本文主要是介绍Frida07 - dexdump核心源码分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
项目地址
https://github.com/hluwa/frida-dexdump
代码解析
项目中的核心函数是 searchDex:
function searchDex(deepSearch) {var result = [];Process.enumerateRanges('r--').forEach(function (range) {try {....} catch (e) {}});return result;
}
里面用了一个新的API,Process.enumerateRanges,我们看一下API介绍:
enumerates memory ranges satisfying
protectiongiven as a string of the form:rwx, whererw-means “must be at least readable and writable”.
使用这个API可以在进程中搜索所有可读的内存段,我们可以直接传递 ‘r—’ 的形式,也可以传递一个对象:{protection: '---', coalesce: true } ,coalesce 的值表示是否需要合并相同权限的内存段,默认是 false。
这个函数会返回一个数组对象,里面的元素有如下属性:
-
base:基地址,NativePointer,可以理解为C里面的指针。
-
size:内存块大小,in bytes
-
protection:保护属性,string
-
file:(如果有的话)内存映射文件:
-
path,文件路径,string
-
offset,文件内偏移,in bytes
-
size,文件大小,in bytes
-
继续看源码:
Memory.scanSync(range.base, range.size, "64 65 78 0a 30 ?? ?? 00").forEach(function (match) {if (range.file && range.file.path && (range.file.path.startsWith("/data/dalvik-cache/") || range.file.path.startsWith("/system/"))) {return;}if (verify(match.address, range, false)) {var dex_size = get_dex_real_size(match.address, range.base, range.base.add(range.size));result.push({"addr": match.address,"size": dex_size});var max_size = range.size - match.address.sub(range.base).toInt32();if (deepSearch && max_size != dex_size) {result.push({"addr": match.address,"size": max_size});}}
});
又用到了一个新的API,Memory.scanSync,看看文档介绍:
scan memory for occurrences of
patternin the memory range given byaddressandsize.
就是按照 pattern 给定的模式来搜索指定范围的内存是否又匹配的。
64 65 78 0a 30 ?? ?? 00
表示搜索的模式是 以 64 65 78 0a 30 字节开头的,中间两个字节不关心,后面跟着一个 00 的8个字节,如果有满足的则触发回调。
为啥要搜索这几个字节呢?是因为这几个字节是 dex 的文件魔数。可以看下官方文档介绍:
https://source.android.com/docs/core/runtime/dex-format?hl=zh-cn

作者设置的比较宽泛,中间的两个字节表示的是 dex 的版本号,会搜索所有版本号的 dex。
文档介绍 pattern 还有一个 r2-style 的写法,但是搜了一下没看太明白,就不说了。

回调会传递一个对象,里面的属性有:
-
onMatch: function(address, size): 扫描到一个内存块,起始地址是address,大小size的内存块,返回字符串 stop 表示停止扫描
-
onError: function(reason): 扫描内存的时候出现内存访问异常的时候回调
-
onComplete: function(): 内存扫描完毕的时候调用
再回到源码:
if (range.file && range.file.path && (range.file.path.startsWith("/data/dalvik-cache/") || range.file.path.startsWith("/system/"))) {return;
}
系统app的dex,我们不需要。
if (verify(match.address, range, false)) {var dex_size = get_dex_real_size(match.address, range.base, range.base.add(range.size));result.push({"addr": match.address,"size": dex_size});var max_size = range.size - match.address.sub(range.base).toInt32();if (deepSearch && max_size != dex_size) {result.push({"addr": match.address,"size": max_size});}
}
verify 函数是对 dex 进行校验,主要是根据自己对 dex 文件的熟悉程度来做校验。
比如 dex 文件应该至少有 0x70 个字节,因为这是 dex 文件头的大小。
比如,0x3c位置的字节必定是 0x70,因为文件头后面跟着的就是字符串。
作者还开了一个深度验证,利用maps,其实原理很简单,我们使用010editor打开一个dex:

