本文主要是介绍统计学习心法:万物皆可回归,有时可以分类,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
飞哥的文章目录
- 第一层次,入门:朦朦胧胧
- 第二层次,应用:醉里看花
- 第三层次,进阶:万物皆可回归
- 第四层次,机器学习:监督和非监督
- 应用流程
- 1. 数据接入
- 2. 数据集分割
- 3. 特征选择
- 4. 模型调用
- 5. 模型部署及应用
在一个更大的框架下学习,就像是提升了一个维度,好比你之前在二维世界中,只有前后左右,你不断的探索,不断的画平面圈,有充分的经验去描述脸大脸小,还是无法理解高鼻梁是什么意思!
《三体》小说中,三体人制造了水滴这个高科技武器,打败了人类的舰队,但是人类打败水滴,是因为进入了一段四维空间,四维空间可以看到水滴的内部,可以进入操作水滴的内部,就把水滴破坏了。
所以,学习一个大的框架,直接决定了视野的宽广与否。如果一直沉浸于方差分析和回归分析中不可自拔,有一种仰之弥高,钻之弥坚的绝望,不妨换一个框架去理解和学习。你会发现,方差分析和回归分析都属于监督学习中的回归问题,而感病与否属于监督学习中的分类问题,PCA分析和聚类分析属于非监督学习。这样,理解和学习起来就会方便很多。
第一层次,入门:朦朦胧胧
记得本科学《生物统计》,方差分析部分令人百思不得其解,拿着计算器用着各种简化的公式,来回算来算去,然后去查表,觉得生物统计完全是体力活。后来工作中,系统学习了生物统计,看了很多统计类的教科书,无非就是:描述性统计、概率分布、参数估计、假设检验、T检验、方差分析、回归分析、多元分析。
这些东西,除了方差分析和回归分析以及多元分析能用一点,其它都觉得无法实际应用,毕竟现实的数据没有那么完美,想要提高也是一头雾水。
第二层次,应用:醉里看花
随着分析项目的增加,觉得一般线性模型+混合线性模型+广义线性模型+多元分析,这个框架很好很给力。
