本文主要是介绍凯斯西储大学轴承数据解读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 一、凯斯西储大学轴承数据基础知识?
- 1.1 故障种类
- 1.2 故障点尺寸(单点故障)
- 1.3 载荷和转速
- 二、数据解读
- 2.1 文件
- 2.2 以12k Drive End Bearing Fault Data为例
- 2.3 以(0.007'',inner race)为例。
- 3 Normal Baseline Data是12k原因
- 3.1 部分代码(频谱分析代码)
- 3.2 数据分析
- 总结
数据集官网
一、凯斯西储大学轴承数据基础知识?
1.1 故障种类
- 内圈故障
- 外圈故障
- 滚动体故障
1.2 故障点尺寸(单点故障)
- 直径0.007英寸(SKF轴承)
- 直径0.014英寸(SKF轴承)
- 直径0.021英寸(SKF轴承)
- 直径0.028英寸(NTN轴承,一般不用)
- 直径0.040英寸(NTN轴承,一般不用)
1.3 载荷和转速
- 0马力-1797r/min
- 1马力-1772r/min
- 2马力-1750r/min
- 3马力-1730r/min
二、数据解读
2.1 文件
Normal Baseline Data(12k)
12k Drive End Bearing Fault Data
48k Drive End Bearing Fault Data
Fan-End Bearing Fault Data(12k)
2.2 以12k Drive End Bearing Fault Data为例
12k Drive End Bearing Fault Data是驱动端轴承故障数据,它包含如下的数据,
2.3 以(0.007’',inner race)为例。
X105_DE_time:表示的是驱动端轴承故障数据的情况下,驱动端的传感器测得的数据。

3 Normal Baseline Data是12k原因
3.1 部分代码(频谱分析代码)
数据读取代码可以看如下两篇文章。
https://zhuanlan.zhihu.com/p/448901398
https://zhuanlan.zhihu.com/p/448210993
def envelope_spectrum1(data1, fs):'''fun: 绘制包络谱图param data: 输入数据,1维arrayparam fs: 采样频率param xlim: 图片横坐标xlim,default = Noneparam vline: 图片垂直线,default = None'''# ----去直流分量----#data = np.array(data1)data = data - np.mean(data)# ----做希尔伯特变换----#xt = dataht = fftpack.hilbert(xt)at = np.sqrt(xt ** 2 + ht ** 2) # 获得解析信号at = sqrt(xt^2 + ht^2)am = np.fft.fft(at) # 对解析信号at做fft变换获得幅值am = np.abs(am) # 对幅值求绝对值(此时的绝对值很大)am = am / len(am) * 2am = am[0: int(len(am) / 2)] # 取正频率幅值freq = np.fft.fftfreq(len(at), d=1 / fs) # 获取fft频率,此时包括正频率和负频率freq = freq[0:int(len(freq) / 2)] # 获取正频率am[0] = 0return freq, amif __name__ == '__main__':upperurl = "F:\\tempture\\信号分析-全部\\CRWU\\"class_all1, mapdata_all1, rotate_all = extract_path_drive()(x, y) = load_data(upperurl, class_all1)freq, am = envelope_spectrum1(x[0][:12000], 12000)plt.figure()plt.plot(freq[:100], am[:100])plt.show()
3.2 数据分析
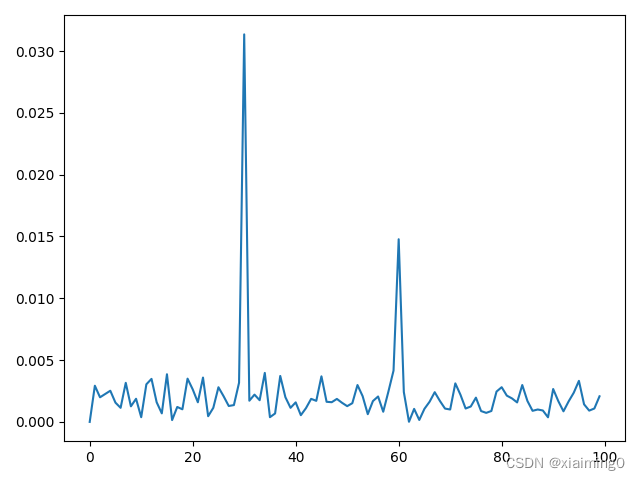
envelope_spectrum1(x[0][:12000], 12000)的第二个参数是采样频率。
x[0]是负载为0,驱动端的数据。
电机在负荷0下的转速为1797r/min,转频为1797/60,约为30Hz,符合下图所观测到的结果。
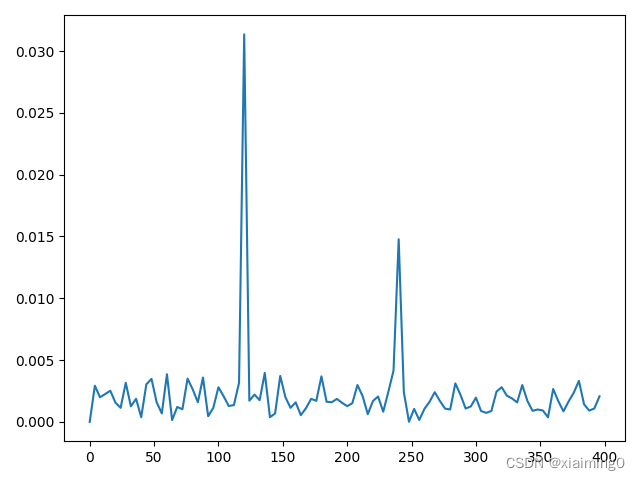
设置采样频率为48k,即envelope_spectrum1(x[0][:12000], 48000),可获得下图。
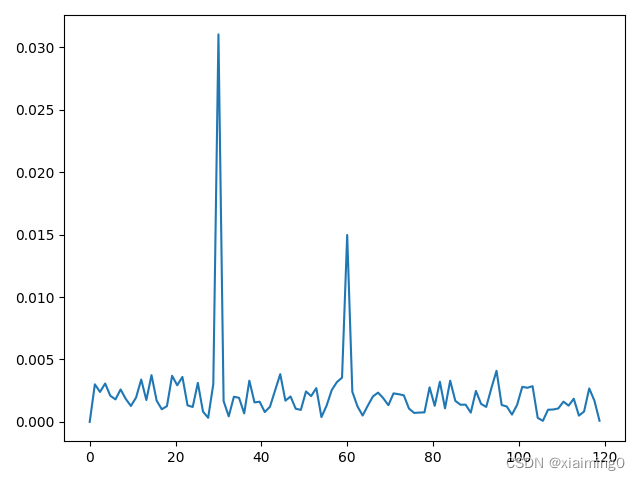
设置采样点的个数为10000 ,即envelope_spectrum1(x[0][:10000], 12000),可获得下图。
总结
Normal Baseline Data里面的数据的采样频率是12k。
每个.mat文件下,都包含在该故障下,或驱动端或风扇端或基座采集到的数据。
这篇关于凯斯西储大学轴承数据解读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




