本文主要是介绍R语言【rgbif】——occ_search对待字符长度大于1500的WKT的特殊处理真的有必要吗?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一句话结论:只要有网有流量,直接用长WKT传递给参数【geometry】、参数【limit】配合参数【start】获取所有记录。
当我在阅读 【rgbif】 给出的用户手册时,注意到 【occ_search】 强调了 参数 【geometry】使用的wkt格式字符串长度。
文中如是写道:
当处理 长WKT字符串(>1500个字符) 时,可以通过参数geom_big进行设置:asis:此值为默认值。不做任何处理,只传递WKT字符串。axe:这个选项将使用sf包将WKT字符串切割成数个多边形,然后根据每个多边形块单独进行数据请求,然后将所有数据组合在一起返回。请注意,如果WKT字符串不是多边形类型,将退回到asis,因为没有办法分割线字符串等。这个选项在大多数情况下会比其他两个选项慢。但是,这种多边形分割方法不会像使用bbox选项那样存在想要多少记录和实际返回多少记录之间脱节的问题。该方法使用sf::st_make_grid和sf::st_intersection,它们有两个参数cellsize和n。您可以通过调整geom_size和geom_n来调整这些参数。在切换返回的WKT字符串的数量方面,geom_size似乎更有用。请参阅wkt_parse手动从较大的WKT字符串中分解WKT边界框,或者将较大的WKT字符串分解为许多较小的WKT字符串。bbox:这个选项检查您的WKT字符串是否超过1500个字符,如果是,先从WKT创建一个边界框,使用该边界框进行GBIF搜索,然后将结果数据修剪为仅在原始WKT字符串中出现的数据。但有一个注意事项。因为先从WKT创建了一个边界框,并且limit参数确定了要获取的记录子集,所以当我们将结果数据修剪到WKT时,您获得的记录数量可能少于您使用limit参数设置的记录数量。但是,您可以将限制设置得足够高,以便获得在该边界框中找到的所有记录,然后您将获得WKT中可用的所有记录。
然而,我在尝试【使用rgbif获取非行政单位区域内的物种记录信息】时发现:即使我使用的wkt字符串长度远大于1500,但是直接将它或者用【wkt_parse】方法分割了它的结果传递给【occ_search】方法的【geometry】参数时,结果数据根本没有差异,而结果长度的不同仅仅是因为wkt表达的polygon数量不同造成的独立请求数量不同,有关这方面的信息请参考R语言【rgbif】——什么是多值传参?如何在rgbif中一次性传递多个值?多值传参时的要求有哪些?
简单来说,实际操作中,我发现小心翼翼地处理长WKT字符串完全是多此一举!
那么,真的还有必要使用【wkt_parse】来分割长WKT吗?
下面我将用事实来回答这个问题。
首先,我使用的WKT字符串是在【R语言【rgbif】——使用rgbif获取非行政单位区域内的物种记录信息(以泛喜马拉雅地区为例)】中的 变量【wkt】 和 变量【wkt_for_rgbif】。
变量【wkt】 它的长度nchar(wkt)为8909。符合rgbif对长WKT字符串的定义标准。
变量【wkt_for_rgbif】 是 rgbif 中 wkt_parse 方法将 变量【wkt】变为许多个长度小于1500的非长WKT字符串片段。
for (i in wkt_for_rgbif){print(nchar(i))}

1. 查找的数据量的对比
我先按照用户手册推荐的,使用非长WKT字符串的 变量【wkt_for_rgbif】
-
将 变量【wkt_for_rgbif】 传入 occ_search 的 geometry 参数,limit 参数设置为 0 以只获得数据量,hasCoordinate 参数设置为 TRUE以只统计有坐标信息的记录。
a <- occ_search(limit = 0, hasCoordinate = TRUE, geometry = wkt_for_rgbif)因为参数【geometry】接受了多值输入,向量型的多值输入发起了多次独立请求,所以结果是一个长度为 wkt_for_rgbif 的列表。


-
前文提到了 wkt_for_rgbif 是向量型的多值输入,会发起多次独立请求,进而生成了结果列表。既然提到了多值输入,还有不会发起多次独立请求的字符串型的多值输入。那么将 wkt_for_rgbif 转换为字符串型再传递给 参数【geometry】 时会发生什么呢?
b <- occ_search(limit = 0, hasCoordinate = TRUE, geometry = paste(wkt_for_rgbif, collapse = ";"))
不同类型的多值输入生成的结果数量相同吗?sum_a <- 0 for (i in a){sum_a <- sum_a + i$meta$count} sum_a[1] 6819489b$meta$count == sum_a[1] TRUE意料之中,数量相同。
-
实践出真知,直接用 长WKT字符串 变量【wkt】 又如何呢?
c <- occ_search(limit = 0, hasCoordinate = TRUE, geometry = wkt)
6819489,没有问题!
