本文主要是介绍EMNLP 2023 亮点回顾:大模型时代下的 NLP 研究,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

作为自然语言处理(NLP)领域的顶级盛会,EMNLP 每年都成为全球研究者的关注焦点。2023 年的会议在新加坡举行,聚集了数千名来自世界各地的专家学者,也是自疫情解禁以来,中国学者参会最多的一次。巧的是,EMNLP 似乎总在召开时迎来业界大新闻。去年此时,ChatGPT 的发布引发学术大地震,颠覆了传统 NLP 的研究格局;今年,新兴的 Gemini 模型又在会议上引发热议,让好不容易挺过来的 NLPer 直摇头,还让不让人好好开会了!
无可否认,大模型的降维打击,使得传统 NLP 方法逐渐退场,也带来了行业中长期存在问题和挑战的深入反思。在大模型时代,NLP 领域的研究方向和应用场景正发生着根本性的变化。
在这篇文章里,Jina AI 创始人兼 CEO 肖涵博士和高级算法工程师 Michael,将带你速览本次 EMNLP 2023 新加坡大会。本文将从论文、海报和 BoF 会议等多个角度出发,全面回顾本次大会的最新研究成果,并深入探讨大型语言模型、向量技术、多模态大模型等热门话题。
两年一瞥:EMNLP 2022 与 2023 的变迁
2022 年,我有幸参加了阿布扎比的 EMNLP 会议。一年后,我来到了新加坡,参加了 EMNLP 2023。在这短短的一年里,我见证了自然语言处理(NLP)研究领域的重大变迁。
| EMNLP | 2022:传统方法的坚守 | 2023:大型语言模型的崛起 |
|---|---|---|
| 主要研究重点 | 聚焦在 NLP 传统方法。 | 重点关注大型语言模型(LLM)和提示词工程。 |
| 研究动态 | 研究主题广泛,但鲜有开创性的突破论文。 | 转向 LLM 的可解释性、Agent 和多模态模型。 |
| 会议氛围 | 由于 ChatGPT 的发布及其对传统 NLP 方法的影响,有点悲观和彷徨。 | 研究人员拥抱新趋势的信心和适应性更强。 |
| 研究多样性 | 仍在探索传统方法,如 topic models、n-gram 平滑和贝叶斯方法(如 COLING 2022 中所示)。 | 快速适应 LLM 时代的新方法,摆脱传统方法。 |
| 论文时效性 | 由于 ChatGPT 在开会前三天发布,所以时效性锐减。 | 2023 年 AI 发展越来越快,导致一些经验方法和结果在会议召开时就已经过时了。 |
| 参与度 | 注重 Keynote 和 Long oral,而不是 Poster。 | Poster 的人气远高于 Long oral。 |
2022 年的 EMNLP 会议仍聚焦于 NLP 的传统方法。研究者们探讨了从 topic models 到 n-gram 平滑再到贝叶斯方法的各种经典技术。虽然那时的研究主题广泛,但鲜有真正的创新突破。尽管当时的会议氛围因 ChatGPT 的发布而略显悲观和彷徨,但参会者们依旧积极探索和讨论彼此的研究。
一年之后,情况发生了翻天覆地的变化。EMNLP 2023 的核心议题集中在大型语言模型(LLM)及其提示词技术等,研究者们全面拥抱起了新趋势。并且此次我们还注意到了一个有趣的现象:AI 发展越来越快,导致许多六个月前的论文和研究成果,在会议召开时就已经过时了,这也给 EMNLP 会议的 review 带来了挑战,只有跟着 AI 的发展一起加速,才能更好地评估研究成果的价值。
这两年的 NLP 领域经历了巨大变迁,每一届 EMNLP 不仅是对过去的回顾,也是对未来的展望。随着技术的不断演化,我们期待 NLP 领域将将呈现出更多令人振奋的新面貌。
EMNLP 2023 精选论文
在 EMNLP 2023 上,几篇有趣的论文引起了我的注意,每篇论文都讨论了 NLP 的不同方面,并突破了该领域可能的界限。以下是我对这些论文的笔记以及个人观点。
混合倒排索引:加速密集检索的强力工具
Hybrid Inverted Index Is a Robust Accelerator for Dense Retrieval
这篇论文讨论了如何加速文本向量做信息检索的问题。传统的文本向量在信息检索任务中应用广泛,但在计算查询向量与每个文档向量之间的相似性时,往往面临速度慢、效率低的问题。为此,人们常用近似最近邻搜索(ANN)技术来加速检索,比如基于数据分布的矢量量化聚类算法。
