本文主要是介绍全球温室气体(GHG)排放数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
气候变化是人类面临的全球性问题,随着各国二氧化碳排放,温室气体猛增,对生命系统形成威胁。在这一背景下,世界各国以全球协约的方式减排温室气体,2020年9月,中国在联合国大会上向世界宣布了2030年前实现碳达峰、2060年前实现碳中和的目标。
今天为大家分享的全球温室气体(GHG)排放数据,数据来源于ClimateTRACE,是一个非营利性组织联盟。

ClimateTRACE网站首页
该组织提供与致力于实现全球净零排放的所有各方相关的信息,使有意义的气候行动更快、更容易。
利用人工智能(AI)和机器学习(ML)等技术来分析来自300多颗卫星、11100多个传感器以及来自世界各地的众多其他排放信息来源的超过59万亿字节的数据,建立一个独立、透明和及时、突破性的排放监测方法。

ClimateTRACE温室气体排放监测

ClimateTRACE农业温室气体放监测

ClimateTRACE工厂温室气体排放监测
ClimateTRACE温室气体排放区域监测
每个下载包都包括2015-2021年按部门和温室气体划分的年度国家级排放量、适用的设施级排放清单以及可用的设施级所有权数据。

全球温室气体排放量分布图
在图上展示的点,可以点击查看详情,可以看到该点的名称、温室气体排放量、该电站/厂区的卫星缩略图。

查看某地点数据
下载数据在网站首页点击“下载数据”,进入下载列表,数据分为行业和国家。
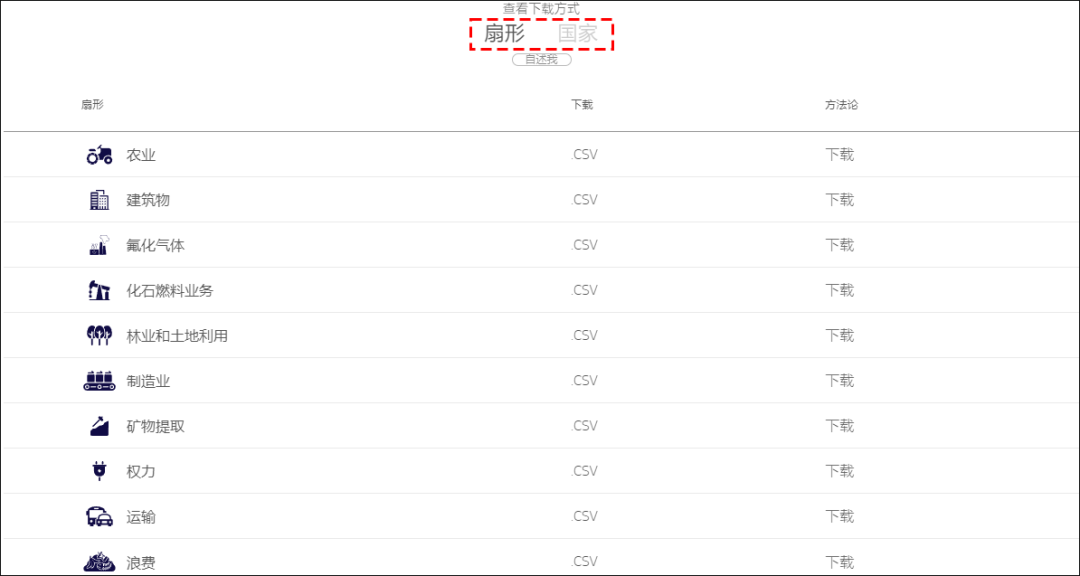
行业分类下载
下载国家数据,选择“国家” 选项,如这里我们以下载“中国”的数据为例,在列表中找到中国,数据是csv格式的,数据分为森林排放量和不含森林排放量两种。
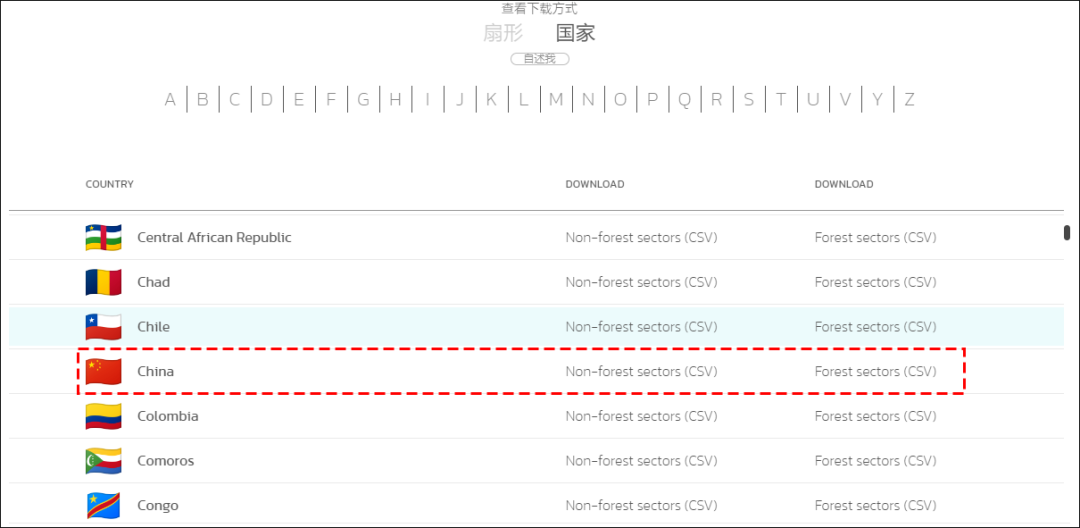
国家分类选择下载数据
下载数据,解压后就可以得到下面所示的文件,文件比较大,用Office和Wps都试过,基本都打不开,估计需要专业工具才行,小编还在研究中,如果你知道用什么打开请在评论区告诉我们!
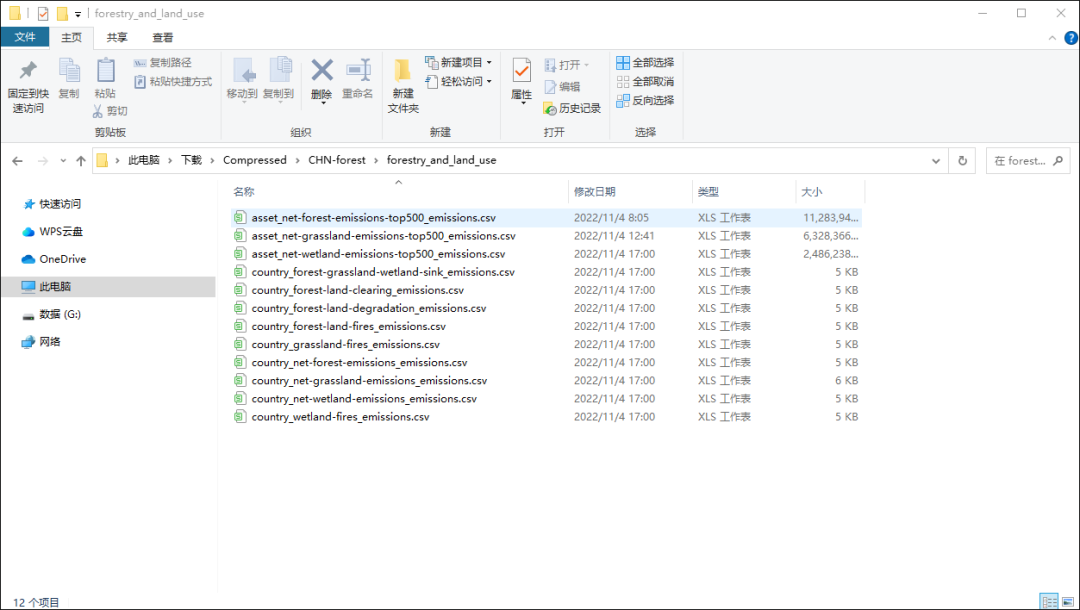
数据列表
这篇关于全球温室气体(GHG)排放数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





