本文主要是介绍爆肝!回调函数的实用案例,建议收藏~(计算器改良,qsort快排函数应用实例,冒泡函数核心理解,模拟qsort函数),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
这里是目录哟~
- 一、回调函数的实用案例
- 1.0 回调函数简要介绍
- 1.1 简易计算器改良
- 1.2 qsort快排函数应用回调函数
- 1.2.1 冒泡排序核心思想
- 1.2.2 qsort函数简单介绍
- 1.2.2.1 qsort函数对浮点型数组排序实例
- 1.2.2.2 qsort函数对结构体数组排序实例
- 1.2.3 利用冒泡排序算法实现qsort函数的模拟
一、回调函数的实用案例
1.0 回调函数简要介绍
回调函数是一个通过函数指针调用的函数。
意思是定义一个指针,这个指针指向一个函数,然后用这个指针来调用这个指针所指向的函数。
看上去十分容易,那只是你的脑子在欺骗你,你的手完全不会。[doge]
1.1 简易计算器改良
大多数初学者刚接触函数的时候一定写过简易的计算器,来实现加减乘除四则运算 , 虽然写得很繁琐 ,但依旧无法阻止我们产生学习编程的热情。
#include<stdio.h>
void menu()
{printf("*********************\n");printf("****1.Add 2.Sub****\n");printf("****3.Mul 4.Div****\n");printf("****** 0.Exit *******\n");printf("*********************\n");
}
int Add(int x, int y)
{return x + y;
}
int Sub(int x, int y)
{return x - y;
}
int Mul(int x, int y)
{return x * y;
}
int Div(int x, int y)
{return x / y;
}
int main()
{int input = 0;int x = 0;int y = 0;int ret = 0;do{menu();scanf("%d", &input);switch (input){case 1:printf("input two numbers\n");scanf("%d %d", &x, &y);ret = Add(x, y);printf("%d\n", ret);break;case 2:printf("input two numbers\n");scanf("%d %d", &x, &y);ret = Sub(x, y);printf("%d\n", ret);break;case 3:printf("input two numbers\n");scanf("%d %d", &x, &y);ret = Mul(x, y);printf("%d\n", ret);break;case 4:printf("input two numbers\n");scanf("%d %d", &x, &y);ret = Div(x, y);printf("%d\n", ret);break;case 0:printf("Exit\n");break;default:printf("再乱输我就要生气咯!\n");break;}} while (input);return 0;
}
但这样冗余的代码就像老太太的裹脚布又臭又长 。
我在写的时候发现了有多个地方一直在重复一个操作,就是在case子句中一直重复着让让用户输入两个操作数,并且打印出来。
(虽然这个操作可以复制粘贴 )但是节约是一种美德,节约内存空间也是[doge]
- 懒,才能推动进步
我要尝试简化这个部分的代码,我发现case子句中只有函数的调用不同,所以我将不同函数作为一个参数传给我的一个自定义函数,于是case子句中的内容就变为如下形式
ret = Calc(Add);
printf("%d\n", ret);
那么问题来了,函数名代表什么呢?
众所周知,数组名代表数组的首元素地址,那函数名也应该如此,代表函数的地址
那么,我们的自定义函数中的参数应该设计成一个函数指针
int Cal((*fun)(int, int));
这么长一串的东西应该怎么来分析呢?