混合搜索结合了向量搜索和传统 BM25 搜索技术,但在现有实现中,两者通常是独立运行,只在最后合并结果。
这篇论文提出了一种新的联合索引训练方法,包括簇选择器和词选择器两部分。簇选择器将文本分配到相近的簇中,词选择器则找出最能代表文档的词。BM25 可以用这些词将文档放入对应的桶中,考虑到 BM25 本身是非训练型算法,无法适应训练数据。因此,论文提出了用 BERT 模型加 MLP 来训练词选择器,增强其灵活性。接着,使用 KL 散度损失函数,以向量模型作为教师模型,把簇中心和 BERT 模型进行联合训练,学习相似性值的分布。实验结果表明,这种方法能在相同的时间内检索到更多相关文档,其性能与标准 ANN 技术(如 HNSW 和 IVF-PQ)相当。
论文亮点:
-
混合索引结合了向量搜索和 BM25 的优势,效率和准确性兼顾。
-
用 BERT 模型作为可训练的词选择器,提高了检索精度。
ChatGPT 擅长搜索吗?把 LLM 成为 ReRanker Agents
Is ChatGPT Good at Search? Investigating Large Language Models as Re-Ranking Agents
这篇论文探讨了如何利用大型语言模型 (LLM) 来改进搜索结果的排序,也就是重排 (re-ranking)。传统搜索引擎往往先检索出一批相关文档,然后通过重排算法挑选出最符合用户查询的文档。常见的重排模型是经过微调的 Transformer 模型,称为交叉编码器 (cross encoder)。它接收查询和文档对作为输入,输出一个相关性分数。此外,像 LambdaMart 这样的学习排序 (learning-to-rank) 模型也很受欢迎,尤其是在排序不仅仅只依赖于语义相关性的时候。
看到 LLMs 强大的语言处理能力后,作者们想知道像 GPT4 这样的模型能不能更好地进行文档重排。但封闭的 API 通常不提供概率输出,限制了其应用。因此,论文探索了只依靠提示词和输出文本进行重排的技术。他们提出的方法是在提示词中插入带有 ID 的文档,并指示 LLM 按文档的相关性输出一个 ID 序列。当文档数量太多无法一次放入提示词中时,就使用滑动窗口的方法,先对第一阶段检索器返回的得分最低的文档进行重排,然后根据输出结果将最相关的文档与下一窗口的检索候选一起呈现给 LLM,以此类推。
考虑到 GPT-4 的成本和速度限制,作者们提出了将它的重排能力蒸馏到更小更快的 Transformer 模型中。结果表明,即使是参数量少得多的蒸馏模型 (4.4 亿参数) ,效果也能胜过现有的许多大型重排模型。
关键点分析:
-
用滑动窗口处理了海量文档的重排问题。
-
模型蒸馏使 LLM 的重排能力在实际应用中可用。
LLM 靠自己就能变强
Large Language Models Can Self-Improve
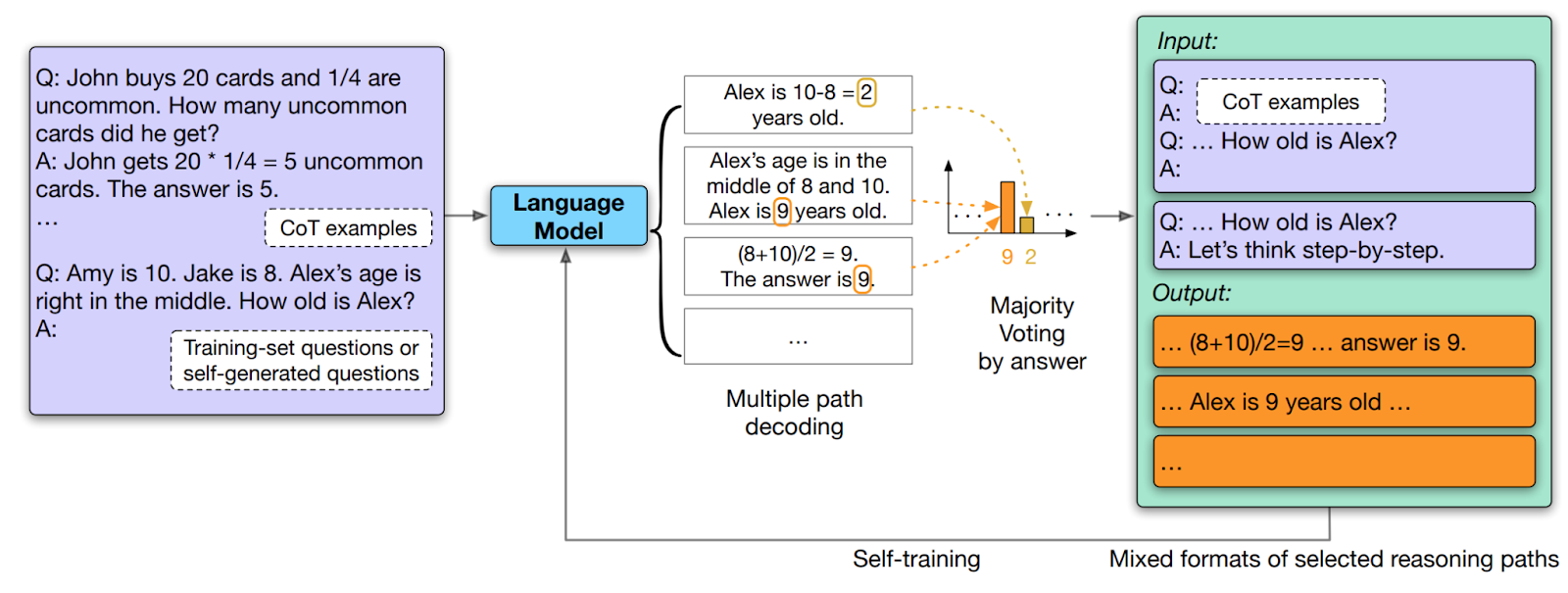
大型语言模型 (LLM) 虽然能在零样本设定下出色完成一些任务,但令其表现在特定领域要更进一步往往需要大量标注数据进行微调。这篇论文的核心思想是让 LLM 自己生成训练数据。论文主要步骤如下:
-
数据集准备: 使用一个只包含问题,没有答案的数据集。
-
思维链 (CoT) 生成: 通过 CoT 方法,在提问时设定 temperature,让 LLM 产生多个包含不同推理路径和答案的候选方案。
-
答案筛选: 统计每个答案出现的频率,选择频率最高的答案,提高其正确率。
-
置信度评估: LLM 通过分析答案的一致性来评估其置信度。高一致性的答案更有可能正确。
-
构建训练数据: 将高频答案及其对应的推理路径转化为新的提示词,并以不同风格呈现,比如直接展示问题、或者加入引导性提示词 (“请你逐步思考”)。
-
模型精调: 使用增强后的训练数据集对 LLM 进行针对特定任务的微调。
论文的评估结果表明,这种方法不仅能用少量数据有效地精调 LLM,而且能很好地泛化到新任务上,提升模型在未知领域的表现。
关键亮点:
-
LLM 自我生成训练数据,减少对外部数据的依赖。
-
“多角度思考” 和 “一致性评估” 提升答案可靠性。
-
多种格式的训练数据,让 LLM 适应性更强。
压缩文档,解锁 LLM 更长上下文
Adapting Language Models to Compress Contexts

