators的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!
![HLS报错之:Export RTL报错 “ERROR: [IMPL 213-28] Failed to generate IP.“](https://i-blog.csdnimg.cn/direct/bb2ba2deb94f415081196fa462de6837.png)