- 一般线性模型,有一定的前提假定,像方差分析,回归分析,都是它的领域
- 混合线性模型,工作中最主要的模型,像BLUP育种值,GWAS分析,GS,都是它的领域
- 广义线性模型,主要是针对于非正态的数据,比如二项数据、分级数据,它可以指定连接函数和分布函数,也经常应用
- 多元分析,像PCA分析,因子分析,聚类分析,都是它的范围
如果再加上纵向数据分析(重复测量、时间序列)、生存分析、Mega分析,就已经是我认知的全部了。
第三层次,进阶:万物皆可回归
最开始,我以为方差分析和回归分析完全是两回事,因为方差分析是对因子处理的,而回归分析是对数值处理的。
- 比如三种药剂A,B,C,看一下对血压的控制情况,这就是一个方差分析。不同的药剂是因子变量。
- 比如身高和体重的关系,这就是一个回归分析。不同的身高是数值变量。
但是在GWAS中,两者都称为协变量,一种是数字协变量,一种是因子协变量。plink软件汇总,协变量都要变为数字协变量,如果有因子协变量需要用--dummy-coding去转化。而GCTA中有--qcovar支持数字协变量,有--covar支持因子协变量。
其实在分析时,软件都会将其变为数字协变量,之前的因子协变量会变为dummy变量(哑变量),哑变量就是数字协变量了。比如:
构建一个数据:
set.seed(123)
dat = data.frame(Treat = rep(c("A","B","C"),each=10), y = c(rnorm(10), rnorm(10)+5, rnorm(10)+10))
str(dat)
dat$Treat = as.factor(dat$Treat)
str(dat)

使用因子的Treat,进行回归分析:
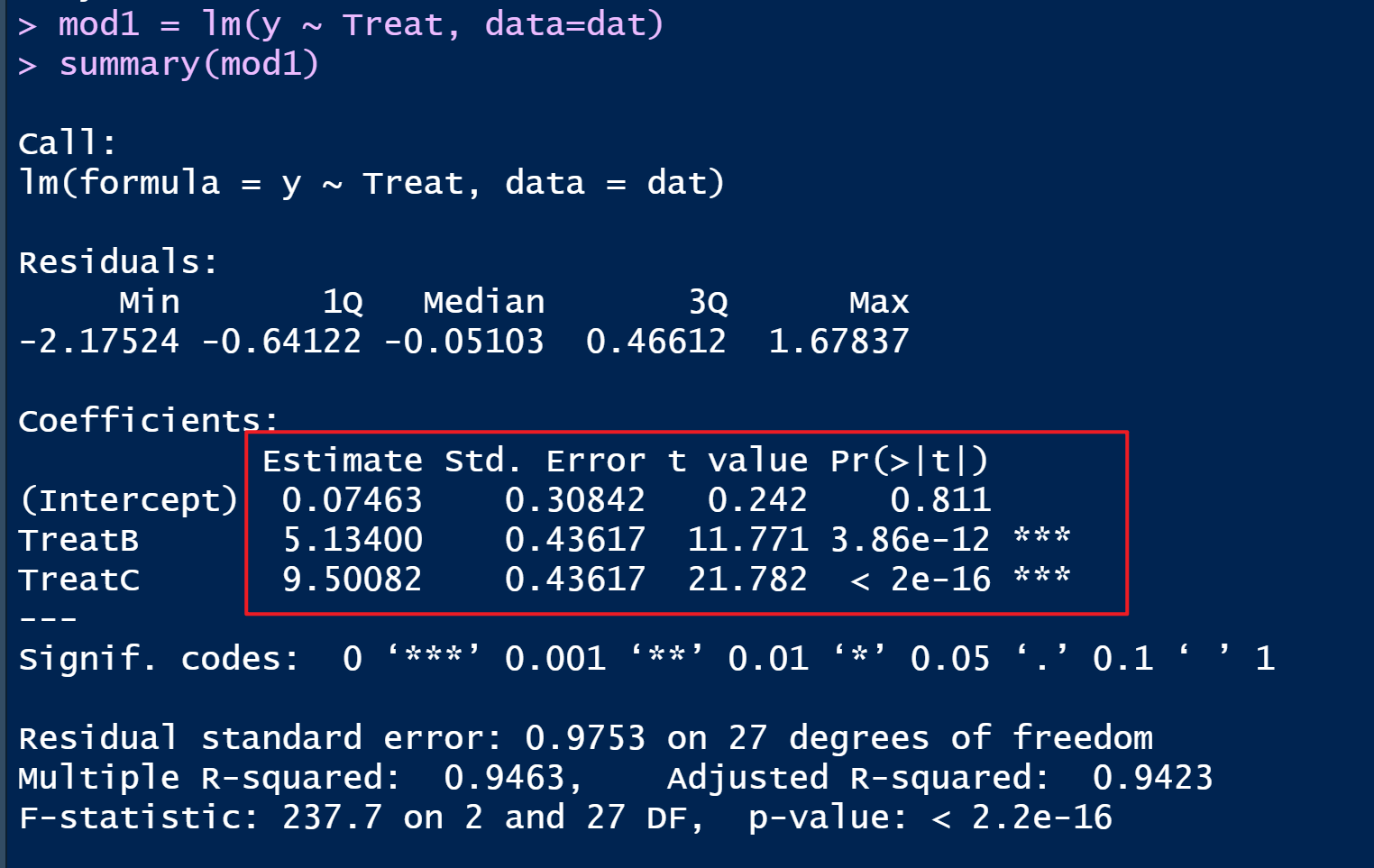
mod1 = lm(y ~ Treat, data=dat)
