本文主要是介绍plug-中文大模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
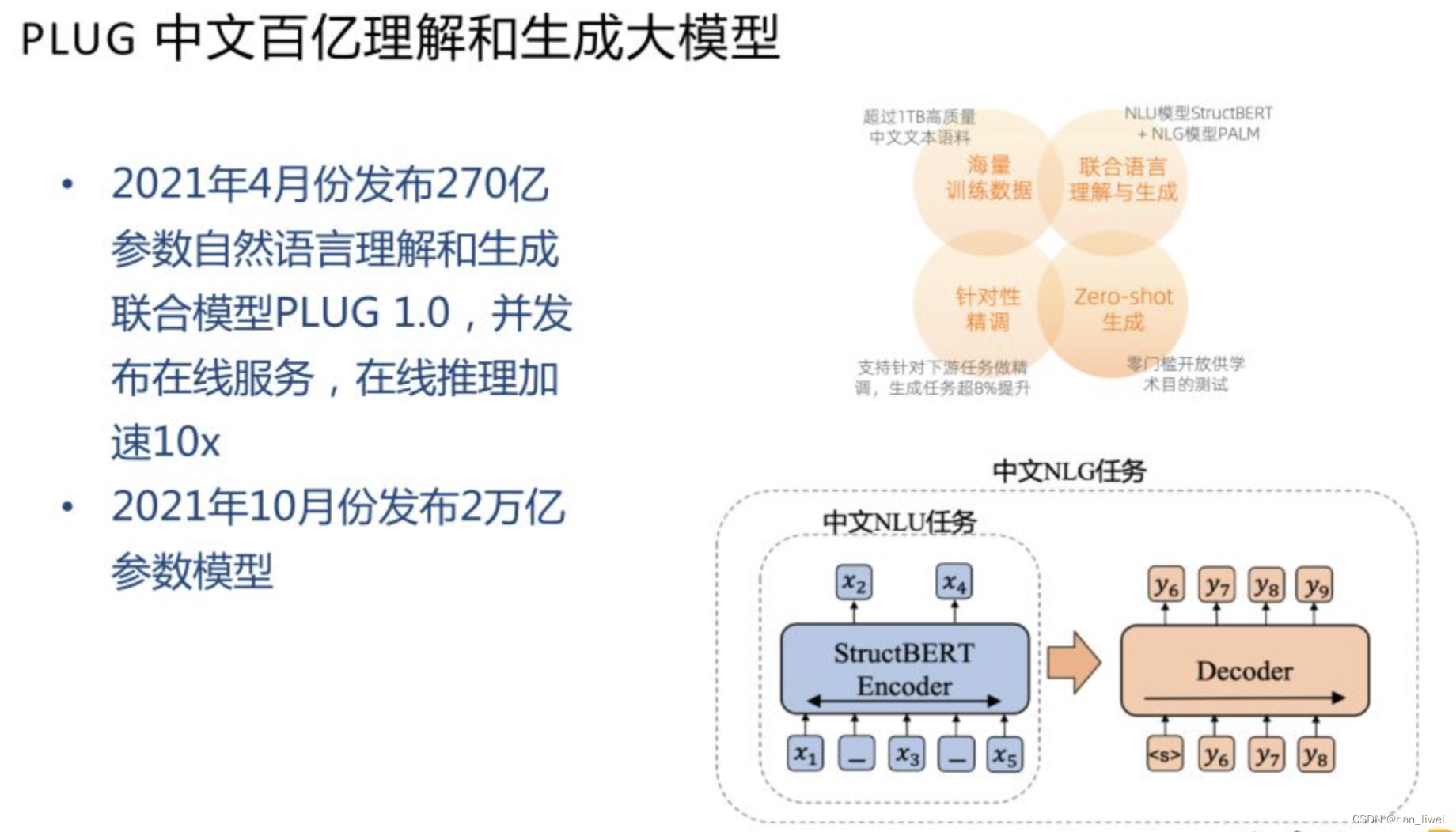
PLUG 中文大模型延续的是 PALM 的思路,结合 NLU 和 NLG 的任务,得到一个理解和生成同时做的模型。NLU 任务是我们自研的 StructBERT 模型,在 BERT的基础上引入三分类以及对词级别打乱。NLG 是 PALM 的自编码自回归结合。训练分为两个阶段,第一阶段是 StructBERT 的思路,把模型大小提升。第二阶段延续 PALM 的思路,用 encoder 做初始化,加上 decoder 之后做生成的训练。这样可以得到一个 Encoder-Decoder 统一理解生成模型。做理解相关任务,比如分类/预测时,只需要把 encoder 部分拿出来,沿用 BERT 的方法。做生成相关任务时,再使用全部的 Encoder-Decoder 架构。这里也做了一些推理加速的工作,和中文 GPT 是相同的技术,获得了 10x 加速的效果。

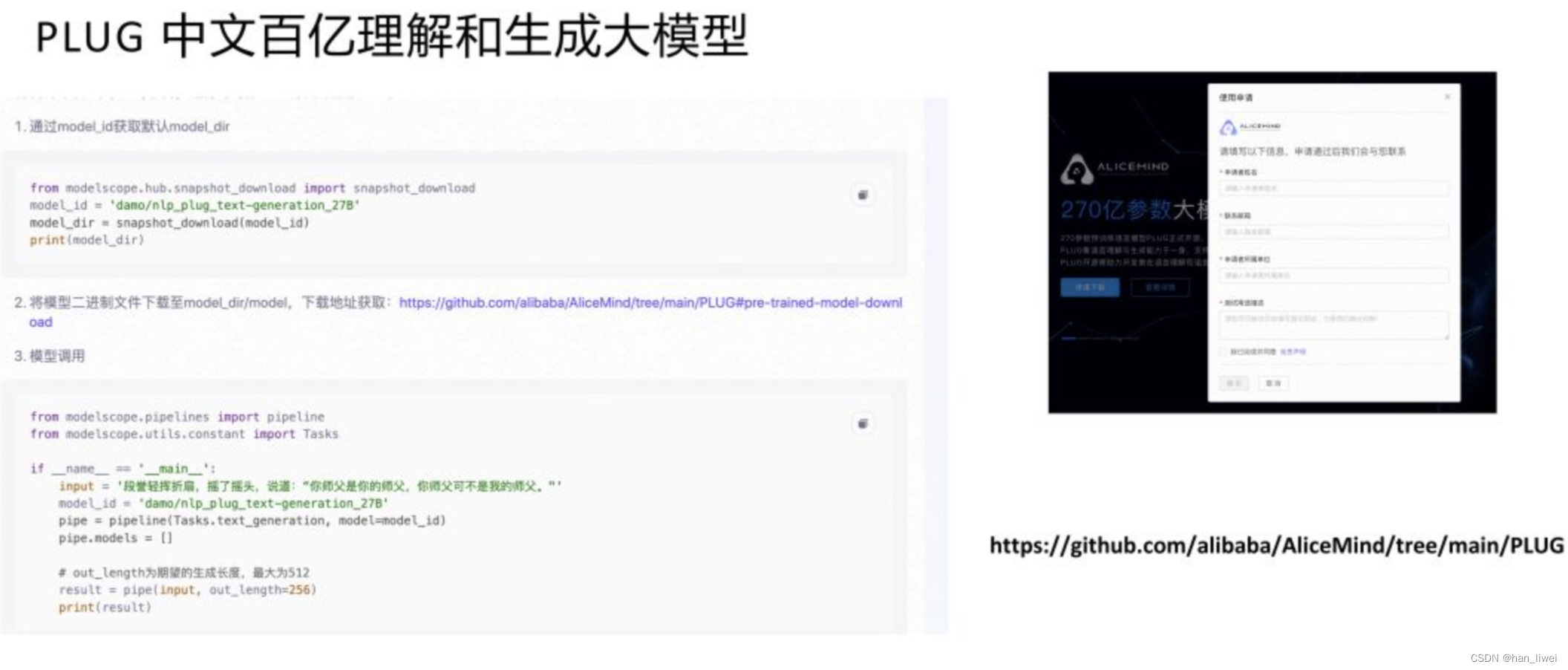
