本文主要是介绍Pandas(数据表)深入应用经验小结(查询、分组、上下行间计算等),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Pandas是Python中一个功能强大的分析结构化数据的工具集,它的使用基础是Numpy(提供高性能的矩阵运算),用于数据挖掘和数据分析,同时也提供数据清洗功能,使数据分析流程变得简单高效。
DataFrame是Pandas中的一个表格型的数据结构,包含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型等),DataFrame即有行索引也有列索引,可以被看做是由Series组成的字典。
Series是一种类似于一维数组的对象,是由一组数据(各种NumPy数据类型)以及一组与之相关的数据标签(即索引)组成。仅由一组数据也可产生简单的Series对象。
本人在实际应用中,越发感觉到此工具的强大和方便,现分享个人的经验,欢迎反馈。
1. 案例一:读写到数据表
1.1. 从Mongo DB读取数据到Pandas DataFrame
import pymongo
import xgboost as xgb
import numpy as np
from datetime import datetime
import pandas as pddef get_data():client = pymongo.MongoClient('mongodb://localhost:27017')db = client["oildepot"]collection = db["OilCanHistory"]#创建一个空的Dataframedf = pd.DataFrame(columns=('OilCanID','OilCode',...))CanStatus = {'出油':-1,'静止':0,'进油':1} #永不超时,游标连接不会主动关闭,需要手动关闭with collection.find({'OilStockCode':'K1060030002','MearsureTime':{'$gt':'2019/7/1'}},{'OilCanID':1,'OilCode':1,..},no_cursor_timeout = True).batch_size(10) as cursor: #只要程序退出了with的缩进,游标自动就会关闭。如果程序中途报错,游标也会关闭for rowdat in cursor:OilCanID = rowdat['OilCanID'] #油罐代码OilCode = rowdat['OilCode'] #油罐代码...OilCanStatus = rowdat['OilCanStatus'] #油罐状态 OilCanStatus = OilCanStatus[0:2]OilCanStatus = CanStatus.get(OilCanStatus) #转换字符串为数值... MearsureTime = MearsureTime[:MearsureTime.index(".")]#将计算结果逐行插入df,注意变量要用[]括起来,同时ignore_index=True,否则会报错,ValueError: If using all scalar values, you must pass an indexdf = df.append(pd.DataFrame({'OilCanID':[OilCanID],'OilCode':[OilCode],...}),ignore_index=True)cursor.close() #手动关闭游标 return df额外注:Mongo读数据使用游标,存在大量数据超时问题,需要设置不允许超时,但需要手动关闭游标。
1.2. 从Excel读取数据到Pandas DataFrame
def get_DataFromExcel():df = pd.read_excel('e:/Candata1.xlsx')return df
1.3. 写Pandas DataFrame数据到Excel
df1.to_excel('e:/CandINCata.xlsx')
2. 案例二:与表中上一行数据做差处理
2.1. 取上行数据构建到同一行中
基于不自己再造轮子的原则,也就不使用遍历表的方法自行编码实现“与表中上一行数据做差处理”,而是使用Pandas工具组合完成此项功能。解决方案是按条件分组数据,提取分组后各个组数据子表分布处理:

(1)计算数据列下移一行合并到表中,注意合并后表假设为A,则A首行将会出现“NaN”,需要剔除;
(2)删除A表中的首行,同理下一个表B的首行也要删除;
(3)合并所有子表为新表;

(4)表内两列间做差处理(见下一小节)。
'''
Created on 2020年8月7日
@author: xiaoyw
'''
import pymongo
import numpy as np
from datetime import datetime
import pandas as pddef add_prevdata(df):#分组,准备按分组拆分数据表 df=df.groupby('OilCanID').apply(lambda x:x.sort_values('MearsureTime',ascending=True)).reset_index(drop=True)df_group_id = df['OilCanID'] #返回是Series,取出分组标签数据df_group_id = df_group_id.drop_duplicates(keep='first') #去掉分组数据重复数据count= df_group_id.shape[0]print("Begin")df_new = pd.DataFrame() #创建空数据表,用扩展增存增加上一条记录值(移位)for i in range(count):df_tmp = df.loc[df['OilCanID']==df_group_id.iat[i]] #按油罐提取数据子表#df_tmp['precvolume'] = df_tmp['LiquidVolume'].shift(1) #下移一行df_shift = pd.DataFrame(columns=('precvolume','INCVol','preTime','INCPeriod'))df_shift.loc[:,'precvolume']= df_tmp['LiquidVolume'].shift(1) #下移一行df_shift.loc[:,'preTime']= df_tmp['MearsureTime'].shift(1) #下移一行df_tmp = pd.concat([df_tmp,df_shift],axis=1) df_tmp=df_tmp.reset_index(drop=True) #重建索引,为了删除首行,因为首行没有上一条记录值,表示为NaNdf_tmp = df_tmp.drop(index=[0]) #删除首行,因为首行没有上一条记录值,表示为NaNprint(df_tmp)df_new = df_new.append(df_tmp)print("进度为:{0:.2f}%".format(i/count*100))return df_newdf0 = get_DataFromExcel()
df1 = add_prevdata(df0)
#df1.to_excel('e:/CandINCata.xlsx')
print("End")
注:为什么不直接用“列”模式直接计算呢?
