本文主要是介绍R语言中使用ggplot2绘制散点图箱线图,附加显著性检验,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
散点图可以直观反映数据的分布,箱线图可以展示均值等关键统计量,二者结合能够清晰呈现数据蕴含的信息。
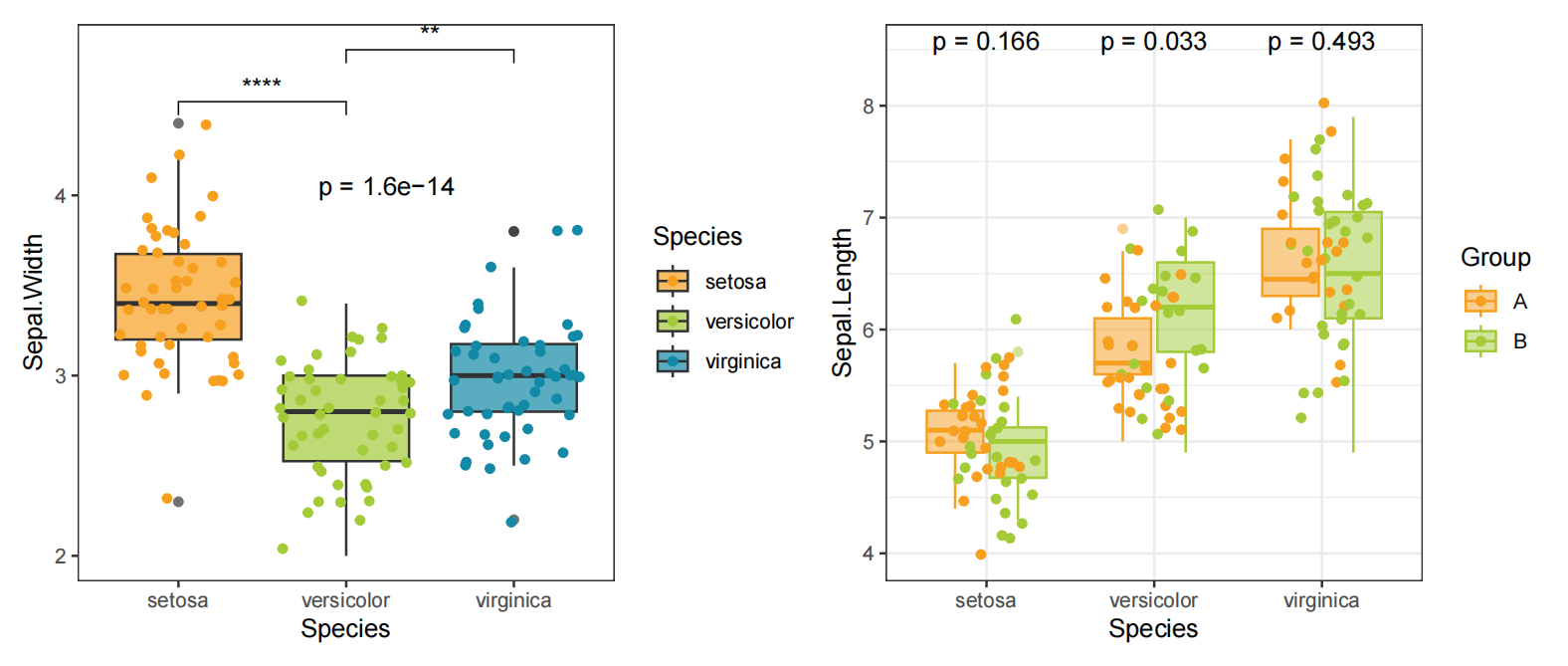
本篇笔记主要内容:介绍R语言中绘制箱线图和散点图的方法,以及二者结合展示教程,添加差异比较显著性分析,绘制如上结果图。
加载R包与数据
library(ggpubr)
library(patchwork)
library(ggsci)
library(tidyverse)
# 使用R语言自带的iris数据集,并随机分成两组
data <- iris
data$Group <- NA
data$Group[sample(1:nrow(data),size = (nrow(data)/2))] <- "A"
data$Group[is.na(data$Group)] <- "B"
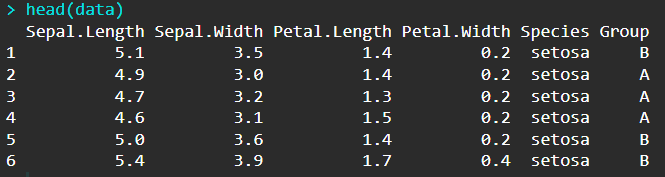 在实际数据可视化过程中,输入数据格式也和上面类似,至少有两列,其中一列是分类,另一列是数值。
在实际数据可视化过程中,输入数据格式也和上面类似,至少有两列,其中一列是分类,另一列是数值。
绘制箱线图
ggplot(data,aes(x = Species,y = Sepal.Width)) +
geom_boxplot(aes(fill = Species),alpha = 0.7)
这里将Species设置为x轴,Sepal.Width设置为y轴,箱子内部填充颜色与Species映射。 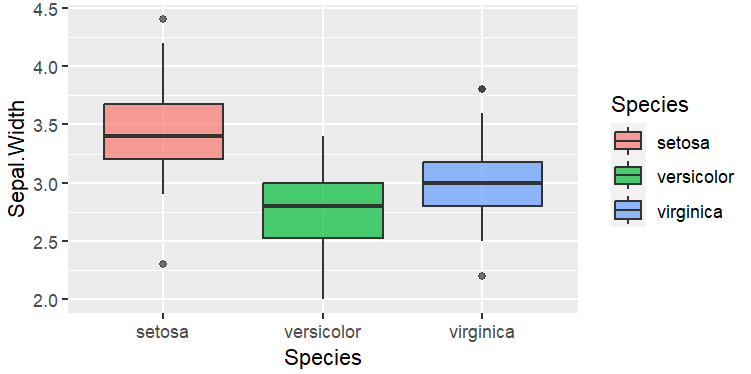
这段代码的作用是创建一个箱形图,显示不同物种(Species)的萼片宽度(Sepal.Width)分布,且不同物种的箱形用不同颜色表示,并且这些颜色半透明。
