本文主要是介绍Making Reconstruction-based Method Great Again for Video Anomaly Detection,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Making Reconstruction-based Method Great Again for Video Anomaly Detection
文章信息:

发表于ICDM 2022(CCF B会议)
原文地址:https://arxiv.org/abs/2301.12048
代码地址:https://github.com/wyzjack/MRMGA4VAD
摘要
视频中的异常检测是一个重要但具有挑战性的问题。先前基于深度神经网络的方法采用基于重构或基于预测的方法。然而,现有的基于重构的方法存在以下问题:1)依赖老式的卷积自编码器,在建模时间依赖性方面表现不佳;2)容易过拟合训练样本,在推断阶段导致正常和异常帧的重构误差难以区分。为解决这些问题,首先,我们从Transformer中汲取灵感,提出了一种名为Spatio-Temporal Auto-Trans-Encoder(简称为STATE)的新型自编码器模型,用于增强连续帧的重构。我们的STATE配备有一个专门设计的可学习卷积注意模块,用于高效的时间学习和推理。其次,在测试过程中,我们提出了一种新颖的基于重构的输入扰动技术,以进一步区分异常帧。在相同的扰动幅度下,正常帧的测试重构误差降低得比异常帧更多,有助于缓解重构的过拟合问题。由于帧的异常性与帧中的对象高度相关,我们使用原始帧和相应的光流补丁进行基于对象的重构。最后,异常分数是基于原始和运动重构误差的组合,使用扰动输入。在基准视频异常检测数据集上进行的广泛实验证明,我们的方法在性能上优于先前的基于重构的方法,并且在异常检测性能方面始终达到最先进水平。代码可在 https://github.com/wyzjack/MRMGA4VAD 上找到。
1.介绍
由于难以对看不见的异常进行建模[1],[2],异常检测是机器学习中一个重要但具有挑战性的领域。视频异常检测(VAD)是指识别不符合预期行为的事件的过程[3]-[6]。由于其视频监控和市政管理应用,它引起了学术界和工业界的极大关注[3],[7]。与此同时,VAD极具挑战性。
现有的方法主要分为两类:传统方法和基于深度学习的方法。传统方法在手工制作的特征[8]、[9]之上执行经典的异常检测技术。无法捕获有区别的信息使这些方法在性能上没有竞争力,劳动密集型的特征工程过程阻碍了它们的实用性和广泛应用。利用深度神经网络非凡的判别能力,基于深度学习的方法最近在VAD领域占据主导地位。基于深度学习的方法可以进一步分为基于重建的方法和基于预测的方法。基于重建[10]-[12]的方法使用自动编码器(AE)提取特征表示,并尝试重建输入。预计异常剪辑将具有比正常剪辑相对更大的重建误差。尽管如此,由于沿时间维度的推理能力较差以及卷积AE过拟合的趋势,现有的重建方法往往集中于低水平的像素误差,而不是高水平的语义特征[13]。因此,基于重建的方法最近被基于预测的方法所超越,该方法使用先前帧[13]、[14]或相邻帧[15]来预测当前帧。由于输入中不存在目标输出,基于预测的方法可以更好地建模和挖掘连续帧的时间关系。然而,基于预测的方法存在构建立方体长度短的问题,其中许多方法需要模型集成以确保高性能[14]-[17],这使得这些解决方案不可扩展,并阻碍了它们在复杂环境中的部署。