这篇论文聚焦于解决一个困扰语言模型的难题:上下文长度限制。虽然像 AliBi 这样的技术可以构建处理更长上下文的模型,但对于现有的、上下文长度受限的模型来说无能为力。
这篇论文提出了一种巧妙的解决方案:精调已有模型,使其适应长上下文。具体操作如下:
-
扩展词汇表: 在模型已有的词汇表里增加“摘要标记”,帮助模型将大量信息压缩成更小的向量。
-
切割文本: 把要处理的长文本切成小段,每段都加上摘要标记,这些标记带有之前文本段落的压缩信息。
-
精调训练: 用“下一个词预测”任务来微调模型,模型需要利用之前序列的摘要向量中的信息来预测下一个词。
-
整体反向传播: 在训练过程中,文本序列的长度会进行动态变化,以让模型适应不同长度的文本。但反向传播会针对整篇文档进行,让模型学习整个上下文的关联。
作者证明了该方法对不同规模的模型(如 OPT 和 7B-Llama-2 模型)都适用,还可以用于不同的任务,比如处理更长提示词的分类任务,或者文本重新排序任务。
核心亮点:
-
无需重新构建模型,巧妙通过扩展词汇表来适应长上下文。
-
使用 "摘要标记" 和摘要向量来压缩上下文信息。
EMNLP 2023 精选 Poster
在 EMNLP 2023 上,除了引人注目的论文演讲之外,Poster 也是讨论和交流的中心。在这里分享一些让我印象深刻的海报,它们每一张都像一个窗口一样,让我们瞥见自然语言处理 (NLP) 领域正在进行的前沿研究与发展。
检索增强模型真的可以推理吗?
Can Retriever-Augmented Language Models Reason?