这种类型的图表通常用于展示和比较不同类别或组的数据分布情况,特别是中位数、四分位数等统计信息。
绘制散点图
ggplot(data,aes(x = Species,y = Sepal.Width)) +
geom_jitter(aes(color = Species))
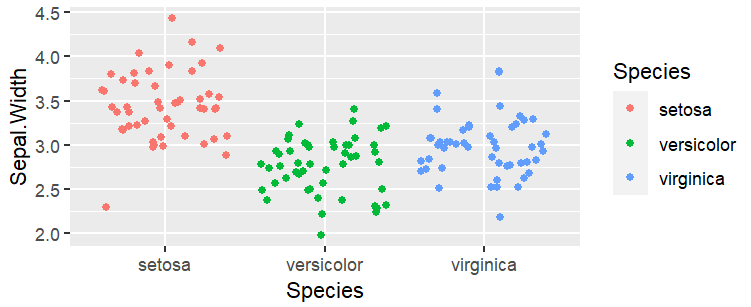
利用ggplot2包创建散点图,并通过geom_jitter功能添加一些随机噪声来分散点,以便更清晰地展示数据。
绘制箱线图+散点图
p <- ggplot(data,aes(x = Species,y = Sepal.Width)) +
geom_boxplot(aes(fill = Species),alpha = 0.7)+
geom_jitter(aes(color = Species))+
scale_fill_manual(values = c("#f79f1f","#a3cb38","#1289a7"))+
scale_color_manual(values = c("#f79f1f","#a3cb38","#1289a7"))+
theme_bw()+
theme(panel.grid = element_blank())
p
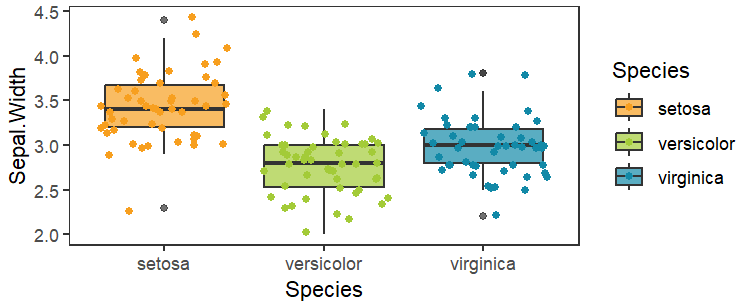
单因素多水平比较
对于两组以上的独立样品,如果数据同时满足正态性和方差齐性,可以采用方差分析(ANOVA)或者Kruskal检验,如果不满足可采用Kruskal检验。
p <- p + stat_compare_means(
method = "kruskal.test",
label = "p.format",
label.x = 2,
label.y = 4,
show.legend = F
)
p
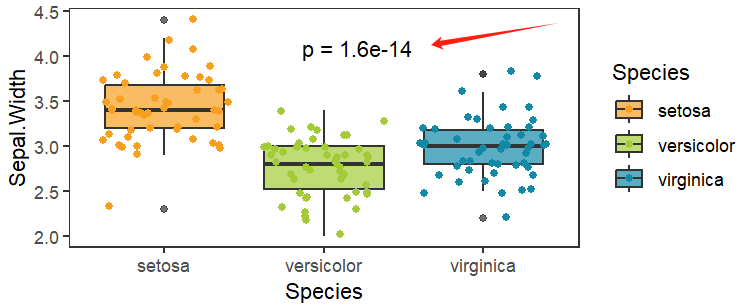
可以看到上图中自动标注的显著性P值,通过修改label参数可以转换展示方式,默认显示检验方法和p值。