为此,我们重新思考基于重构的视频异常检测(VAD)方法,并提出了一种基于对象级重构的框架,以实现在视频中高效检测异常。具体而言,我们首先利用预训练的目标检测模型生成边界框并提取以对象为中心的patches。对于当前帧中的每个以对象为中心的patche,我们将其缩放到前一帧和后一帧,构建一个时空上下文立方体,在其中执行patche顺序重构。我们提出了一种新颖的架构,称为SpatioTemporal Auto-Trans-Encoder(STATE),以更好地建模相邻patches的时间关系。我们将Transformer中的自注意模块调整为卷积自编码器,用于原始像素和运动重构,并创新地引入卷积网络来学习时空关注。训练损失设计为原始和运动重构误差的总和。通过时空关注堆叠,我们的STATE在训练过程中能够更好地进行重构,并且在测试过程中能够更有效地通过时间轴进行推理。此外,在测试阶段,我们使用重构误差相对于输入帧的梯度添加输入扰动,以进一步减小测试重构误差。这种做法进一步扩大了正常和异常测试帧的重构误差的分布差异。通过这种方式,我们突破了基于重构的VAD方法的瓶颈,使其在VAD方面再次表现出色。
2.相关工作
A.视频中的异常检测
a) 基于重构的方法:得益于深度学习的显著成功[18]–[22],基于重构的方法在几年前开始出现。这些方法利用深度神经网络(如自动编码器(AEs))学习训练数据的正常模式,以重构视频帧。在测试阶段,如果重构误差较大,则可以区分出异常帧。例如,[10]通过引入卷积自动编码器,开创了基于AE的视频异常检测(VAD)。[11]将卷积LSTM[12]网络插入AE以更好地重构时间视频序列。[23]将AE与记忆机制结合,[24]在编码器之后设计k均值聚类以确保外观和运动对应。除了自动编码器,还利用生成模型如GANs[25]和变分自动编码器[26]进行重构。尽管它们依赖于异常事件导致较大重构误差的假设,但由于深度自动编码器的过拟合特性,这在实践中并不一定成立[13]。此外,所有上述的自动编码器方法,即使使用RNN模块,仍然在建模视频帧序列之间的时间依赖性方面表现不佳。
b) 基于预测的方法:基于帧预测的方法近来变得流行。它们学习利用先前的帧生成当前帧,而较差的预测被视为异常。[13]首次提出将帧预测方法作为VAD的基线,并选择U-Net [27]作为预测模型。[28]通过使用卷积变分RNN进一步增强了帧预测方法的性能。一个固有的想法是将基于预测的方法与基于重构的方法相结合和整合[14],[16],[17],形成所谓的混合方法。[15]提出了迭代地擦除时空立方体序列中的一帧,并利用其余部分来“预测”被擦除的帧。
B.异常检测中的输入扰动
[29]首次提出了深度学习中输入扰动的概念,以生成对抗性样本来欺骗分类器网络。这种类型的输入扰动被称为对抗性扰动,即,它被设计为通过输入空间中的梯度上升来增加损失。在分布外检测文献中,一些工作使用从预训练网络[30]–[33]获得的预测标签的最大softmax分数的梯度,对输入数据使用相反的扰动。然而,在VAD文献中,很少有人试图利用输入扰动,因为我们不能直接利用一些预先训练的网络的softmax输出。
3.方法
A.对象提取与时空上下文立方体构建
