本文主要是介绍Apple Silicon M1 机器学习性能简单测试,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Apple官方给tensorflow做了支持,使得带M1芯片的机器能用上硬件加速。本文将使用Macbook Air M1、2015 Macbook Pro 13” 以及Google提供的CoLab平台GPU和TPU进行测试对比。
测试方法
使用在tensorflow_macos项目Issues中Willian-Zhang提供的Benchmark: CNN脚本对以上平台分别测试,并计算运行完脚本所使用的总时间。脚本程序可以在github上获取,或者在本文末尾找到。
在运行脚本之前,需要先给macOS安装配置好conda环境及tensorflow配置,具体方法可参考文章:
《macOS M1(Apple Silicon) 安装配置 Conda 环境》
《macOS M1(AppleSilicon) 安装TensorFlow环境》
《macOS Intel(x86_64) 安装TensorFlow环境》
测试结果
在4个平台上测试的结果如下:
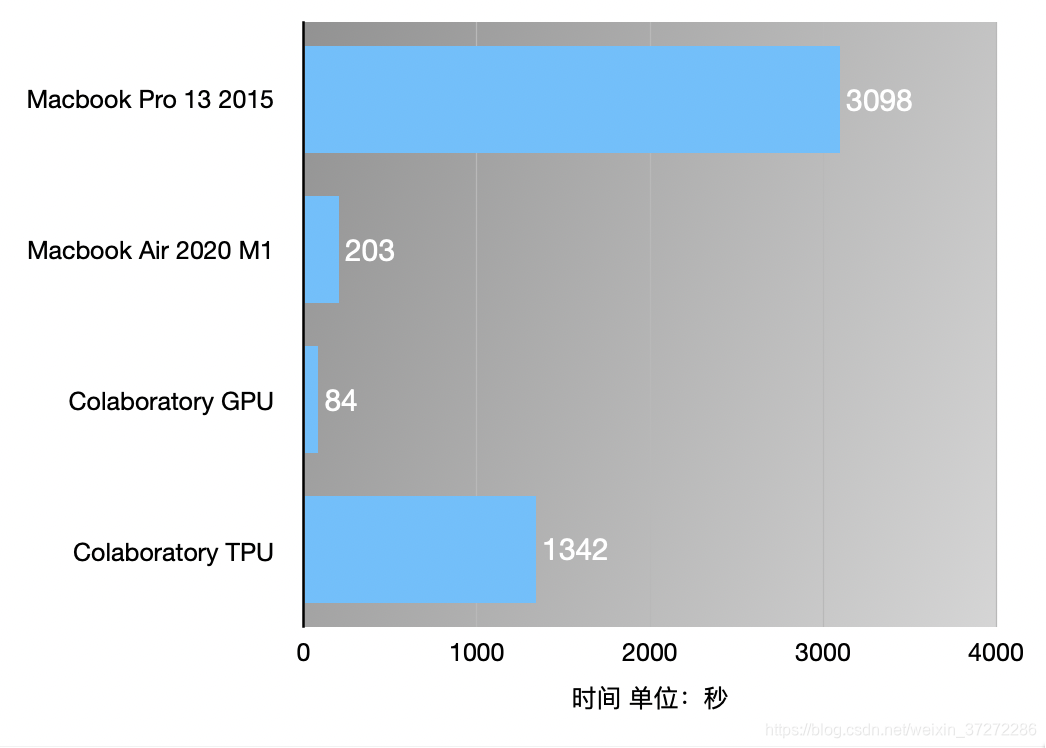
可以从上图结果看到,Macbook Pro13 2015需要50多分钟才完成脚本,而M1的Macbook Air才用了约2分半钟,虽然比不上Colab GPU的84秒,但考虑到Colab的不稳定以及有地区的使用限制,综合来看,用AppleSIlicon的Mac来做简单的机器学习,也许是个挺不错的选择。
附1 - 测试脚本
import tensorflow.compat.v2 as tf
import tensorflow_datasets as tfds
import time
from datetime import timedeltatf.enable_v2_behavior()from tensorflow.python.framework.ops import disable_eager_execution
disable_eager_execution()# 使用Colab或者其他平台,应注释一下这行
# 非AppleSilicon的Mac只要配置了Apple提供的tensorflow,可以正常运行不需要作修改
from tensorflow.python.compiler.mlcompute import mlcompute
mlcompute.set_mlc_device(device_name='gpu')(ds_train, ds_test), ds_info = tfds.load(
'mnist',
split=['train', 'test'],
shuffle_files=True,
as_supervised=True,
with_info=True,
)def normalize_img(image, label):
"""Normalizes images: `uint8` -> `float32`."""
