本文主要是介绍案例精析—2021语言与智能技术竞赛:多形态信息抽取任务,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
总结
- 文章来源:CSDN_LawsonAbs
- LawsonAbs的认知与思考,望各位读者审慎阅读。
- 本文可以看做是2021语言与智能技术竞赛:多形态信息抽取任务比赛过程的一个记录。
1 百度Baseline
百度baseline是使用paddle 写的,主要的思想是一个多层的指针网络。
1.1 关于 predicate2id.json 文件
这里针对 predicate = 配音这个就生成了如下两个 predicate 值:
配音_inwork, 配音_@value。 因为这是一个复杂的结构体,而不能简单的抽取配音就可以了。

1.2 在运行 run_duie.py 脚本时,出现如下的界面?是什么问题?

没找到是什么原因。惨!
2. 2020年的冠军解决方案
采用创新技术方案,把实体抽取任务分为主语抽取、宾语抽取和关系分类三个步骤,输出层采用机器阅读理解中的指针网络作为基本结构,有效解决了实体进行两两匹配带来的大量负样本问题,训练效果大大提升,最终取得了第一名的成绩。
3 Baseline 的错误样例分析
这些问题来源于 error case 分析
3.1 text 没有有效的分隔符(猜测)

预测结果:

这里预测结果较差,主要有两个原因:
- 因为text 间没有有效的分隔符,
- baseline 中的是 将subject 和 object 全部组合在一起,
2 噪音数据


模型能够预测出来,但是dev_train.json 中却没有给出正确的来。

上面这条数据是不是有点儿问题? 只是标注了一个西班牙语,怎么就变成了官方语言?

针对上面这条数据,我想采取一个分阶段训练的方法:
- 第一阶段大致训练一个模型
- 第二阶段开始精致调参,丢弃loss超过一定范围的数据。要保证每条数据都能被完全充分的利用
这种数据标注情况非常常见,所以一定要使用修改后的train数据来训练,否则会很影响训练效果
3.3 少字导致错误
如下面所示: 因为预测的是情人,而正确的是情人节,导致出现错误。

这个里面还有一个就是@xxx 竟然也被预测出来了。
3.4 遗漏数据
训练好的模型有很多遗漏,这里简单展示一下:



观察这么多的数据,发现原因是无法预测潜在的关系
其实模型并不知道 孙,子 的差别,它们的embedding 甚至都很相似,所以就会产生下面这种错误。

其它


这里的数字都预测错误了

隔这么远都能预测,但是预测的都是错误的,肯定是有某些数据导致产生这种问题。
遗漏的有1w条(recall很低),(即使除去官方数据中的错误标注)precision也不是很高。
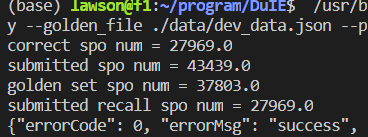
3.4 我的想法
3.4.1 噪音数据处理(未实现)
将空格,替换成[sep],或者是其它特殊字符。
3.4.2 数据迭代(未实现)
当前的模型根本是理解不了语义的,所以我认为一切的问题都是数据的问题,如果能利用好所有的正确数据,而规避错误数据集,再采用迭代训练的方式来解决这个问题。
3.4.3 dropout(未实现)
能不能 dropout 掉所有无用的数据?
4 疑问
4.1 怎么根据生成的标签,匹配出一组?
将匹配出来的subject 和 object 循环匹配即可,所以这种匹配方式可能会导致出现冗余。冗余情形如下:

4.2 如何根据predicate 的label生成最后的结果?
这个是写在baseline utils.py 下 的decoding 函数中。
5 团队方案
基于之前的冠军方案,下面介绍一下我们的方案
5.1 模型结构

总体是一个 pipeline 的方式:
- step 1. 先预测subject 【NER问题】
- setp 2. 再预测上述subject 下的所有 object 【NER 问题】
- step 3. 使用上述 subject 和 object 得到的元组,去预测二者的关系类别 【分类问题】
样例解释:
- 先预测出
宇文娥英, - 再在
宇文娥英的基础上,预测出杨丽华和周宣帝 - 再将
宇文娥英+杨丽华=>母亲,宇文娥英+周宣帝=>父亲
5.2 模型效果

precision 和 recall都很低 ,说明模型遗漏了基础要点。
5.3 模型预测结果错误样例分析
5.3.1 subject 预测的成功率不高(待解决)
单独运行 预测subject 的效果,发现其效果并不好

5.3.2 英文字符间的空格被分开了导致出错(待解决)

5.3.3 因为字不在vocab库导致出错(已解决)
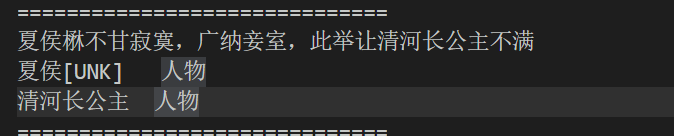
5.4 改进方案
- 使用
subject和object预测relation时,加O 类。(加一部分噪音数据构造O类) 【2021-4-11】 - 模型加CRF 【2021-4-11】
- 模型加入scheduler 参数 【2021-04-18】
pu learning【2021-04-18】- 数据迭代【2021-04-25】
- 梯度累积【2021-04-25】
- 在训练模型时使用
Sampler【2021-04-25】
5.5 其它优化方案
- 降低batch中的数据集大小
这篇关于案例精析—2021语言与智能技术竞赛:多形态信息抽取任务的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