首先看参数部分,参数是一个函数指针,即一个指针,所以其变量名应该先于‘ * ’结合,并且被括号括起来,因为‘ * ’的优先级特别低。
然后其右边与()结合,代表这是个指向函数的指针,这个()是参数列表,列表内有两个整形参数。
最后再看返回值,实行计算后返回一个整形数据。
简易改良版如下:
#include<stdio.h>
int Add(int x, int y)
{return x + y;
}
int Sub(int x, int y)
{return x - y;
}
int Mul(int x, int y)
{return x * y;
}
int Div(int x, int y)
{return x / y;
}
void menu()
{printf("*********************\n");printf("****1.Add 2.Sub****\n");printf("****3.Mul 4.Div****\n");printf("****** 0.Exit *******\n");printf("*********************\n");
}
int Cal(int(*fun)(int, int))
{int x = 0;int y = 0;printf("input two numbers\n");scanf("%d %d", &x, &y);return fun(x, y);
}
int main()
{int input = 0;int x = 0;int y = 0;int ret = 0;do{menu();scanf("%d", &input);switch (input){case 1:ret = Cal(Add);printf("%d\n", ret);break;case 2:ret = Cal(Sub);printf("%d\n", ret);break;case 3:ret = Cal(Mul);printf("%d\n", ret);break;case 4:ret = Cal(Div);printf("%d\n", ret);break;case 0:printf("Exit\n");break;default:printf("再乱输我就要生气咯!\n");break;}} while (input);return 0;
}
1.2 qsort快排函数应用回调函数
众所周知,排序是很重要的,初学者一般就接触过选择排序和冒泡排序,其中冒泡排序估计是强行硬是把代码背下来了。
下面还是希望能用通俗易懂的图文带大家深入理解一下冒泡排序的核心思想。
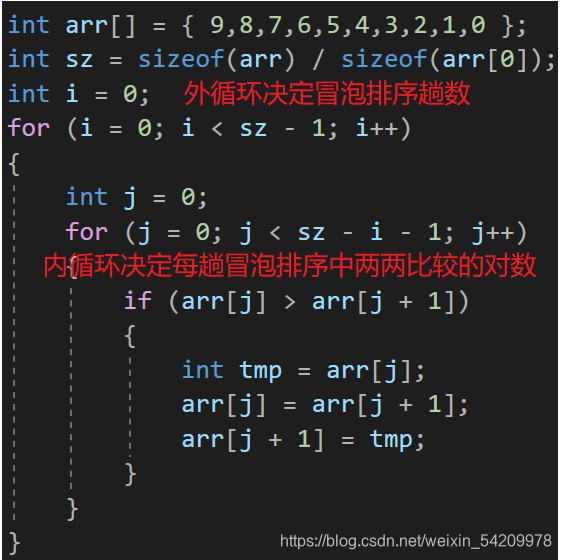
1.2.1 冒泡排序核心思想
相邻两数比较,大数往后挪,就像是重的石头沉入水底,轻的气泡往上浮。
把每一次最重的石头沉入它应该到的位置时的这个过程称作一趟冒泡排序,那么多少趟下来才能将所有元素放在各自应该到的位置呢?很显然,如果10个元素,只需要把九个元素放在其应该所在的位置即可,那么剩下的一个元素当然只有唯一的位置放了,而那个位置恰好就是该剩下的元素的最终位置,10个元素完成升序也就需要9趟冒泡排序。