我们提出的框架的基本概要如图1所示。在[15]的做法的基础上,给定时间t的当前帧,我们利用预训练的目标检测器获取所有边界框并提取相应的前景。然后,我们将所有前景patches调整为相同的空间大小,以便于后续建模。接下来,我们为每个提取的对象前景在相同位置提取T帧向后和T帧向前的前景。通过这种方式,我们在当前帧t为该对象构建了一个长度为2T + 1的时空立方体,我们称之为时空上下文立方体(STCC)。
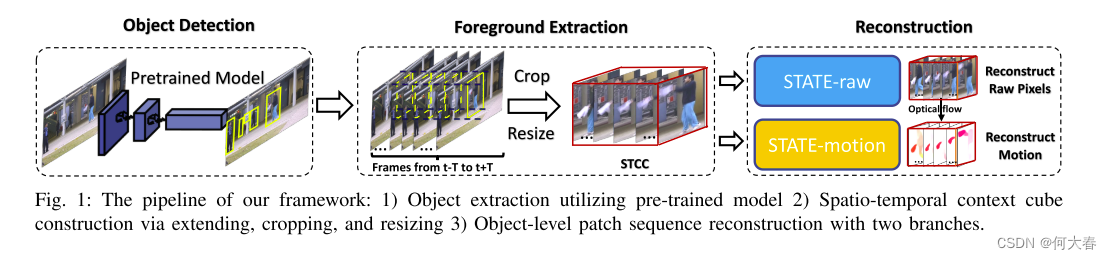
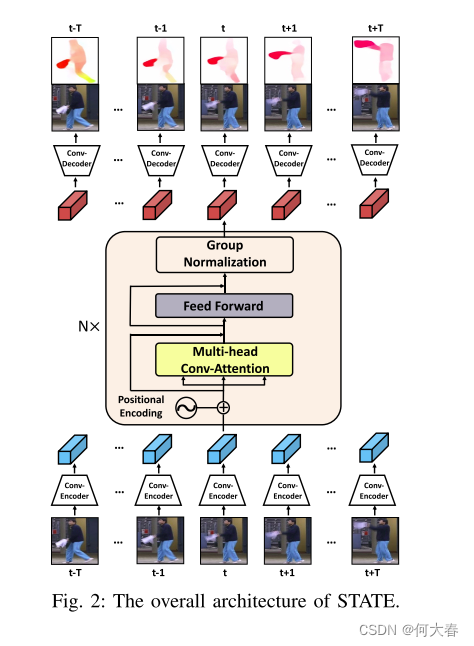
B. Spatio-Temporal Auto-Trans-Encoder
1) STATE架构概述:STATE的整个架构如图2所示。给定在时间t的STCC
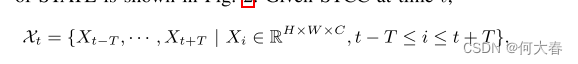
其中,H、W、C 分别表示输入patch的高度、宽度和通道数,我们首先让它们经过卷积编码器 E,生成具有代表性的缩小尺寸的特征图。相同的编码器被应用于不同位置的所有补丁,从而产生
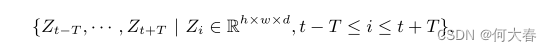
其中,h、w、d 分别是下采样特征图的高度、宽度和通道数。然后,这些特征图被送入我们独特设计的基于Transformer的注意力堆栈中,不同位置的特征图相互关联和融合。注意力堆栈的输出与它们的输入具有相同的维度大小,我们表示为
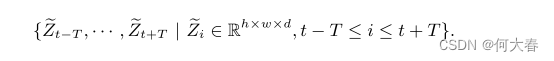
最终,在信息交换之后,这些特征图被馈送到卷积解码器D,卷积解码器D执行空间上采样,给出重建输出集
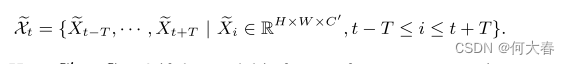
如果模型用于原始帧重构,那么C’(C撇)= C = 3;如果模型用于运动重构,那么C’ = 2。
2) Attention Stack
a) 概述:我们的注意力堆栈(图2中的方框部分)由N层组成,每一层包含两个子层。初始子层是一个多头可学习的卷积注意力模块,第二个子层是一个带有3 × 3卷积滤波器和Leaky ReLU激活函数[34]的位置感知的2D卷积前馈网络。我们在每个子层中采用了残差连接[35],并在第二个子层之后添加了组归一化[36]。为了促进残差连接,注意力堆栈中的所有子层产生通道维度为d = 128的输出,与输入特征图相同。
b) 查询(Query)、键(Key)、值(Value):类似于自然语言处理中的Transformer[37],用于一系列特征图的注意力函数也可以被描述为将一组键值对的查询映射到相应的输出。这里的查询、键、值和输出都是三维张量。给定输入的序列特征图,
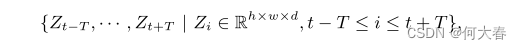
我们应用卷积神经网络 W Q W_Q WQ和 W K V W_{KV} WKV来生成查询映射和成对的键-值映射
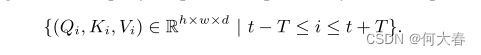
c) 位置编码:与原始的Transformer[37]不同,它将位置编码(PE)添加到输入嵌入中,我们选择在每个注意力堆栈中向查询映射Q和键映射K添加位置编码。我们提出使用可学习的位置编码(Learnable PE):一个形状为(2T + 1, d)的可学习张量嵌入。可学习位置编码的优势在于可以以数据驱动的方式学习位置关系。我们对不同的空间坐标使用相同的位置编码。
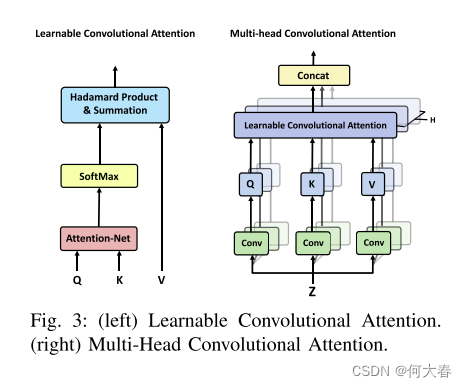