summary(mod1)
将其变为哑变量:
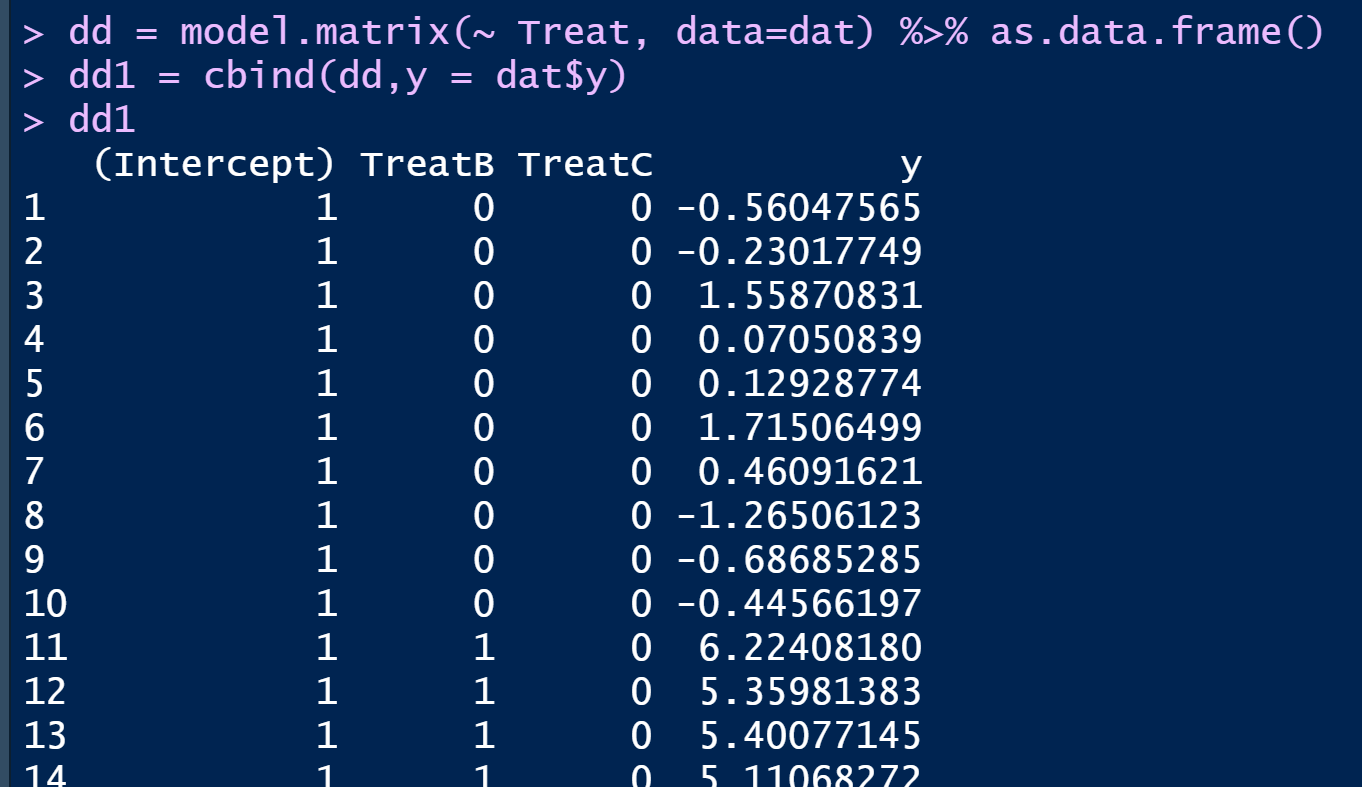
dd = model.matrix(~ Treat, data=dat) %>% as.data.frame()
dd1 = cbind(dd,y = dat$y)
dd1
对其进行回归分析,这里不考虑截距了,因为哑变量里面已经有截距了。
mod2 = lm(y ~ .-1, data=dd1)
summary(mod2)
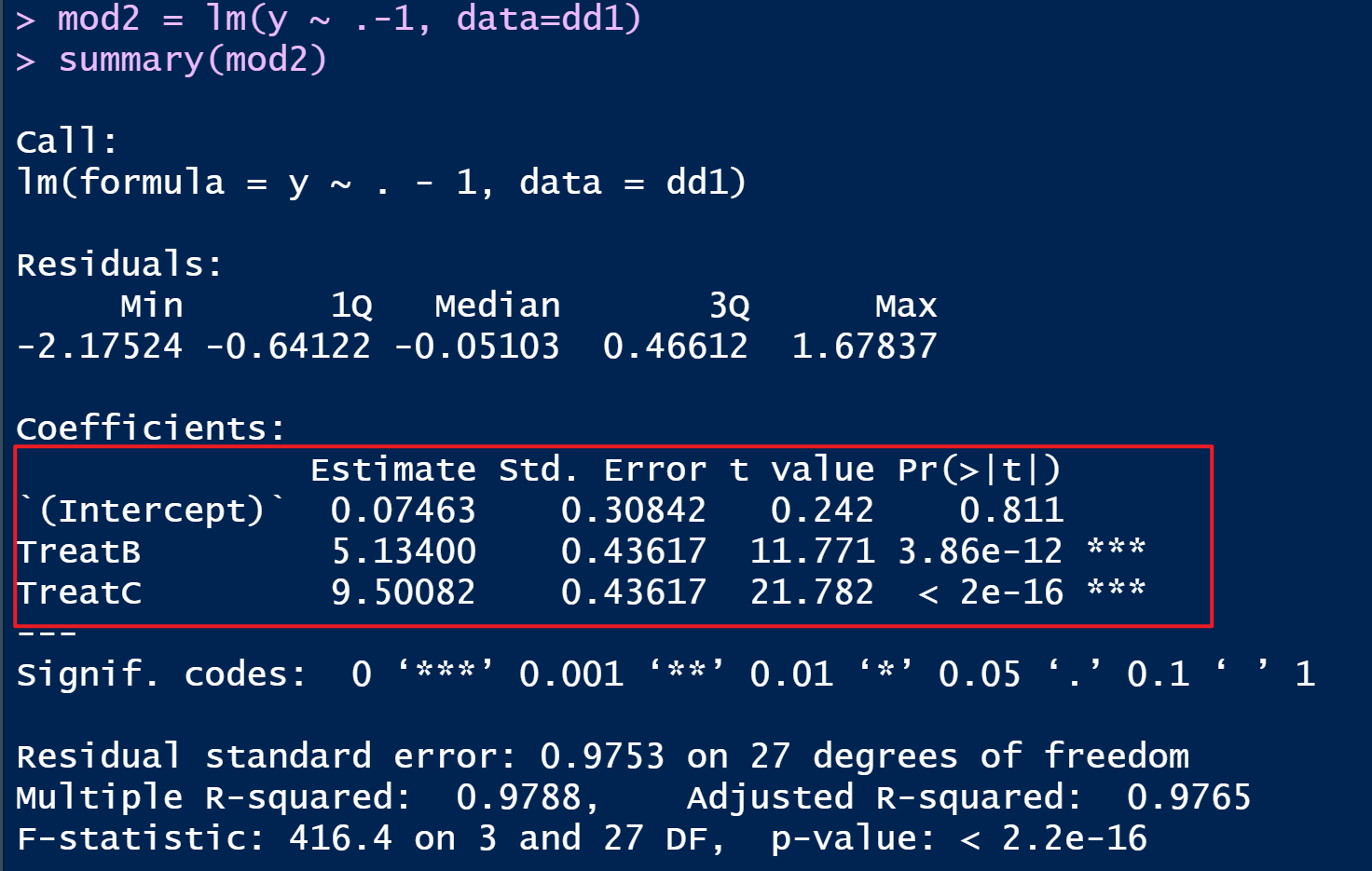
可以看到,在R语言进行回归分析时,会将因子变量变为哑变量的数字变量,然后进行回归分析。
所以方差分析只是回归分析的一种特例,在回归分析眼中,方差分析都是回归分析,万物皆可回归。
第四层次,机器学习:监督和非监督
大的框架:
整理数据集
如果对于一个人ID1,搜集了他的很多性状,比如身高、体重、性别、血压、血糖、患病与否,还有50万个SNP的分型。这些性状都是描述ID1的性状,也称为条目或者标签,也称为属性或者特征,也称为性状或者观测值。如果用机器学习的术语,就叫做标签或者特征。
因为因子协变量,都可以变为数字哑变量,所以,除了ID列,其它因子和性状,都可以变为数字的类型,都可以变为属性。
监督学习
所谓监督的学习,就是你的数据集中,包括我们需要预测的属性(比如患病与否),包括我们使用建模的属性(比如血压、50万SNP的分型)。
它又可以两种:
- 分类,所谓分类就是预测的属性(y变量)是属于两个(比如患病与否)或者多个类别(比如好、中、差),这类问题成为
分类问题。 - 回归,y变量是连续的变量,这类问题又称为
回归问题。
非监督学习
非监督学习,也叫无监督学习,它包括很多x变量的集合,但是没有明确的目标变量(y变量),这类问题的目的是挖掘数据中的相似样本的分组(比如聚类分析),或者是确定输入样本空间中的数据分布(比如密度估计),还可以将数据从高维空间投射到二维或者三维空间。我们经常使用的PCA分析,聚类分析等等。