再来细说每一趟冒泡排序是如何实现的,从第一个元素开始,相邻的两元素两两比较,如果前面元素大于后面元素,则两元素交换位置,如果前面元素小于后面元素,则不交换位置,一直比较到最后一个元素,这就是第一趟冒泡排序。
而紧接着下一趟冒泡排序略微有些不同,一开始还是依次两两比较,但是不需要比较数组中的最后一个元素,因为在第一趟的冒泡排序中,我们已经将一个最大的数放在最后了,所以它已经到自己最终的位置,我们就不再管它了。
1.2.2 qsort函数简单介绍
qsort函数是C的一个库函数,头文件为#include<stdlib.h>
这里推荐一个程序员必备的库函数查询网址
链接: http://www.cplusplus.com/
可以查询C\C++的库函数的用法,非常方便,值得放进收藏夹。
如下是qsort函数的函数声明:


qsort函数的第四个参数是一个函数指针,指向的是一个程序员根据需要排序的数组类型来写的函数。
正因为如此,qsort才能实现对不同的数据类型进行灵活排序
1.2.2.1 qsort函数对浮点型数组排序实例
#include<stdio.h>
#include<stdlib.h>
int SortByDouble(const void* e1, const void* e2)
{return *(double*)e1 - *(double*)e2;
}
int main()
{double arr[] = { 9.0,8.0,7.0,6.0,5.0,4.0,3.0,2.0,1.0 };int sz = sizeof(arr) / sizeof(arr[0]);qsort(arr, sz, sizeof(arr[0]), SortByDouble);return 0;
}
注意:void*可以接受任何指针类型,但是不可以对其进行解引用操作,但是可以对其接受到的指针类型进行强制类型转换,即如上自定义函数SortByDouble中的return部分。
1.2.2.2 qsort函数对结构体数组排序实例
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
struct stu
{char name[8];int age;
};
int SortByAge(const void* e1, const void* e2)
{return ((struct stu*)e1)->age - ((struct stu*)e2)->age;
}
int SortByName(const void* e1, const void* e2)
{return strcmp(((struct stu*)e1)->name, ((struct stu*)e2)->name);
}int main()
{struct stu s[] = { {"zhangsan",20},{"lisi",19},{"wangwu",18} };int sz = sizeof(s) / sizeof(s[0]);qsort(s, sz, sizeof(s[0]), SortByAge);qsort(s, sz, sizeof(s[0]), SortByName);return 0;
}
