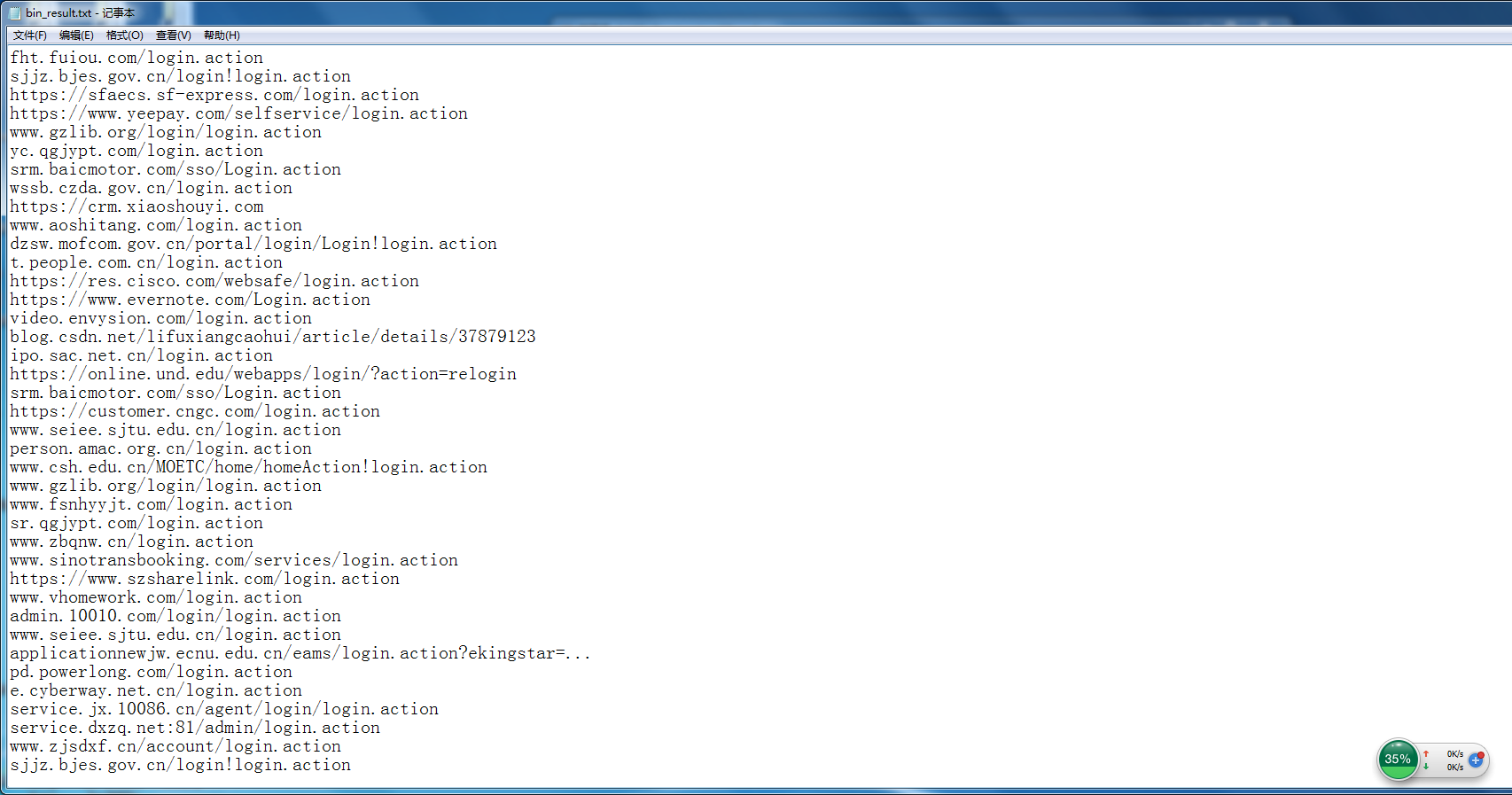
一个相当丑漏的代码, 以后有时间再优化了。
默认所有查找都是15页, 如果结果没有15页这么多估计会有重复。速度还是很快的。
sub MAIN() {my $fp = open 'bin_result.txt', :w;my $number = 15;print 'String:';my $string = get;$string = do given $string {S:g/\s/+/};use HTTP::UserAgent;my $url = 'http://cn.bing.com/search?q=';my $ua = HTTP::UserAgent.new;my $check = rx/'<'cite'>'(.*?)'</cite>'/;#要查的内容my @number = '';@number.append(0..$number);my $page='';my $html;my $target = $url~$string~'&first=20&FROM=FERE'~$page;$html = $ua.get($target).content;loop {say '===============> '~$target;$html ~~ $check;$html = $/.postmatch;#$0 = do given ~$0 {S:g/'<strong>'//;}if not $0 {#当是null时, 说明这一页已全部提取, 构造下一页$page = Int($page);my $page_next = $string~'&first='~$page~'0&FROM=FERE'~$page;$target = $url~$page_next;$html = $ua.get($target).content;$page++;#/search?q=123&first=10&FORM=PERE#/search?q=123&first=20&FORM=PERE1#/search?q=123&first=30&FORM=PERE2#/search?q=123&first=30&FORM=PERE2#last;$html ~~ $check;$html = $/.postmatch;if ($page > $number) {last;}}my $ok_check = $0.Str;my $result = $ok_check;$result = do given $result {S:g/'<strong>'//;}$result = do given $result {S:g/'</strong>'//;}say $result;$fp.say($result);}#$fp.print($html);
}


下次代码优化:
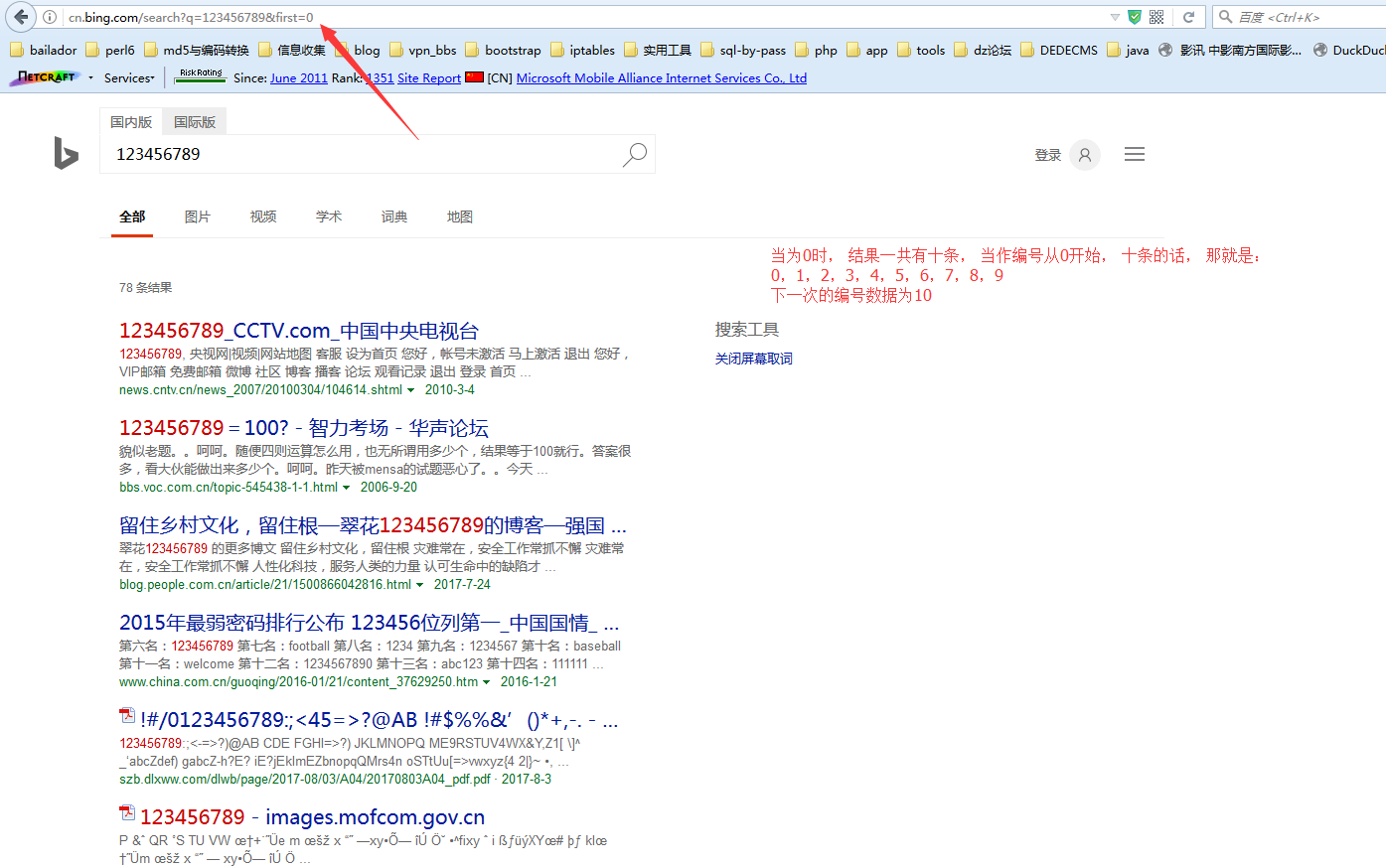
总结一下必应的规律, 如下:
http://cn.bing.com/search?q=123456789&first=1&FORM=PERE
http://cn.bing.com/search?q=123456789&first=11&FORM=PERE
http://cn.bing.com/search?q=123456789&first=21&FORM=PERE1
http://cn.bing.com/search?q=123456789&first=31&FORM=PERE2
http://cn.bing.com/search?q=123456789&first=41&FORM=PERE3
http://cn.bing.com/search?q=123456789&first=51&FORM=PERE4
http://cn.bing.com/search?q=123456789&first=61&FORM=PERE4
http://cn.bing.com/search?q=123456789&first=71&FORM=PERE4
http://cn.bing.com/search?q=123456789&first=81&FORM=PERE4
http://cn.bing.com/search?q=123456789&first=91&FORM=PERE4
在页面上测试, 参数只虽两个即可:
q=查询字符串&first=起始帐号