Django mptt介绍以及使用
Django mptt介绍以及使用 - 剁椒芋头 - 博客园
Django mptt介绍以及使用
Django mptt是个Django第三方组件,目标是使Django项目能在数据库中存储层级数据(树形数据)。它主要实现了修改过的前序遍历算法,如果你对原理还不是很了解,可以看我的这篇文章。当然,使用mptt时,原理是可以不用了解的,因为具体的实现细节都已经隐藏。不过,如果项目不是使用的Django,可以参考具体的实现原理。
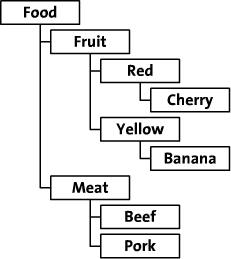
在整篇文章中,我们将会拿《在数据库中存储层级结构》中的例子作为本文的例子。我们打算在数据库中存储这张图中的数据:
在介绍mptt之前,如果你的需求仅仅是像这样显示以上数据:
<li>Food<ul><li>Fruit<ul><li>Red<ul><li>Cherry</li></ul></li><li>Yellow<ul><li>Banana</li></ul></li></ul></li><li>Meat<ul><li>Beef</li><li>Pork</li></ul></li></ul></li>mptt就显得大材小用了,因为Django已经有内置模板过滤器来完成这个工作:unordered_list(官方文档)。如果你的需求不只这么简单,那就跳过这一段。不过这里还是要讲解一下unordered_list的做法。我们就来实现以上的结果。
当然我们首先要写一个简单的Model。
fromdjango.dbimportmodelsclassFood(models.Model):title=models.CharField(max_length=50)parent=models.ForeignKey("self", blank=True, null=True, related_name="children")def__unicode__(self):returnself.title
posted on 2013-01-05 09:00 lexus 阅读( ...) 评论( ...) 编辑 收藏