p.format只显示p值不显示检验方法,p.signif显示显著性水平符号,ns: p > 0.05、*: p <= 0.05、**: p <= 0.01、***: p <= 0.001、****: p <= 0.0001。
-
method:选择统计学检验的方法
单因素两两比较
如果想看两两之间的差异显著性,例如“setosa”和“versicolor”,可以通过wilcox.test方法进行检验。
# 首先设置比较的列表
compare_list <- list(
c("setosa","versicolor"),
c("versicolor","virginica")
p <- ggplot(data,aes(x = Species,y = Sepal.Width)) +
geom_boxplot(aes(fill = Species),alpha = 0.7)+
geom_jitter(aes(color = Species))+
scale_fill_manual(values = c("#f79f1f","#a3cb38","#1289a7"))+
scale_color_manual(values = c("#f79f1f","#a3cb38","#1289a7"))+
theme_bw()+
theme(panel.grid = element_blank())+
stat_compare_means(
comparisons = compare_list,
method = "wilcox.test",
label = "p.signif")
)
代码中stat_compare_means函数提供统计学检验,调节参数可以转换方法和展示方式。 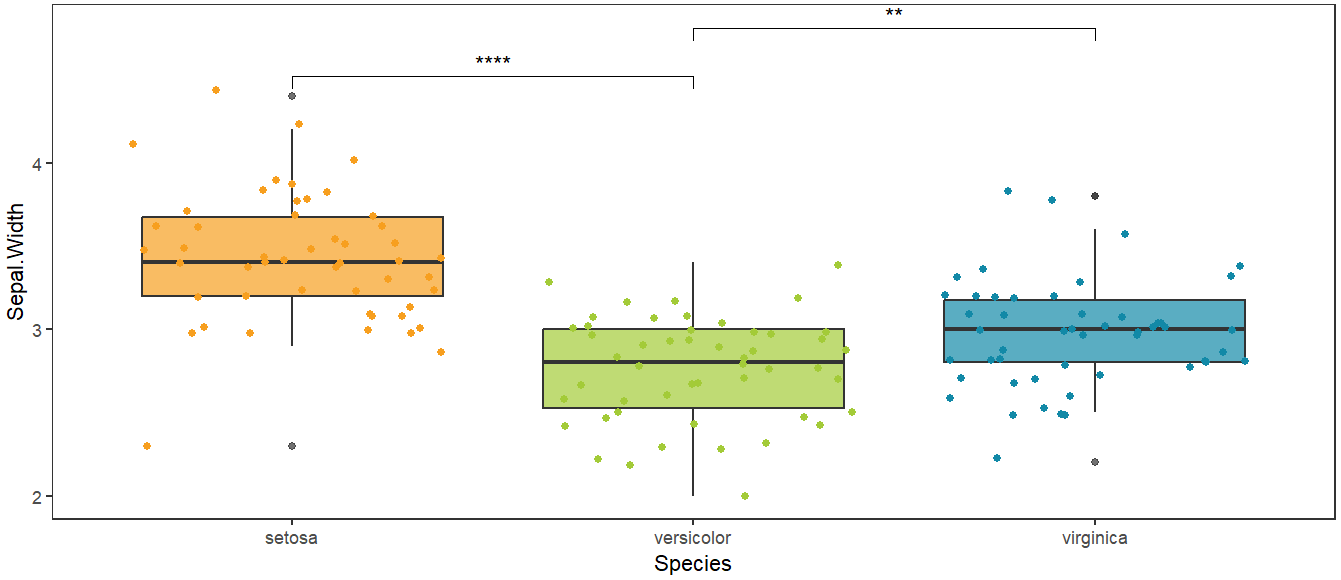
双因素组内比较
如果引入分组信息作为另外一个因素,那么可以对每个水平内两组进行比较。
p <- ggplot(data,aes(x = Species,y = Sepal.Length,color = Group))+
geom_boxplot(aes(fill=Group),alpha=0.5)