结构体就更加复杂了,而且需要小心算结构体数组元素个数和每个元素大小的时候都是不管结构体的成员变量。
所以千万不要以为自己是在对结构体中的年龄进行排序,而计算数组大小的时候用了:
int sz = sizeof(s)/sizeof(s[0].age);//错误实例
不应该去让s[0]访问到age
还有一点是结构体定义一定要放在最前面,放错位置了,都会导致自定义函数显示未定义的错误
1.2.3 利用冒泡排序算法实现qsort函数的模拟

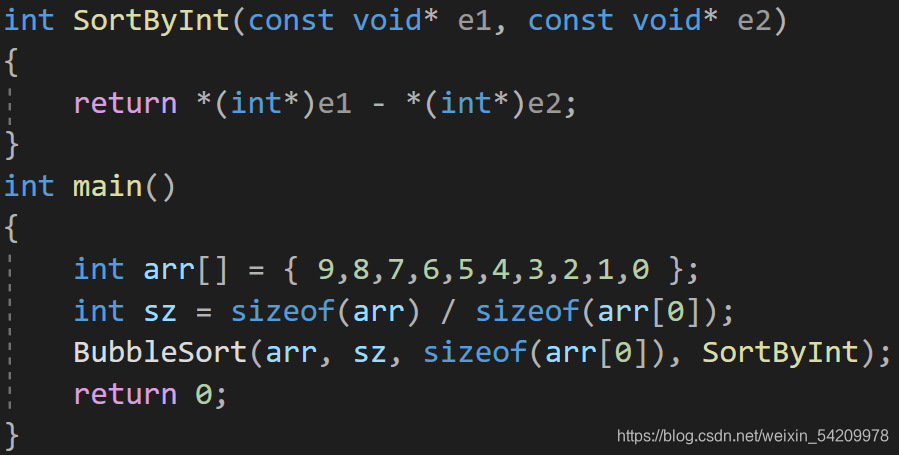
其实qsort函数的算法并不是冒泡排序,但我为什么说是模拟实现qsort呢?
请看下图:
发现了吗?我写的这个函数的参数简直就是和qsort函数的参数异曲同工之妙啊~
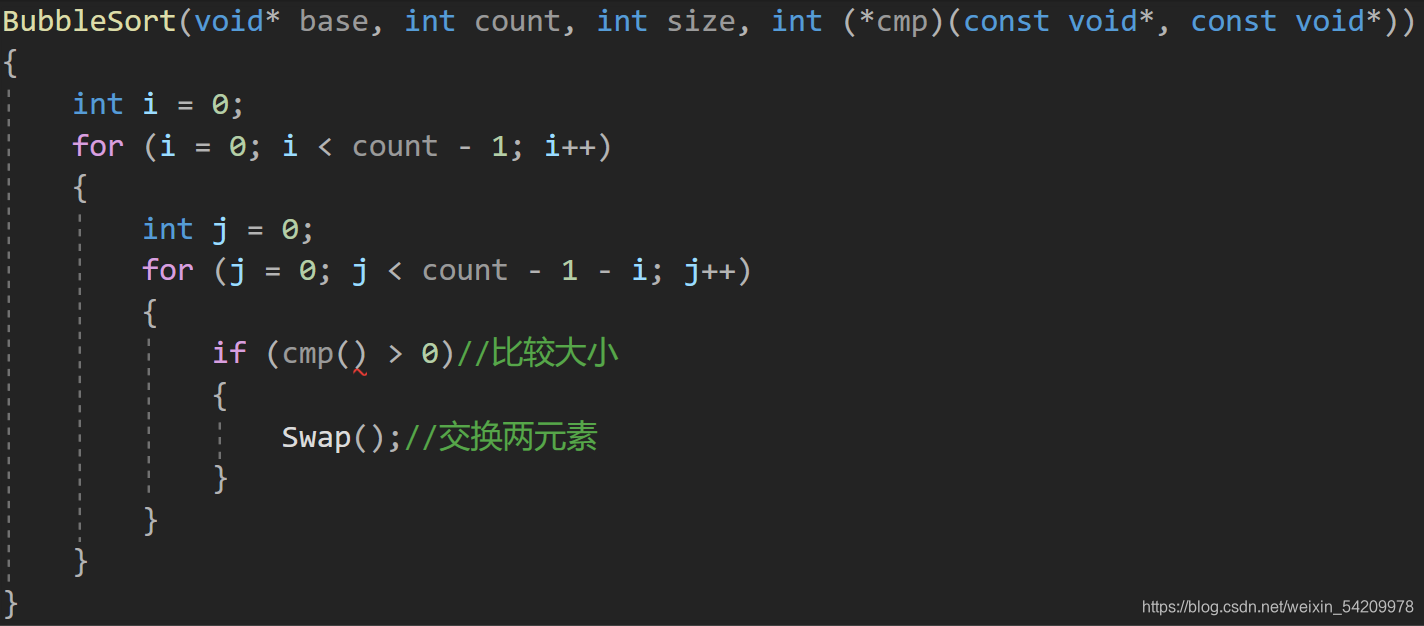
所以接下来我需要实现的就是对BubbleSort函数进行定义了。
如下是大体的框架:
比较难的是如何设置cmp函数和swap函数内的参数。
cmp函数接收的是两个相邻元素的地址,但是元素的类型可以有很多种,且所占字节大小也不同,这就为我们设下了一个难题。
但是我们知道char类型所占字节是最小的,我们是不是可以用它来表示所有变量呢?
所以先将首元素地址强制类型转换成char*,再对其加某个值,可以让其向后移动而指向不同的元素。
那么加上什么值才合适呢?
这是位于内部循环,j一直在发生变换,我们又知道每个元素所占字节大小,所以根据上述推论,我们有以下结果。
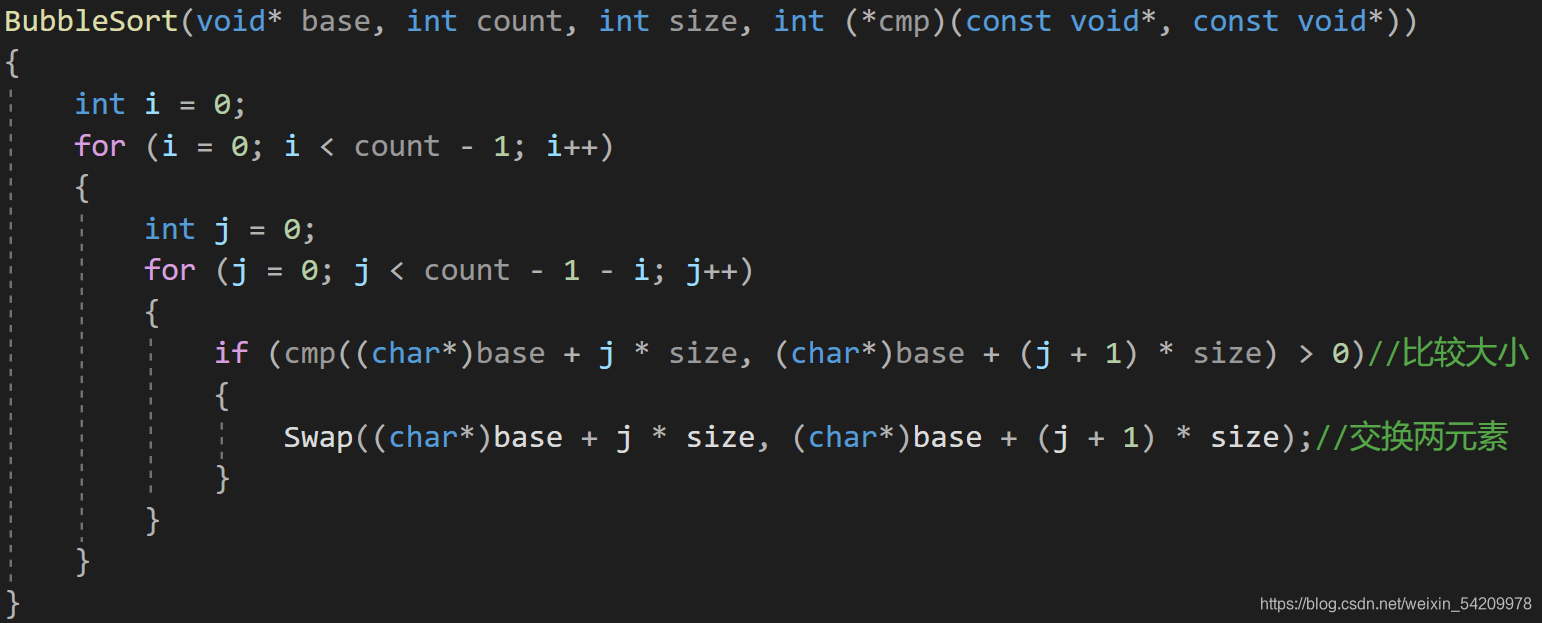
if(cmp((char*)base + j * size, (char*)base + (j + 1) * size)>0
接下来是swap函数内部的参数
swap函数是满足了前者大于后者,就对这两个数进行交换。
swap函数的参数应该是两个元素的地址,并且是和cmp()函数中的参数一样,所以有如下结果:
swap((char*)base + j * size, (char*)base + (j + 1) * size)
大体搭构好了,接下来就是实现Swap函数了
等一下,这样的Swap函数真的对吗?如果传过去的是两个元素的地址,我们真的能成功交换他们吗?
答案是否定的,因为我们平常写的交换两元素的函数是这样的
Swap(char* buf1, char* buf2)
{while((*buf1)&&(*buf2)){int tmp = *buf1;*buf1 = *buf2;*buf2 = tmp;buf1++;buf2++;}
}
发现问题了吗?我们每次++的时候都已经确定这个指针会跳过几个字节,而现在我们写的Swap函数可并不知道自己参数的类型,所以不能保证每次++后跳过的字节都正确。
讲了半天,我们最需要的是知道我们交换的元素所占字节大小是多少
所以需要给Swap函数增加一个参数size
修改后:
BubbleSort(void* base, int count, int size, int (*cmp)(const void*, const void*))