检索增强语言模型 (Retriever-Augmented Language Models, RALM) 是近年来 NLP 领域的一个重要发展方向,它通过将检索器和语言模型结合起来,有望产生真实、高效且最新的语言理解系统。来自麦吉尔大学的作者们研究了检索增强语言模型 (RALM) 是否能真正有效地推理,重点在于平衡检索模块 (retriever) 和语言模型 (language model) 的能力。研究强调了检索模块在收集推理所需信息方面的潜在缺陷,以及即使提供必要信息,语言模型在推理方面也可能犯错。这是一个深入探讨改进大型语言模型交互式组件的精彩研究。
基于对比学习的句子编码器
Contrastive Learning-based Sentence Encoders

对比学习是一种机器学习技术,通过让模型区分正负样本来学习特征。这篇论文来自东北大学的研究人员,他们提出了一种基于对比学习的句子编码器。在训练过程中,模型会学习到哪些单词在句子中更重要。这些重要单词将会被赋予更高的权重,从而提高模型对句子的理解和处理能力。这种方法可以改进句子编码器对文本中关键元素的优先级排序和处理方式,使其更加高效和有效。
研究 Transformer 向量的语义子空间
Investigating Semantic Subspaces of Transformer Sentence Embeddings
斯图加特大学的研究团队试图探索 Transformer 如何理解句子的语义,以及其不同层在这一过程中扮演的角色。为此,他们使用了一种称为线性结构探测的技术,揭示 Transformer 模型不同层对不同语义信息类型的贡献,从而帮助改进 Transformer 模型的结构,使其更好地利用训练数据,从而提升模型的性能和可解释性。
解锁多模态语言模型的世界知识
Can Pre-trained Vision and Language Model Answer Visual Information-Seeking Questions?

来自佐治亚理工学院、谷歌研究院和 DeepMind 的研究人员展示了一个精彩的海报,他们提出了一种测试多模态大语言模型 (LLM) 世界知识的新方法,即通过视觉信息检索问题。与传统的语言问答任务不同,它要求模型不仅要理解文本,还要理解图像,并将其结合起来推理和回答问题。这项研究从传统的文本问答扩展到需要视觉理解的场景,进一步探索了多模态 LLM 的潜力。
拆还是不拆?复合词在上下文向量空间中的分词策略
To Split or Not to Split: Composing Compounds in Contextual Vector Spaces

斯图加特大学的这篇研究探讨了在上下文向量空间中处理德语复合词时,拆分词根和不拆分词根这两种方式的优劣。德语复合词由两个或多个词组成,通常以单个单词的形式出现,但传统的分割方法并不总是遵循词形或语义。研究者利用 BERT 模型及其变体,以及特定领域的历史语料库,设计了一系列基于掩码语言模型和成分预测的评估方法。研究发现,将复合词预先拆分成语素能够带来最稳定的性能提升。
在语言模型学习过程中,信息如何流动
Subspace Chronicles: How Linguistic Information Emerges, Shifts, and Interacts during Language Model Training