270 亿参数的 PLUG 模型已经在 ModelScope 上开放,大家可以按照流程申请获取下载链接,然后使用 Pipeline 做部署推理。
多模态统一生成预训练模型 mPLUG
多模态相关主要的任务有两种。一个是 VQA,输入图片和针对图片的问题,模型预测答案。另一个是 COCO Caption,输入图片,模型预测图片的描述。
我们提出了多模态统一生成的预训练模型 mPLUG,主要解决的是多模态融合时,视觉特征序列过长导致的低效性和信息淹没问题。Vit 结构的问题是,在切 patch 的过程中,如果切的比较小且图片分辨率高,切下来序列就会很长,序列长会带来训练低效的问题。另外在和文本模态融合的过程中,如果图片数据过长,会淹没一部分文本的信息。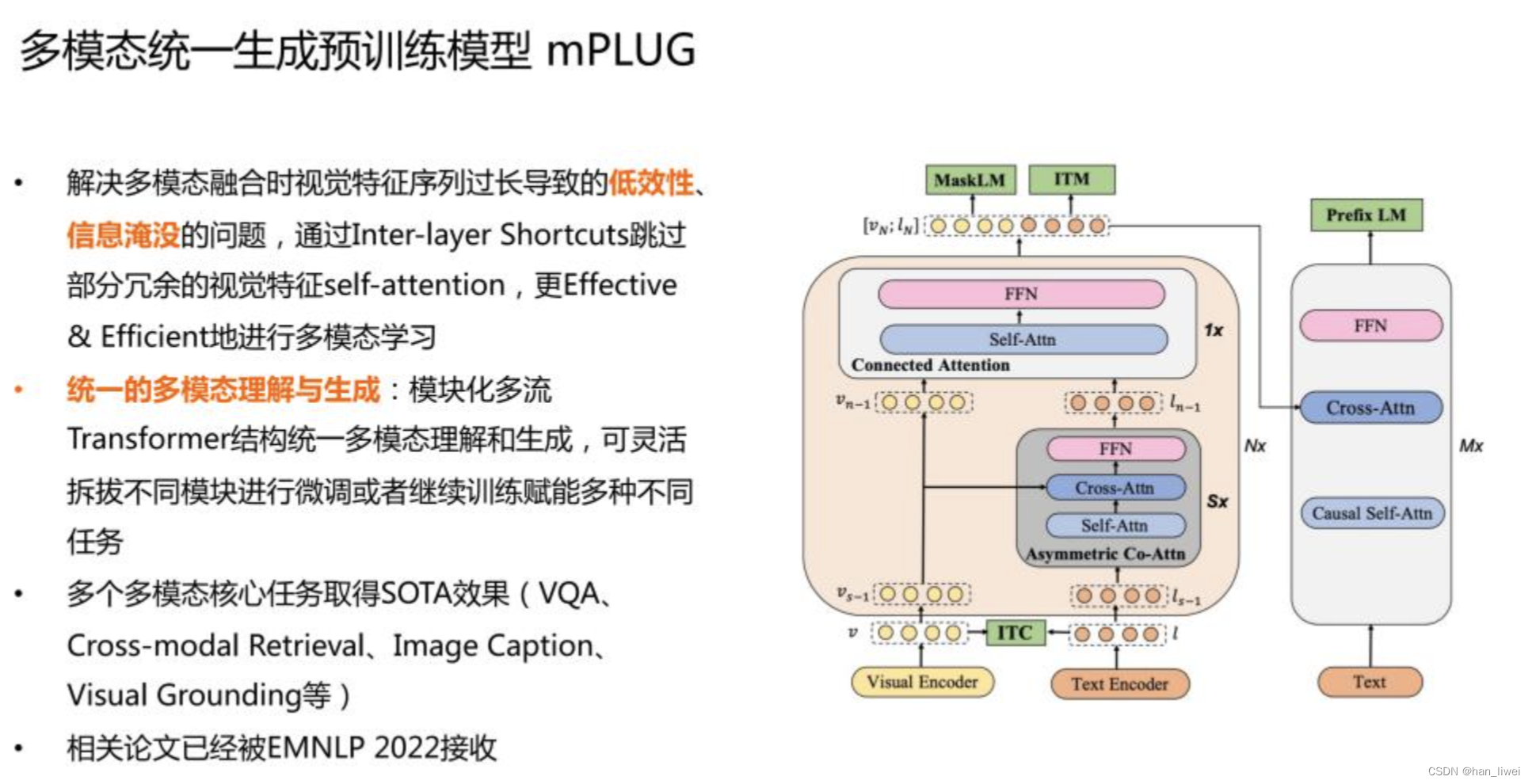
mPLUG 结构的底层还是先分别对文本和图片做编码,之后用对比学习把两个维度的特征拉到同一空间,再传入我们提出的 skip-connection 网络。之前的 co-attention 或者图文拼接的方式会存在信息淹没问题,我们的核心点在于只做非对称的 attention,即只将视觉特征 cross 到文本侧。因为训练速度慢主要在视觉,这样可以极大提升模型训练速度。但是如果只采用这种方式,因为文本序列比较短,会带来视觉信息的丢失。所以我们在 skip-connection 网络里面,先通过一个多层的非对称的 co-attention 网络,之后把视觉信息拼接进来,然后再过一层的 connected attention。这样既可以保证视觉信息不丢失,同时防止文本信息被视觉信息淹没。
以上就是图片和文本信息融合的 encoder,之后再加上 decoder 做生成的预训练。这就是我们整体的架构了。这种架构的优势在,一方面通过这种模块化多流的 Transformer 结构,可以统一理解和生成。同时它又可以灵活地拆拔不同模块进行微调。比如做图文检索任务,可以不要 decoder,只把 vision 和 text encoder 拆出来做向量检索,也可以用 ITM 图文匹配 Score。如果是 caption 任务,则不需要 text encoder,只需要 vision encoder 直接 cross 到 decoder 做图片描述的生成。如果做开放域的视觉问答,则全部的模块都会用到。
这篇关于plug-中文大模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






