本文主要是介绍创建基于 GBASE南大通用数据源的数据连接,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
此章节主要介绍如何在 Visual Studio 开发工具的‚服务器资源管理器‛窗口中创建基于 GBASE南大通用数据源的数据连接。如果‚服务器资源管理器‛在 Visual Studio 开发工具打开后没有激活,可以选择‚视图‛菜单中的‚服务器资源管理器‛,如下图 9-1 所示。
在数据连接节点上点击右键后即可添加新连接。
服务器资源管理器‛在英文环境下为‚GBASE南大通用Server Explorer‛。

1) 打开连接
GBASE南大通用‚添加连接‛菜单命令执行后,会出现‚更改数据源‛对话框,如下图 9-2。
如果未出现‚更改数据源‛对话框,则需要在‚添加连接‛视图中点击‚更改按钮后会出现‚更改数据源‛对话框,如下图 9-3 所示。
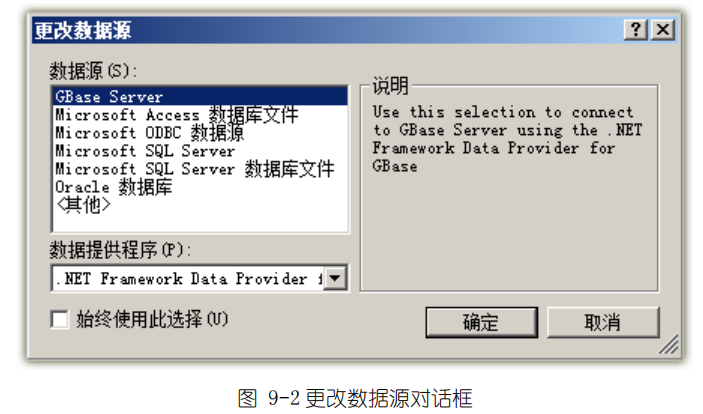

从列表中选择‚GBase Server‛项目后,则会弹出‚添加连接‛对话框,如下图 9-4。如果验证信息输入正确并且点击确定按钮后会自动打开数据连接,并且会在‚数据连接‛节点下新增一个子节点,以 IP(Database)格式命名,如:192.168.11.45(test)。
此后的操作都会在此子节点上进行。如:创建表、视图、存储过程、函数、UDF 等。
这篇关于创建基于 GBASE南大通用数据源的数据连接的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