p
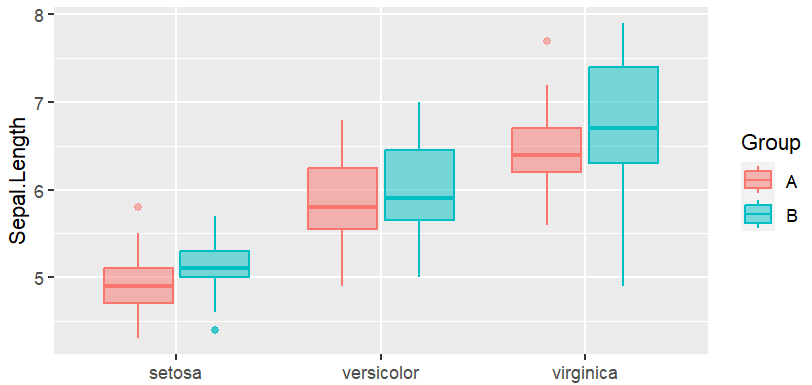
箱线 + 散点
p <- ggplot(data,aes(x = Species,y = Sepal.Length,color = Group))+
geom_boxplot(aes(fill=Group),alpha=0.5)+
geom_jitter(position = position_jitterdodge(jitter.width = 0.5,
jitter.height = 0.5,
dodge.width = 0.2))+
scale_fill_manual(values = c("#f79f1f","#a3cb38","#1289a7"))+
scale_color_manual(values = c("#f79f1f","#a3cb38","#1289a7"))+
theme_bw()
p
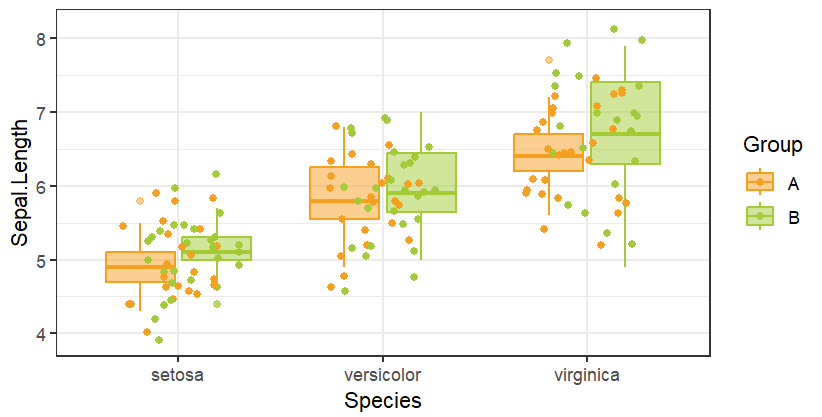
position_jitterdodge函数可以调整散点图的抖动范围,scale_fill_manual用于调整填充颜色,theme_bw用于设置主题,这段代码仅作图。
统计学检验
p <- p + stat_compare_means(
aes(group = Group),
label = "p.format",
show.legend = F,
label.y = 8.5
)
p
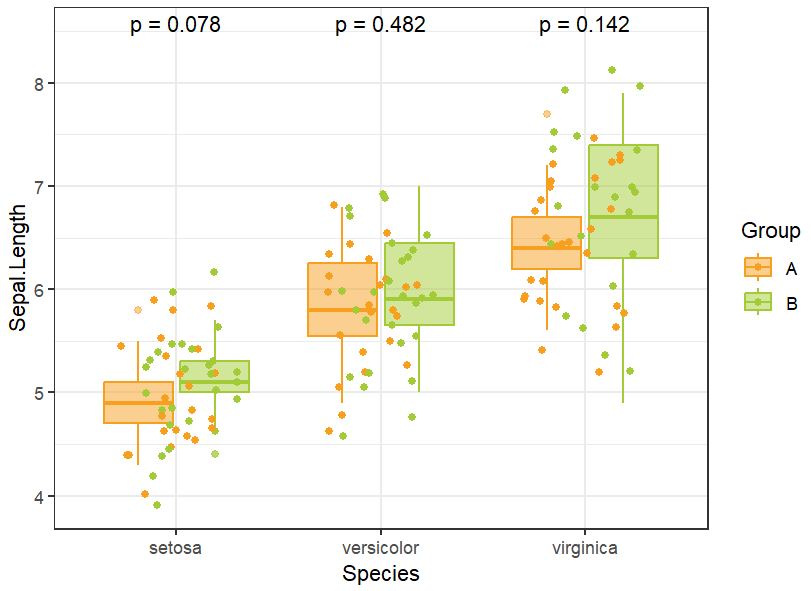
这张图x轴是不同分类,每个分类下有A和B两组,y轴表示具体的值,每个分类上有P值标注。
在实际的分析可视化过程中,还要考虑实验设计、数据分布状态等因素,合理选择检验方法,并根据目的和需求修改相应参数。
本文由 mdnice 多平台发布
这篇关于R语言中使用ggplot2绘制散点图箱线图,附加显著性检验的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