return tf.cast(image, tf.float32) / 255., labelbatch_size = 128ds_train = ds_train.map(
normalize_img, num_parallel_calls=tf.data.experimental.AUTOTUNE)
ds_train = ds_train.cache()
ds_train = ds_train.shuffle(ds_info.splits['train'].num_examples)
ds_train = ds_train.batch(batch_size)
ds_train = ds_train.prefetch(tf.data.experimental.AUTOTUNE)ds_test = ds_test.map(
normalize_img, num_parallel_calls=tf.data.experimental.AUTOTUNE)
ds_test = ds_test.batch(batch_size)
ds_test = ds_test.cache()
ds_test = ds_test.prefetch(tf.data.experimental.AUTOTUNE)model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(32, kernel_size=(3, 3),
activation='relu'),
tf.keras.layers.Conv2D(64, kernel_size=(3, 3),
activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=(2, 2)),
# tf.keras.layers.Dropout(0.25),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
# tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(
loss='sparse_categorical_crossentropy',
optimizer=tf.keras.optimizers.Adam(0.001),
metrics=['accuracy'],
)start = time.time()model.fit(
ds_train,
epochs=10,
# validation_steps=1,
# steps_per_epoch=469,
# validation_data=ds_test # 此处如果按原脚本添加这行,脚本无法运行,暂时未有解决方法
)delta = (time.time() - start)
elapsed = str(timedelta(seconds=delta))
print('Elapsed Time: {}'.format(elapsed))
附2 - 测试结果
# Macbook Air 2020 M12021-02-16 14:46:25.367705: I tensorflow/compiler/mlir/mlir_graph_optimization_pass.cc:196] None of the MLIR optimization passes are enabled (registered 0 passes)
2021-02-16 14:46:25.368515: W tensorflow/core/platform/profile_utils/cpu_utils.cc:126] Failed to get CPU frequency: 0 Hz
Train on None steps
Epoch 1/10
2021-02-16 14:46:25.721520: I tensorflow/compiler/mlir/mlir_graph_optimization_pass.cc:116] None of the MLIR optimization passes are enabled (registered 2)
469/469 [==============================] - 20s 40ms/step - batch: 234.0000 - size: 1.0000 - loss: 0.7121 - accuracy: 0.8496
Epoch 2/10
469/469 [==============================] - 20s 40ms/step - batch: 234.0000 - size: 1.0000 - loss: 0.1144 - accuracy: 0.9731
Epoch 3/10
469/469 [==============================] - 20s 40ms/step - batch: 234.0000 - size: 1.0000 - loss: 0.0732 - accuracy: 0.9820
Epoch 4/10
469/469 [==============================] - 20s 40ms/step - batch: 234.0000 - size: 1.0000 - loss: 0.0546 - accuracy: 0.9858
Epoch 5/10
469/469 [==============================] - 20s 40ms/step - batch: 234.0000 - size: 1.0000 - loss: 0.0452 - accuracy: 0.9889
Epoch 6/10
469/469 [==============================] - 20s 40ms/step - batch: 234.0000 - size: 1.0000 - loss: 0.0371 - accuracy: 0.9907
Epoch 7/10
469/469 [==============================] - 20s 40ms/step - batch: 234.0000 - size: 1.0000 - loss: 0.0325 - accuracy: 0.9918
Epoch 8/10
469/469 [==============================] - 20s 40ms/step - batch: 234.0000 - size: 1.0000 - loss: 0.0272 - accuracy: 0.9937
Epoch 9/10
469/469 [==============================] - 20s 40ms/step - batch: 234.0000 - size: 1.0000 - loss: 0.0243 - accuracy: 0.9941
Epoch 10/10
469/469 [==============================] - 20s 40ms/step - batch: 234.0000 - size: 1.0000 - loss: 0.0209 - accuracy: 0.9957
Elapsed Time: 0:03:23.720809
# Macbook Pro 13 2015
2021-02-12 12:58:05.524324: I tensorflow/compiler/jit/xla_cpu_device.cc:41] Not creating XLA devices, tf_xla_enable_xla_devices not set
2021-02-12 12:58:05.524539: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2021-02-12 12:58:05.675857: I tensorflow/compiler/mlir/mlir_graph_optimization_pass.cc:196] None of the MLIR optimization passes are enabled (registered 0 passes)
Train on None steps
Epoch 1/10
2021-02-12 12:58:06.441954: I tensorflow/compiler/mlir/mlir_graph_optimization_pass.cc:116] None of the MLIR optimization passes are enabled (registered 2)
469/469 [==============================] - 310s 652ms/step - batch: 234.0000 - size: 1.0000 - loss: 0.1541 - accuracy: 0.9539
Epoch 2/10
469/469 [==============================] - 309s 649ms/step - batch: 234.0000 - size: 1.0000 - loss: 0.0400 - accuracy: 0.9878
Epoch 3/10
