本文主要是介绍阅读笔记——《UTOPIA: Automatic Generation of Fuzz Driverusing Unit Tests》,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

- 【参考文献】Jeong B, Jang J, Yi H, et al. UTOPIA: automatic generation of fuzz driver using unit tests[C]//2023 IEEE Symposium on Security and Privacy (SP). IEEE, 2023: 2676-2692.
- 【注】本文仅为作者个人学习笔记,如有冒犯,请联系作者删除。
目录
摘要
一、介绍
二、挑战和提出的方法
1、合成有效的API调用序列
2、合成有效的API调用参数
3、利用单元测试存在的挑战
三、设计
1、UT框架结构分析
2、API属性分析
3、模糊目标选择
4、合成模糊驱动程序
4.1、模糊输入分配
4.2、模糊回路构造
4.3、初始种子提取
四、实现
五、评估
1、自动生成模糊驱动程序和其效率
3、与OSS-Fuzz驱动程序比较
4、评估UTOPIA的设计决策
5、实验总结
六、不足
1、虚假崩溃的其他来源
2、UTOPIA分析的局限性
八、结论
摘要
- 模糊测试是检测软件安全漏洞最有效的方法之一。在对库进行模糊测试时,为了提高测试效率,需要构造一个高质量的模糊驱动程序 (Fuzz Drivers),该驱动程序应该要有合适的库API调用序列,能够尽可能地探索库的状态。
- 这种模糊驱动程序一般都是手动编写的,为了减轻负担,现有方法试图通过从消费者代码 (consumer code)中推断API的有效序列,或直接从使用示例中提取有效的API序列来自动生成模糊驱动程序。但这样获得的API序列都与原应用程序逻辑有关。
- 本文发现,单元测试 (Unit Test, UT)是由开发人员精心设计来验证API的正确使用方法的,并且在开发过程中编写单元测试十分常见。
- 【注】单元测试 (UT)是软件开发中的一种测试方法,用于验证软件系统中最小可测试单元的功能是否能按预期进行。这些最小单元通常是软件中的函数、方法或类等独立模块。单元测试的目的是对这些单元进行独立测试,以确保它们在给定输入下产生正确的输出。
- 故本文提出了UTOPIA,一个开源工具和分析算法,可以在几乎零人工参与的情况下,从现有的单元测试中自动生成模糊驱动程序,并通过实验证明了它的有效性。
一、介绍
- 根据测试对象,模糊测试可以分为两种:
- 端到端的模糊测试 (end-to-end fuzzer):将整个程序作为黑盒进行测试。
- 库的模糊测试 (library fuzzer ):针对特定接口或API进行测试。(如libFuzzer)
- 两者的不同在于针对库进行模糊测试需要为其构建一个模糊驱动程序,其中包含了API的调用序列。
- 为了减轻构建模糊驱动程序的负担,有研究通过从消费者代码中推断API的依赖关系,以此来生成高质量的模糊驱动程序。但是这样生成的模糊驱动程序会被消费者代码限制,可能只包含简单、常见的API序列。这对寻找无效、不常见的API序列进行模糊测试并不理想。
- 与推断API序列不同,单元测试中使用的是准确的API调用顺序。我们还观察到:
- 现有的单元测试明确表明了开发人员所关心的API依赖关系。
- 单元测试能比消费者代码检测出更多的库API(如内部API)。
- 许多现有项目都有编写良好的单元测试,如下图。