这篇学术论文探讨了在语言模型的训练过程中,语言信息的奇妙旅程,它如何从无到有,不断演变,互相交流。研究人员探索了 9 种涵盖句法、语义和推理的 NLP 任务,在 200 万预训练步骤和 5 个随机种子下,分析不同类型语言信息如何出现和相互作用。
- 信息的流动和转变贯穿整个训练过程,可划分为三个关键学习阶段:
-
快速涌现期 (0.5% 训练进度) :各子空间快速形成,词法和句法知识迅速习得。
-
知识拓展期: 任务性能的提升主要源于大量开放域知识的获取。
-
专业深化期: 语义和推理任务受益于更高级的上下文关联和更精细的专业化。
-
-
语言相关的任务在整个训练过程中共享信息,但在快速涌现期的互动最为密切。
“心智理论” 助攻多 Agent 协作
Theory of Mind for Multi-Agent Collaboration via Large Language Models

这张学术海报聚焦于大型语言模型(LLM)的“心智理论”研究,探索其在多智能体协作任务中的应用潜力。过去 LLM 在多智能体协作领域的表现仍未得到充分探索。该研究使用基于 LLM 的智能体参与了一个多智能体协作的文本游戏力,并设置了特定的“心智理论”推理任务,与多智能体强化学习(MARL)和基于规划的方法进行了对比分析。
此前,Jina AI 在 PromptPerfect 产品的多智能体沙盒模拟中,也在这一领域取得了进展,我们通过沙盒模拟实验来探索和观察多智能体系统的协作方式和智能程度。
EMNLP Embeddings 茶话会
在 2023 年 EMNLP 大会期间,Jina AI 举办了一场关于向量技术的 "Birds of a Feather (BoF)" 会议,此次会议共有 80 位参与者,碰撞思想,话题前沿,精彩纷呈。
闪电演讲和小组讨论
会议伊始,来自 Huiqiang、Hassan、Hwiyeol、Mattia 和 Yang Chen 等研究人员的闪电演讲拉开帷幕。每位演讲者都从独到的视角出发,分享了他们在 NLP 向量领域的最新研究成果,点燃了现场讨论的热情,并自然过渡到深入的专家讨论环节。

由 Sebastian Ruder、Nicola Cancedda、Chia Ying Lee、Michael Günther 和 Han Xiao 组成豪华专家组,深入探讨了向量技术的前世今生,从向量技术的演变到向量技术与生成式 AI 和大语言模型的融合,以及未来的发展方向。

闪电演讲和专家讨论覆盖了向量技术研究的各个方面,从基础理论到实际应用,从传统方法到最新进展,为向量技术提供了全景式的解读。
小组讨论的主要要点
-
关于向量的不同观点:不同领域的研究人员分享了他们对各种向量技术方面的经验,讨论了他们观察到的共同点和分歧,尤其强调了向量的行为会因设计和应用场景的不同而产生微妙的差别,需要更细致的理解。
-
AI 浪潮之下,向量依旧重要:2023 年大型语言模型广受关注,研究人员们重申了向量的重要性。他们强调,尽管有 LLM 大行其道,向量仍然在更细粒度的语言理解和处理方面发挥着至关重要的作用。
-
上下文长度之谜: Embedding vs LLM: 一个有趣的观察是 LLM 和向量模型之间上下文长度扩展的差异。小组成员们解释了当前限制向量模型中上下文窗口的技术和实践限制。
-
跨越搜索与生成的鸿沟:针对“搜索是过度拟合的生成,生成是欠拟合的搜索”这一论点,小组成员分享了不同的观点,引发了关于搜索功能和生成能力之间相互作用的激烈辩论。
-
RAG 和 Agent 模型的未来:展望 EMNLP 2024,对话转向检索增强生成(RAG)和 Agent 模型的潜在挑战和发展。小组成员暗示了他们对未来将向量集成到这些应用程序中的愿景,并认识到向量将继续发挥的关键作用。

总结回顾
EMNLP 2023 圆满落幕,社区对于突破 NLP 界限的热情让我深感振奋。特别是我们的向量茶话会,精彩的互动和深刻的洞见,成为了我们在本次大会中最难忘的高光时刻。
摩拳擦掌,想要亲身体验向量的未来吗?我们正在招募人才!我们致力于深入研究长上下文、多语言和多模态的向量模型。如果你准备好迎接挑战,请查看 https://jobs.lever.co/jina-ai 的空缺职位,也许我们会在柏林、深圳或北京办公室相见!
迫不及待地想看看我们将在 2024 年 EMNLP 大会上带来哪些成果。在此之前,让我们继续保持创新,发问质疑,让对话永不停息!
这篇关于EMNLP 2023 亮点回顾:大模型时代下的 NLP 研究的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