因为数据需要分组的原因,跨组数据存在不连续的情况,不知如何处理,欢迎专家赐教。
2.2. 表内同一行数据数学运算——差
def get_INCdata(df):df.loc[:,'INCVol'] = df['LiquidVolume'] - df['precvolume']df.loc[:,'INCPeriod'] = pd.to_datetime(df['MearsureTime']) - pd.to_datetime(df['preTime'])df.loc[:,'MearsureTime'] = pd.to_datetime(df['MearsureTime']).dt.datereturn df
注意数据类型,例如时间数据可能变成Object,而不能直接处理,需要转换。
3. 问题篇
3.1. 数据表更新值的问题
Python报警如下:
SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
对应报警代码和改造后代码如下所示:
#df_tmp['precvolume'] = df_tmp['LiquidVolume'].shift(1) #下移一行df_shift = pd.DataFrame(columns=('precvolume','INCVol','preTime','INCPeriod'))df_shift.loc[:,'precvolume']= df_tmp['LiquidVolume'].shift(1) #下移一行df_shift.loc[:,'preTime']= df_tmp['MearsureTime'].shift(1) #下移一行df_tmp = pd.concat([df_tmp,df_shift],axis=1) 解释:被注释掉的代码,容易出现表中数据不被更新的问题,原理见官方解释。
3.2. 数据类型问题
df0 = get_DataFromExcel()print(df0.dtypes)
df0['MearsureTime'] = df0['MearsureTime'].astype('datetime64')
| 字段名称 | 类型 |
|---|---|
| OilCanID | int64 |
| OilCode | int64 |
| MearsureTime | object |
| OilTemperature | float64 |
| OilCanStatus | int64 |
dataframe中的 object 类型来自于 Numpy, 他描述了每一个元素 在 ndarray 中的类型 (也就是Object类型)。
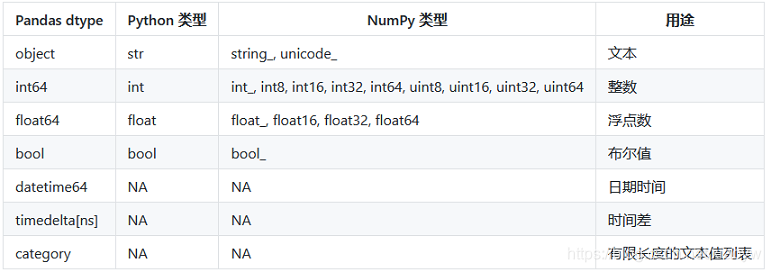
3.3. DataFrame与Series
(1)从DataFrame取出单列返回的是Series:
df_group = df['OilCanID'] #返回是Series
(2)创建无数据表时,如果是单列则是Series:
df_shift = pd.DataFrame(columns=('precvolume'))
这样的代码将报错,提示单列创建的是Series。可以使用如下方法创建空的Series。
ds = pd.Series('Name')
print(ds)
输出结果为:0 Name
欢迎大家反馈指点。
参考:
《Indexing and selecting data》 pandas.pydata.org UserGuide
《基于Pandas实现皮尔逊相关与余弦相似度在工业大数据分析中的应用实践》 CSDN博客 ,肖永威 2020年8月
《机器学习与深度学习开发环境Python3.6(win10-64)全新自主安装过程》 CSDN博客 ,肖永威 2020年7月
这篇关于Pandas(数据表)深入应用经验小结(查询、分组、上下行间计算等)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