2. 查找的实际数据的比对
在上面对数据量比对中,我通过参数【limit】设置为0,只获取数据量。
但回头一想, occ_search 单次请求的返回数据量最多为 100000,正是通过参数【limit】实现控制的。前文得知查找到的数据量为 6819489,远超过了单次请求返回数量的上限,假设不考虑拿到所有的 6819489 条数据,只按照参数【limit】默认的 500 条数据来操作,那么使用不同长度的WKT字符串拿到的结果会一样吗?
-
将 变量【wkt_for_rgbif】 传入 occ_search 的 geometry 参数,limit 参数设置为 50,hasCoordinate 参数设置为 TRUE以只统计有坐标信息的记录。
d <- occ_search(limit = 50, hasCoordinate = TRUE, geometry = wkt_for_rgbif)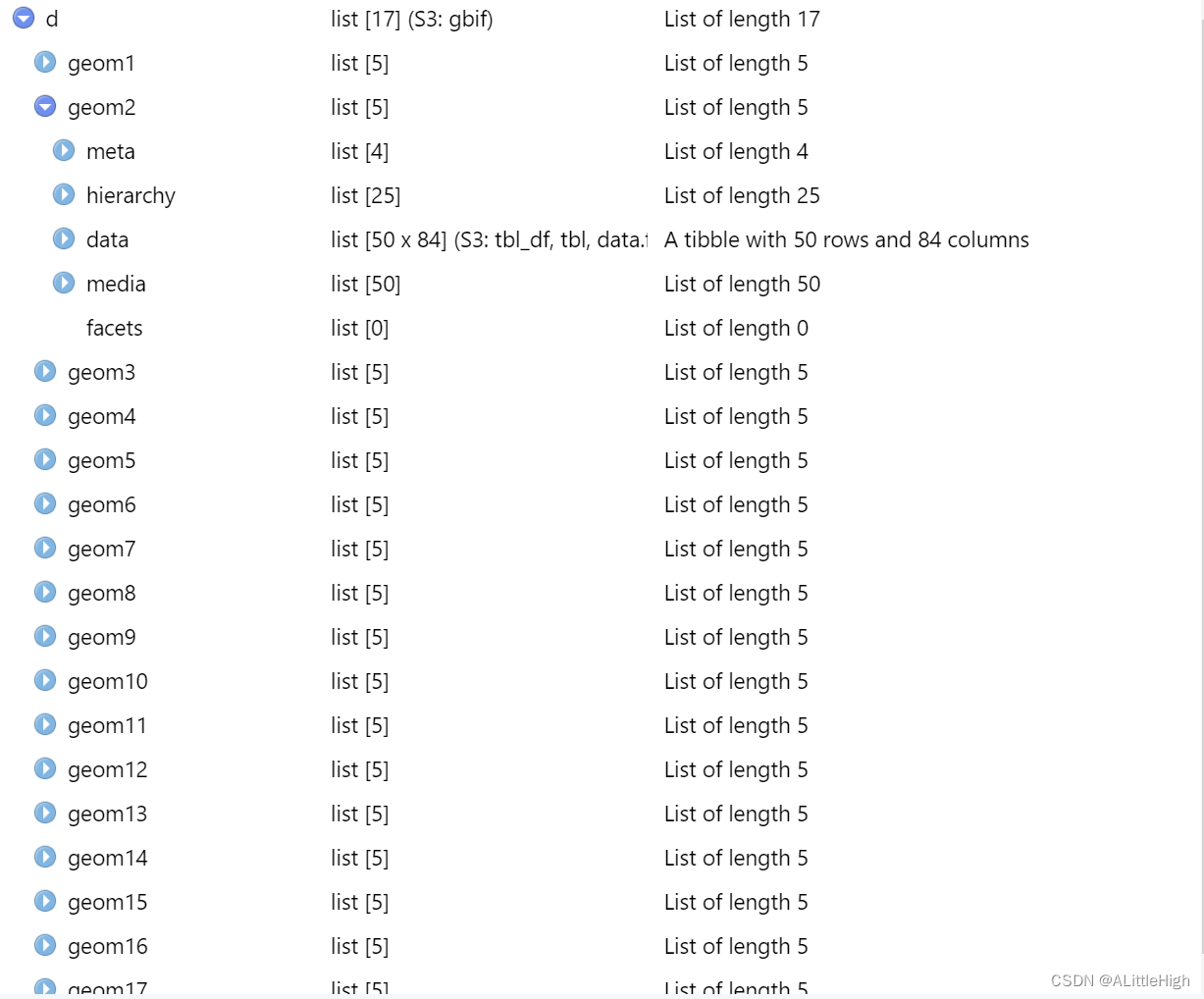