d) 多头可学习的卷积注意力:在每个注意力堆栈层中,关键组件是多头可学习的卷积注意力模块(图3),它使来自不同帧(位置)的特征图能够相互关注,并通过时间关系形成更具区分性的表示。为了生成注意力图,我们引入了一个称为“AttentionNet” F 的新型附加网络,它是一个一层的CNN,后面跟着一个3 × 3的卷积滤波器和一个Leaky ReLU激活函数。为了计算patch X i X_i Xi和 X j X_j Xj的注意力,我们首先沿着通道维度拼接第i个位置的查询映射 Q i Q_i Qi和第j个位置的键映射 K j K_j Kj。随后,我们应用F对拼接进行处理,生成一个注意力图。
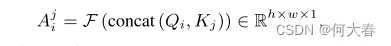
在对j从t − T迭代到t + T后,我们得到Xi的所有注意力图:{ A i t − T A^{t−T}_i Ait−T, A i t − T + 1 A^{t−T+1}_i Ait−T+1,···, A i t + T A^{t+T}_i Ait+T}。将它们连接起来,我们得到 A i A_i Ai∈ R ( 2 T + 1 ) × h × w × 1 R^{(2T+1)×h×w×1} R(2T+1)×h×w×1。为了将 A i A_i Ai的值归一化为[0, 1]范围内的权重,我们沿着第三个维度应用softmax操作:
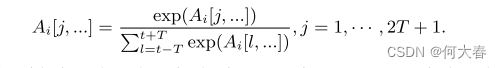
考虑到像素级别的注意力分数是使用可学习的卷积注意力生成网络产生的,我们将我们特殊的注意力称为“可学习卷积注意力”,如图3左侧所示。最终的输出可以表示为
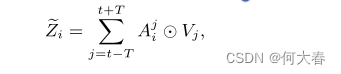
其中,符号 ⊙ 表示Hadamard乘积(逐元素乘积)。由于 A i j A^j_i Aij的最后一个维度是1,而 V j V_j Vj的最后一个维度是d,所以在乘法中存在广播。
在实际应用中,为了共同处理不同位置的不同表示空间的信息,我们采用多头注意力,如图3右侧所示:
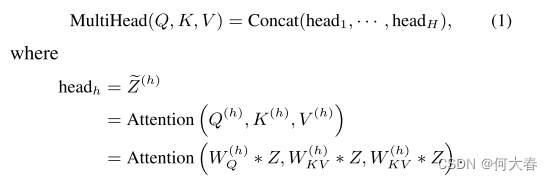
其中,H是头的数量,1 ≤ h ≤ H,* 表示2D卷积操作。对于每个 h, Q ( h ) Q^{(h)} Q(h)、 K ( h ) K^{(h)} K(h)、 V ( h ) V^{(h)} V(h) 的通道维度都是 d / H,公式(1)中的拼接是在特征图的通道维度上进行的。
3) 卷积编码器和解码器:我们STATE模型中的卷积编码器和解码器负责降低空间维度和提取深层特征。编码器E由3个层块组成。第一个块是一个具有3×3卷积滤波器和填充1的2层卷积网络。ReLU和批归一化被用于层之间。在接下来的两个块中有额外的最大池化层,以减小空间维度。解码器D在架构上与编码器E对称,前两个块执行反卷积,最后一个块仅交替通道维度。
C. Training
在训练期间,在每个帧上提取的每个对象生成STCC。因此,我们形成了STCC的数据集,在该数据集上训练我们的STATE模型。假设批量大小为N,上下文长度为T。对于1 ≤ i ≤ N,第i个STCC可以表示为 χ ( i ) \chi^{(i)} χ(i)=[ X 1 ( i ) X^{(i)}_1 X1(i),··, X 2 T + 1 ( i ) X^{(i)}_{2T+1} X2T+1(i)] T ^T T. 原始像素重建的损失函数为:
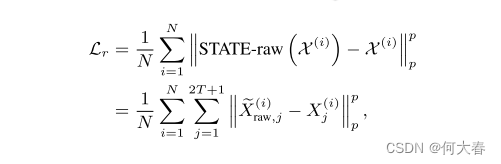
χ ~ r a w \widetilde{\chi}_{raw} χ raw表示我们的STATE模型在训练期间原始分支的输出, ∥ ⋅ ∥ p p \Vert·\Vert_p^p ∥⋅∥pp表示p范式。原始帧patch的重构描述了具有异常或异常外的异常时间(例如,自行车,车辆等)。然而,在视频中,相当大比例的异常来自于不规律的人类行为(例如,快速奔跑,投掷物体,打斗等)。为了更好地处理这类情况,我们添加了运动重构约束损失。在实践中,对于两个连续的帧,我们使用预训练的FlowNet2.0[38]模型计算前一帧的光流图作为运动信息。与 L r L_r Lr类似,运动分支损失函数设计如下:

其中, χ ~ f l o w \widetilde{\chi}_{flow} χ flow表示我们的STATE模型在训练期间运动分支的输出,而FlowNet的权重是固定的。总体训练损失是这两个损失的和。
D.基于重构的输入扰动
在测试阶段,假设预训练的对象检测器在第t帧检测到M个对象,我们可以像训练过程一样提取M个STCCs Y t ( 1 ) Y^{(1)}_t Yt(1),··, Y t ( M ) Y^{(M)}_t Yt(M)。我们将提取的相应光流图立方体表示为 O t ( 1 ) O^{(1)}_t Ot(1),··, O t ( M ) O^{(M)}_t Ot(M)。对于每个STCC Y t ( m ) Y^{(m)}_t Yt(m)(1≤m≤M),我们首先使用以下公式将输入扰动技术应用于视频序列:
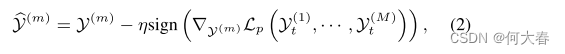
其中,sign(·)表示张量的逐元素符号,η是扰动幅度,我们利用重建误差相对于测试输入原始帧的梯度,可以计算为:
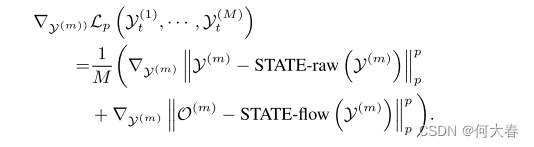
公式(2)的目标是通过在输入帧上进行一步符号梯度(注:“one-step sign gradient descent” 意味着在梯度下降的过程中只进行一次更新步骤。在这里,使用了符号梯度,即使用目标函数关于输入的梯度的符号,而不考虑梯度的大小。这是一种简化的优化方法,其目标是在输入上采取一小步以减小目标函数的值。)下降,从而减少我们的STATE模型在测试时的重构误差。我们发现通过扰动相同的幅度,正常帧倾向于比异常帧更多地减少其重构误差。
E.异常评分
根据以前基于重建的方法,我们在测试过程中使用具有扰动输入的重建误差作为异常分数。具体而言,给定时间t的第m个STCC Y t ( m ) Y^{(m)}_t Yt(m),我们采用原始patch和相应运动图的标准化分数的加权求和:
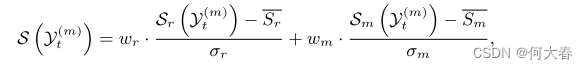
其中

是原始图和光流图的重建误差, S ‾ r \overline{S}_r Sr、 σ r σ_r σr、 S ‾ m \overline{S}_m Sm、 σ m σ_m σm是原始分支和运动分支在训练中相应得分的均值和标准差。 w r w_r wr和 w m w_m wm是可调权重。此处 Y ^ ~ r a w \widetilde{\widehat{Y}}_{raw} Y raw表示原始分支的输出, Y ^ ~ f l o w \widetilde{\widehat{Y}}_{flow} Y flow表示在使用扰动输入的测试中运动分支的输出。最后,帧得分可以被计算为所有STCC得分的最大值:
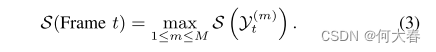
4.实验
A.数据集
我们在两个视频异常检测基准数据集上评估我们的方法,分别是 CUHK Avenue [49] 和 ShanghaiTech Campus 数据集 [48]。
B.实验步骤
在生成边界框的过程中,我们使用在 COCO 数据集上预训练的 Cascade R-CNN [50] 网络作为目标检测器。我们遵循 [15] 中的 ROI 提取算法设置,将所有置信度阈值和重叠比例设置为与 [15] 相同。对于时空上下文立方体重构,我们设置补丁大小 H = W = 32。我们设置上下文长度 T = 3 以构建 STCC。至于我们提出的模型 STATE,在两个数据集上,卷积编码器中三层块的隐藏大小为 32、64、128,解码器与编码器对称且具有相同的隐藏大小。我们为 W Q W_Q WQ 和 W K V W_{KV} WKV 配备 3×3 的卷积滤波器和 Leaky ReLU 激活。我们采用 4 个注意力头,这意味着每个头中的特征图通道数为 32。我们设置注意力堆栈数量 N = 3,epoch为 20。在我们的实验中,我们发现选择范数因子 p = 2 足以展现令人满意的性能。在训练过程中,我们采用学习率为 0.001 和 ϵ \epsilon ϵ 值为 1e−7 的 ADAM [51],[52] 优化器进行模型优化。在测试阶段,我们选择 Avenue 的扰动幅度 η = 0.002 和 ShanghaiTech 的 η = 0.005。在计算异常分数时,我们为 Avenue 设置 (0.3, 1),为 ShanghaiTech 设置 (1, 1)。为了评估异常检测性能,我们采用通过帧级准则计算的标准 ROC 曲线下的面积(AUROC)。
C.结果
我们将我们的方法与VAD中的21种SOTA方法进行了比较,其中8种是基于重建的,9种是基于预测的,4种是混合方法。结果总结在表I中。我们可以从表I中观察到,我们的方法在两个数据集上都优于所有现有方法,在Avenue上达到90.3%的AUROC,在ShanghaiTech上达到77.8%。此外,与基于重建的方法相比,我们的方法在Avenue上的AUROC提高了4.4%,在ShanghaiTech上的AUROC提高了5.5%,取得了显著的性能提升。值得注意的是,在没有输入扰动的情况下,我们的STATE模型仍然可以在Avenue上获得SOTA结果,并在ShanghaiTech数据集上获得非常有竞争力的性能。

5.结论
我们介绍了一种用于视频异常检测的对象级别的基于重构的框架。我们提出了一种新颖的基于Transformer的时空自编码器用于重构。我们进一步将输入扰动技术纳入重构误差,并成功缓解了基于重构方法的过拟合问题。实验证实了我们方法的有效性。
个人总结
创新点:
- 基于Transformer的时空自编码器
- 将输入扰动技术纳入重构误差
这篇关于Making Reconstruction-based Method Great Again for Video Anomaly Detection的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