文件头里面有一个 map_off 字段,它的值是 map_list 段在dex文件内的偏移。
我们再看 map_list 段:
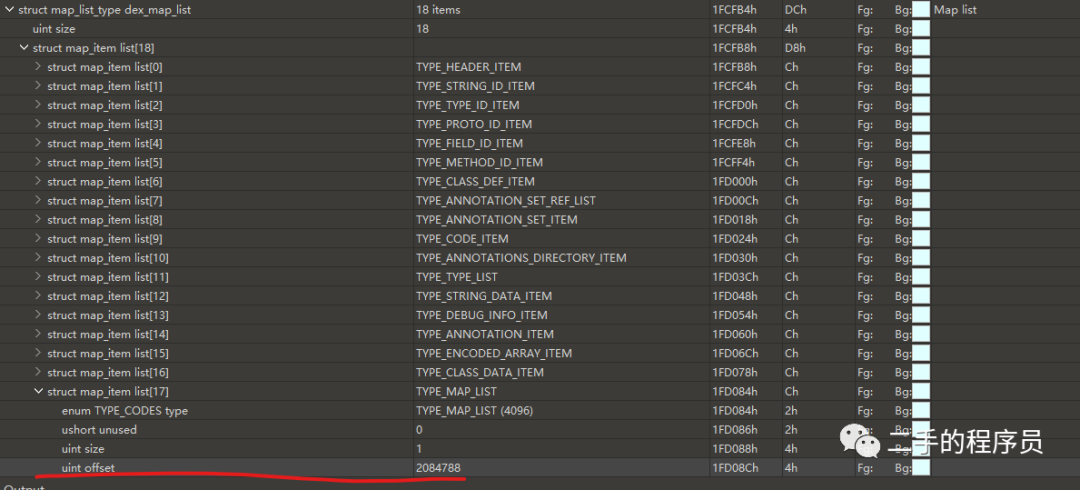
这里也储存了自身的一个偏移,那么根据这两个东西,就可以认为这个是dex文件。
具体代码如下:
function verify_by_maps(dexptr, mapsptr) {var maps_offset = dexptr.add(0x34).readUInt();var maps_size = mapsptr.readUInt();for (var i = 0; i < maps_size; i++) {var item_type = mapsptr.add(4 + i * 0xC).readU16();if (item_type === 4096) {var map_offset = mapsptr.add(4 + i * 0xC + 8).readUInt();if (maps_offset === map_offset) {return true;}}}return false;
}
然后再计算 map_list 结束的位置:
function get_maps_end(maps, range_base, range_end) {var maps_size = maps.readUInt();if (maps_size < 2 || maps_size > 50) {return null;}var maps_end = maps.add(maps_size * 0xC + 4);if (maps_end < range_base || maps_end > range_end) {return null;}return maps_end;
}
最后通过减掉起始地址,就可以得到真正的文件大小了:
function get_dex_real_size(dexptr, range_base, range_end) {var dex_size = dexptr.add(0x20).readUInt();var maps_address = get_maps_address(dexptr, range_base, range_end);if (!maps_address) {return dex_size;}var maps_end = get_maps_end(maps_address, range_base, range_end);if (!maps_end) {return dex_size;}return maps_end.sub(dexptr).toInt32();
}
如果开了深度搜索,匹配方式又有不同:
Memory.scanSync(range.base, range.size, "70 00 00 00").forEach(function (match) {var dex_base = match.address.sub(0x3C);if (dex_base < range.base) {return;}if (dex_base.readCString(4) != "dex\n" && verify(dex_base, range, true)) {var real_dex_size = get_dex_real_size(dex_base, range.base, range.base.add(range.size));if (!verify_ids_off(dex_base, real_dex_size)) {return;}result.push({"addr": dex_base,"size": real_dex_size});var max_size = range.size - dex_base.sub(range.base).toInt32();if (max_size != real_dex_size) {result.push({"addr": dex_base,"size": max_size});}}
});
70 00 00 00 是dex文件头里面字符串的偏移段。这是因为有些加固厂商会修改 dex 的魔数,所以作者选择了这种匹配方式。
可以看到,逆向的重心,除了api用的熟之外,还需要对app本身的相关知识要有足够的了解才行。
这篇关于Frida07 - dexdump核心源码分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