对于返回的结果,我要查看它的数量:sum_d <- c() for (i in d){sum_d <- append(sum_d, nrow(i$data))} sum_d <- sum(sum_d)[1] 768以及数据内容:
sum_d_data <- d$geom1$data for (i in d){sum_d_data <- full_join(sum_d_data, i$data)}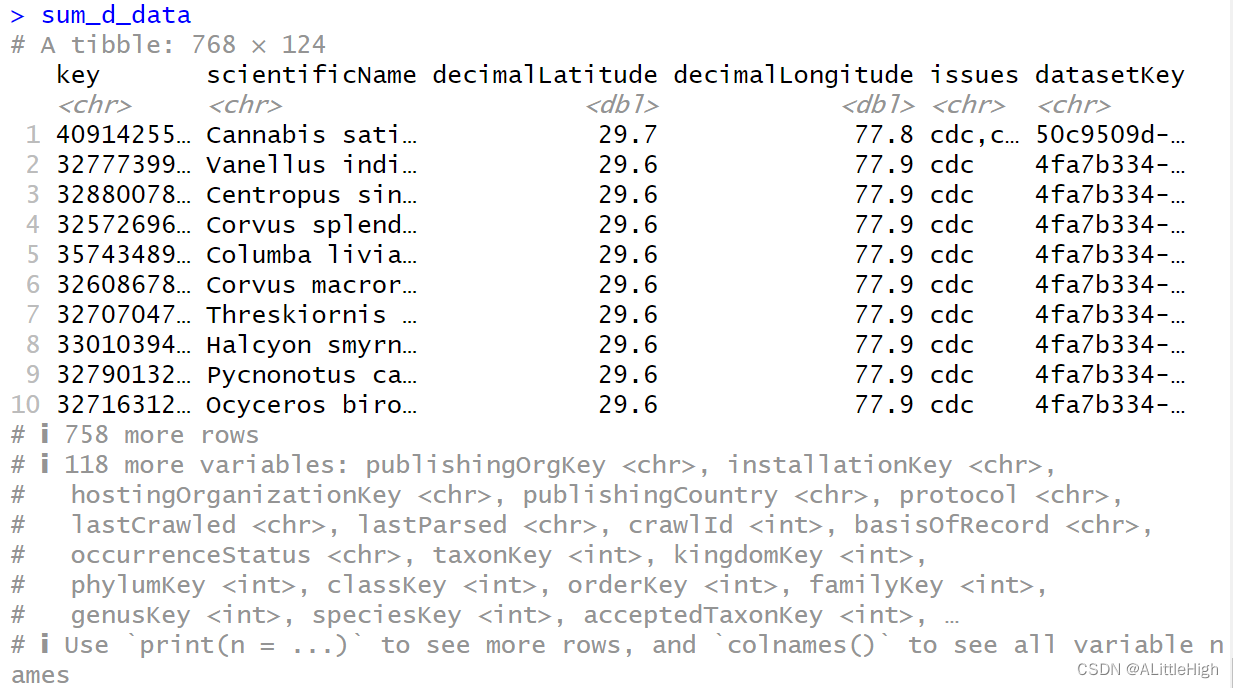
说明 参数【limit】 限制每次独立请求的返回数量上限为 50。 -
将 wkt_for_rgbif 转换为字符串型再传递给 参数【geometry】,limit 参数设置为 50,hasCoordinate 参数设置为 TRUE以只统计有坐标信息的记录。
e <- occ_search(limit = 50, hasCoordinate = TRUE, geometry = paste(wkt_for_rgbif, collapse = ";")) e$data只会返回 50 条数据。
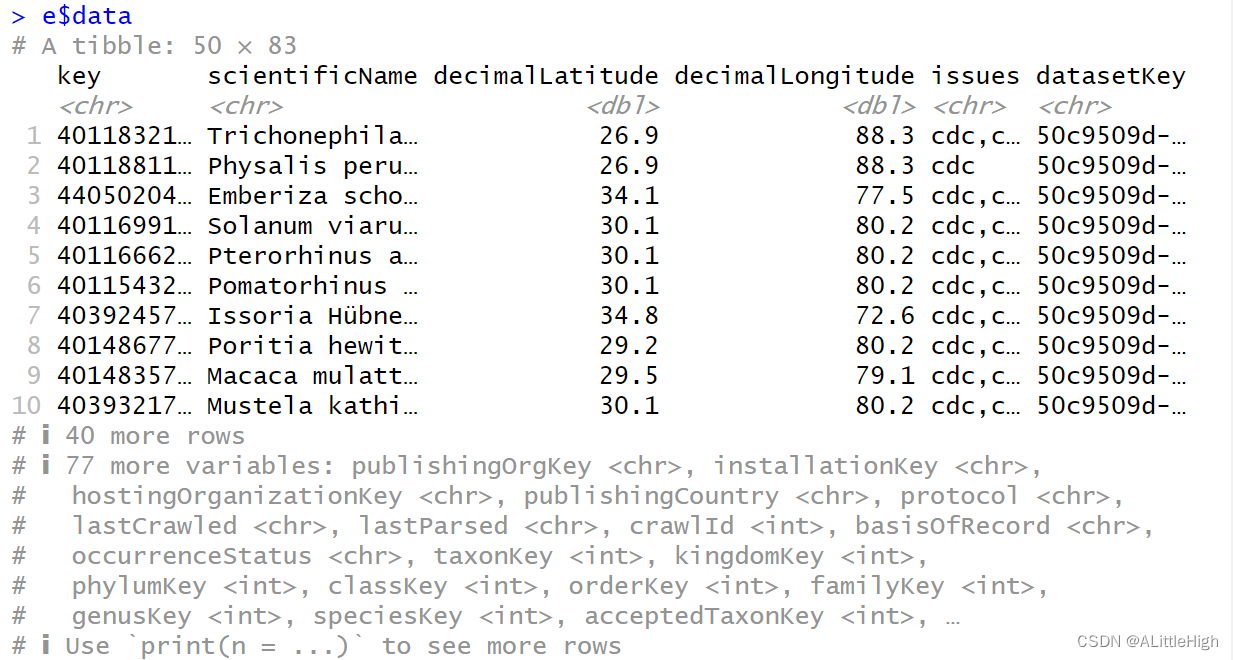