二、挑战和提出的方法
- UTOPIA将每个现有的单元测试转换为有效的模糊驱动程序,它主要解决下面两个问题以减少整个生成过程中人工的参与。
- 合成有效的API调用序列。
- 合成有效的API调用参数。
- 在模糊驱动程序中,库不仅会因为运行遇到错误而崩溃,还会因为使用上述两个问题导致的无效API而崩溃。这样导致的崩溃被称为虚假崩溃 (spurious crashes),会使得模糊测试无效。
1、合成有效的API调用序列
- 生成模糊驱动程序的一个主要挑战是确定调用库的哪个API以及以什么顺序调用它们,因为API经常具有严格的顺序依赖关系。例如,FileStorage() → writeRaw() → release()。
- 如果只是为模糊驱动程序构建随机的API调用序列,那会浪费大量时间。例如,在release()之后调用writeRaw(),由于其没有调用构造函数,这样导致的崩溃会被认为是虚假崩溃。
- 使用消费者代码推断API序列的局限性:
- 如果要从消费者代码中获取整个API的使用模式,首先需要对整个消费者代码进行分析。如果遇到复杂的消费者代码,其中包含了大量分布在复杂控制流中的API调用,就会存在提取的模式过于臃肿的问题。这样生成的模糊驱动程序会包含大量API调用,需要大量的输入参数,会影响模糊效率。
- 也有方法提出限制生成模糊驱动程序的消费者代码数量,但这样获得的API序列可能并不完整,会导致虚假崩溃。
- 提出的方法
- 本文使用单元测试中编写的显式API序列来完全避免合成API序列的挑战。
- 单元测试 (UT)有以下优势:
- 在UT中,针对每个测试用例显式构建库的状态,意味着在生成模糊测试驱动程序时不需要承担API模式推断或提取的负担。
- UT与模糊驱动程序的目的是一致的,设计的测试用例都是针对开发人员认为非常重要的变量或属性。
- 由于单元测试仅包含用于测试库特定属性的必要API序列,一般不多,所以不容易生成臃肿的API调用序列。
- 【注】这里的测试用例是指单元测试的具体化,有具体的输入和输出。测试用例运行后需要观察输出结果是否与预测输出结果相同。
2、合成有效的API调用参数
- 在推断API调用序列时,还需要了解API内部和API之间的逻辑,并根据它们的语义关系合理地分配模糊输入值。
- 例如,如果将一个用于内存分配或循环计数的参数模糊成一个较大值,就会导致内存不足或超时错误。虽然这些不是虚假崩溃,但它们会影响模糊测试的效率。
- API之间 (inter-API)主要存在以下三种关系:
- out-to-in:一个API的输出作为另一个的输入。
- fixed:同一参数在不同的API调用中应保持一致(如API_1(x); API_2(x);)。
- relative:在不同的API调用中,参数之间存在一定的衍生关系(如x=f(y); API_1(x); z=x+g(y); API_2(z);)
- 【例】var a=3; → b=func(a); → Target_API(b); 这里在模糊测试赋值时,如果不关注API间的调用顺序可能会直接对b进行赋值,而不是a。
- API内部 (intra-API)主要存在以下两种关系:
- array ↔ length:一个输入参数表示另一个输入参数的长度。
- array ↔ index:一个输入参数是另一个输入参数的索引。
- 【例】下图中,Mat类构造函数中的第一个参数要求与第二个和第四个参数中声明的数组大小保持一致。如果这些参数是随机模糊的,模糊驱动程序通常会导致段错误(size参数 > 数组的实际大小),或者浪费精力来改变未使用的模糊输入字节(size参数 < 数组的实际大小)。
- 提出的方法
- UTOPIA通过保留测试单元中的原始数据流(变量的运行状态),使用静态分析找到模糊输入的位置(API参数的位置)以及它们是如何变异的。
- 为了识别注入模糊输入的合适位置,引入了“根定义”这一概念,这是一个赋值语句,其中的变量由常量定义,通过仅在根定义上分配模糊输入,保留原始数据流和现有的API语义关系。简单来说,就是利用根定义标记出需要模糊的参数位置,再利用根定义间接地传入模糊输入。
- 下图中,UTOPIA通过将模糊输入赋值给根定义(第23行,fi8和fi9为模糊输入,即变异后的参数),将模糊输入传递给writeRaw()(API)中的第三个参数rawdata(第31行),其中向量rawdata的每个元素都被赋值为常量。
- 定位根定义后,UTOPIA根据分析的变量,为从根定义接收到的API参数注入模糊输入。例如,在Mat类的构造函数中(第18行),UTOPIA推断出数组的长度,并将dim(数组)的大小分配给第18行上的第一个参数(数组长度),让每个元素都有模糊输入(第17行)。

- 【注】上图是基于OpenCV测试中FileStorage的简化单元测试,通过将矩阵数据编码为XML进行存储和重新加载。基于这个单元测试,UTOPIA 生成了一个模糊驱动程序(差异使用 -/+ 标记)。全局变量fi{1-9}是每次运行的变异模糊输入。
3、利用单元测试存在的挑战
- 分析障碍 (Analysis hindrance)
- 单元测试 (UT)框架可能由复杂的类层次结构和接口混合定义,这些接口被用来间接调用用户定义的测试用例。通过这些接口进行间接调用可能导致单元测试生成的模糊驱动程序出现虚假崩溃,因此在进行模糊测试之前需要手动修复这些问题。
- 动态分析虽然可以处理间接调用,但存在过度近似和难以处理参数值之间关联语义的问题,因此不适合解决这类问题。
- UT框架的多样性 (UT framework diversity)
- 由于各个UT框架的差异性,解决分析障碍 (Analysis hindrance)中的问题可能需要根据每个框架的特点进行不同的处理和修复。如果这些问题需要通过手动方式逐一修复,将会耗费大量的时间和人力。
- 断言 (Assertion)
- 由于UT中的断言不仅用于检查临界状态,而且还可用于验证结果是否与单元测试中定义的特定测试值相匹配,因此,必须考虑断言是如何影响模糊测试的,并适当处理这些断言,因为将模糊输入注入到参数中可能会触发断言条件。
- 如果忽略所有断言,那么对指针进行的nullptr检查将更可能因为对nullptr进行解引用而出现虚假崩溃。但是,如果所有断言都被强制执行,测试值的检查通常会阻止模糊驱动程序在断言语句之后继续执行。
三、设计
- UTOPIA通过分析UT和目标库代码,将UT转换为有效的模糊驱动程序。下图是UTOPIA的整体工作流程。