应用流程
1. 数据接入
数据读取或者导入,需要将数据数字化,将SNP分型变为0-1-2的编码,将性别变为1-2的编码,将固定因子变为哑变量的编码,最后的数据格式都是数字列。
2. 数据集分割
我们建模时,需要参考群和验证群,用于评价模型的好坏,可以对数据进行分割。
3. 特征选择
有时候,我们面对的是很多属性(变量)的数据,为了降低模型学习的难度,提升训练效率,会对变量进行特征工程操作,一般分为:特征选择和特征抽取,两者都是降维的方法。
- 特征选择:特征选择后的特征,是原来特征的一个子集。本身没有变化,比如对基因型数据进行maf、geno的质控,去掉一些位点。
- 特征抽取:特征抽取后的新特征是原来特征的一个映射。本身已经变化了,比如PCA分析,得到的是PC1,PC2,这些不是原来特征的子集。
常用的特征选择的方法有:
- 方差阈值特征选择,该方法是删除方差达不到阈值的特征,默认情况下,删除所有方差是0的特征,比如maf=0时,位点在所有的样本中都没有多态,不删除留着过年吗?
- 单变量的特征选择,根据属性的统计指标,对属性进行排序,进行选留。比如maf是一个指标,P值是一个指标等
- 循环特征选择,将多个属性放在一起进行检验,比如在一定的窗口内进行LD筛选
- 针对线性模型的特征选择
- 基于决策树的特征选择
4. 模型调用
这里,就可以选择模型了,是用广义线性模型(线性回归、逻辑回归、岭回归等),还是用支持向量机(SVM),决策树,随机森林等。
然后是调参。
交叉验证,选择最优模型
5. 模型部署及应用
选择最优模型之后,就可以写成pipeline了。
这篇关于统计学习心法:万物皆可回归,有时可以分类的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