-
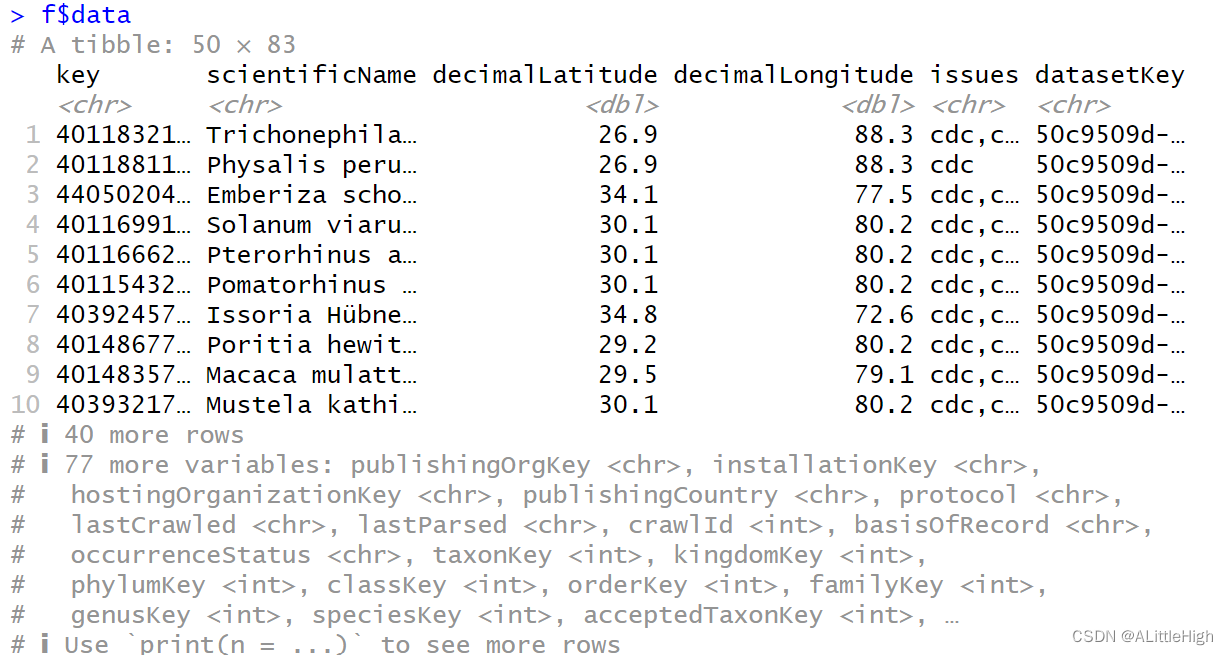
将长WKT字符串 变量【wkt】 传入 occ_search 的 geometry 参数,limit 参数设置为 50,hasCoordinate 参数设置为 TRUE以只统计有坐标信息的记录。
f <- occ_search(limit = 50, hasCoordinate = TRUE, geometry = wkt) f$data这种方式的结果和上一步的结果完全相同。
总结
一般来说,长WKT字符串的处理 是不需要的!因为,利用rgbif从gbif上获取数据时,参数【limit】 更多地用来配合 参数【start】 来获得完整的筛选结果。这么看来,使用 方法【wkt_parse】 分割WKT,然而会让操作更加复杂,增加使用门槛。
这篇关于R语言【rgbif】——occ_search对待字符长度大于1500的WKT的特殊处理真的有必要吗?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