{int i = 0;for (i = 0; i < count - 1; i++){int j = 0;for (j = 0; j < count - 1 - i; j++){if (cmp((char*)base + j * size, (char*)base + (j + 1) * size) > 0)//比较大小{Swap((char*)base + j * size, (char*)base + (j + 1) * size, size);//交换两元素}}}
}
Swap函数的实现
void Swap(void* buf1, void* buf2, int size)
{int i = 0;for (i = 0; i < size; i++)//每次循环交换两个元素的一个字节{char tmp = *((char*)buf1 + i);*((char*)buf1 + i) = *((char*)buf2 + i);*((char*)buf2 + i) = tmp;}
}
每次循环交换两个元素的一个字节。
直至把一个元素所占的字节全部交换完成。
这样我们就把整个qsort函数的模拟实现了!
最后附上源码:
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
int SortByInt(const void* e1, const void* e2)
{return *(int*)e1 - *(int*)e2;
}void Swap(void* buf1, void* buf2, int size)
{int i = 0;for (i = 0; i < size; i++){char tmp = *((char*)buf1 + i);*((char*)buf1 + i) = *((char*)buf2 + i);*((char*)buf2 + i) = tmp;}
}
BubbleSort(void* base, int count, int size, int (*cmp)(const void*, const void*))
{int i = 0;for (i = 0; i < count - 1; i++){int j = 0;for (j = 0; j < count - 1 - i; j++){if (cmp((char*)base + j * size, (char*)base + (j + 1) * size) > 0)//比较大小{Swap((char*)base + j * size, (char*)base + (j + 1) * size, size);//交换两元素}}}
}int main()
{int arr[] = { 9,8,7,6,5,4,3,2,1,0 };int sz = sizeof(arr) / sizeof(arr[0]);BubbleSort(arr, sz, sizeof(arr[0]), SortByInt);return 0;
}
妹有开源精神是不行的![doge]
这篇关于爆肝!回调函数的实用案例,建议收藏~(计算器改良,qsort快排函数应用实例,冒泡函数核心理解,模拟qsort函数)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