469/469 [==============================] - 312s 656ms/step - batch: 234.0000 - size: 1.0000 - loss: 0.0252 - accuracy: 0.9920
Epoch 4/10
469/469 [==============================] - 312s 655ms/step - batch: 234.0000 - size: 1.0000 - loss: 0.0183 - accuracy: 0.9938
Epoch 5/10
469/469 [==============================] - 306s 642ms/step - batch: 234.0000 - size: 1.0000 - loss: 0.0127 - accuracy: 0.9959
Epoch 6/10
469/469 [==============================] - 306s 642ms/step - batch: 234.0000 - size: 1.0000 - loss: 0.0091 - accuracy: 0.9971
Epoch 7/10
469/469 [==============================] - 306s 642ms/step - batch: 234.0000 - size: 1.0000 - loss: 0.0083 - accuracy: 0.9973
Epoch 8/10
469/469 [==============================] - 311s 655ms/step - batch: 234.0000 - size: 1.0000 - loss: 0.0050 - accuracy: 0.9982
Epoch 9/10
469/469 [==============================] - 312s 655ms/step - batch: 234.0000 - size: 1.0000 - loss: 0.0046 - accuracy: 0.9986
Epoch 10/10
469/469 [==============================] - 313s 658ms/step - batch: 234.0000 - size: 1.0000 - loss: 0.0050 - accuracy: 0.9983
Elapsed Time: 0:51:38.627279
Colab GPU
Train on 469 steps
Epoch 1/10
469/469 [==============================] - 14s 7ms/step - batch: 234.0000 - size: 1.0000 - loss: 0.1589 - accuracy: 0.9530
Epoch 2/10
469/469 [==============================] - 8s 6ms/step - batch: 234.0000 - size: 1.0000 - loss: 0.0436 - accuracy: 0.9868
Epoch 3/10
469/469 [==============================] - 8s 6ms/step - batch: 234.0000 - size: 1.0000 - loss: 0.0266 - accuracy: 0.9917
Epoch 4/10
469/469 [==============================] - 8s 6ms/step - batch: 234.0000 - size: 1.0000 - loss: 0.0192 - accuracy: 0.9938
Epoch 5/10
469/469 [==============================] - 8s 6ms/step - batch: 234.0000 - size: 1.0000 - loss: 0.0131 - accuracy: 0.9959
Epoch 6/10
469/469 [==============================] - 8s 6ms/step - batch: 234.0000 - size: 1.0000 - loss: 0.0109 - accuracy: 0.9964
Epoch 7/10
469/469 [==============================] - 8s 6ms/step - batch: 234.0000 - size: 1.0000 - loss: 0.0065 - accuracy: 0.9980
Epoch 8/10
469/469 [==============================] - 8s 6ms/step - batch: 234.0000 - size: 1.0000 - loss: 0.0067 - accuracy: 0.9980
Epoch 9/10
469/469 [==============================] - 8s 6ms/step - batch: 234.0000 - size: 1.0000 - loss: 0.0060 - accuracy: 0.9981
Epoch 10/10
469/469 [==============================] - 8s 6ms/step - batch: 234.0000 - size: 1.0000 - loss: 0.0057 - accuracy: 0.9978
Elapsed Time: 0:01:24.286260
# Colab TPU
Train on 469 steps
Epoch 1/10
469/469 [==============================] - 136s 275ms/step - batch: 234.0000 - size: 1.0000 - loss: 0.1504 - accuracy: 0.9553
Epoch 2/10
469/469 [==============================] - 135s 276ms/step - batch: 234.0000 - size: 1.0000 - loss: 0.0412 - accuracy: 0.9874
Epoch 3/10
469/469 [==============================] - 134s 274ms/step - batch: 234.0000 - size: 1.0000 - loss: 0.0272 - accuracy: 0.9915
Epoch 4/10
469/469 [==============================] - 135s 275ms/step - batch: 234.0000 - size: 1.0000 - loss: 0.0177 - accuracy: 0.9944
Epoch 5/10
469/469 [==============================] - 134s 274ms/step - batch: 234.0000 - size: 1.0000 - loss: 0.0127 - accuracy: 0.9957
Epoch 6/10
469/469 [==============================] - 134s 273ms/step - batch: 234.0000 - size: 1.0000 - loss: 0.0096 - accuracy: 0.9967
Epoch 7/10
469/469 [==============================] - 134s 273ms/step - batch: 234.0000 - size: 1.0000 - loss: 0.0070 - accuracy: 0.9977
Epoch 8/10
469/469 [==============================] - 133s 272ms/step - batch: 234.0000 - size: 1.0000 - loss: 0.0062 - accuracy: 0.9981
Epoch 9/10
469/469 [==============================] - 133s 272ms/step - batch: 234.0000 - size: 1.0000 - loss: 0.0057 - accuracy: 0.9980
Epoch 10/10
469/469 [==============================] - 133s 271ms/step - batch: 234.0000 - size: 1.0000 - loss: 0.0045 - accuracy: 0.9986
Elapsed Time: 0:22:22.303190
这篇关于Apple Silicon M1 机器学习性能简单测试的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