- UTOPIA利用了UT框架的架构特性,因此只需要分析开发人员实现的测试功能,而不需要分析整个UT框架。
- UTOPIA分析库以识别API参数的属性。
- 执行UT以识别根定义,在不影响有效API使用语义的情况下注入模糊输入。
- 根据分析结果生成模糊驱动程序。
1、UT框架结构分析
- 一般来说,UT框架提供的API允许用户为每个测试用例定义三个功能:预测试、测试和后测试。以GoogleTest(gtest,一种UT)为例,如下图,它向每个测试类公开了SetUp()、TestBody()和TearDown()接口(分别对应预测试、测试和后测试)。
- 这些函数隐式地确保了一下两点:
- 每个测试用例仅依赖于这些函数。
- 测试用例彼此独立。
- UTOPIA利用这些特性在模糊测试循环中显式调用这些函数,以构建有效的API序列,以确保每个模糊测试循环的独立性。
- Clang AST匹配器 (Clang AST Matchers)
- 此外,UTOPIA利用Clang AST Matchers(一种工具)来定位这些函数。它使用clang AST Matchers来查找具有抽象语法树 (AST)模式的函数。例如,在上图中,UTOPIA在其子节点中查找CXXRecordDecl,并将Test::Test类作为CXXCtorInitializer。然后通过在找到的CXXRecordDecl中搜索名称为SetUp的CXXMethodDecl来找到SetUp。
- 其他方法类似。为了支持新的UT框架,开发人员只需要指定测试函数的模式,这样就减少了支持不同UT框架的工作量。

2、API属性分析
- UTOPIA将库所有导出函数视为公开的API,并分析每个API的参数以确定其属性。UTOPIA通过利用从API参数开始的自定义使用链来分析程序,以确定五个属性:Output、FilePath、AllocSize、LoopCount和Array↔Length(索引)。
- Output:表示一个参数用于向API的调用者输出某些值,类似于return。
- FilePath:表示文件操作中用作文件路径的参数。
- AllocSize:表示指定分配大小的参数。
- LoopCount:表明该参数决定了库中循环的计数器。
- Array:表示库代码中用作数组的参数。
- Length:表示库代码中数组的长度。
- Def-Use (DU) chain
- 属性分析专注于库内部针对参数的行为,分析沿着参数的定义-使用链跟踪参数的使用情况,该链连接了参数的定义以及从该定义可达的所有使用情况,以确定参数是否具有特定的属性。
- Inter-procedural analysis
- UTOPIA基本上是针对每个函数进行分析的。如果一个定义-使用链中的使用指出了一个子程序调用的参数,UTOPIA首先会分析被调用函数,然后合并被调用函数相应参数的分析结果。在涉及外部函数调用的情况下,UTOPIA还支持加载其他库的预先分析结果,以获得有关外部函数更精确的结果。
- UTOPIA的分析流程如下图:

3、模糊目标选择
- 在确定的目标中,UTOPIA可以适当地向调用库API的参数(即参数的根定义)中插入模糊输入。这是通过查找根定义来实现的。
- 根定义分析 (Root definition analysis)
- 根定义分析是一种反向数据流分析,其目的是获得右值为常数值的定义,这些常量值不能是从测试代码中其他变量派生出来的。因此,根定义使UTOPIA能够在不违反测试代码语义的情况下注入模糊输入。并且UTOPIA会对所有API参数执行根定义分析,以收集每个可能的模糊目标候选项。
- 如下图,'int A=10'是识别到的唯一根定义。根定义的右值变化影响着每个API的参数,同时保持API之间的关系。为了确定所有可能影响API参数的定义,分析是控制流敏感的和跨过程的,以找到所有可能影响API参数的定义。
- 参数属性的继承 (Inheritance of parameter attributes)
- 为了确定突变策略,UTOPIA必须将根定义与相应参数的属性进行配对。这是通过将参数的属性分配给直接使用这些参数的根定义来实现的。
- 例如,上图中,根定义'int A = 10'具有API_1和API_2的第一个参数的属性。但是,API_4的第一个参数的属性没有被继承,因为根定义没有直接用于该参数。在根定义分析期间,通过'int C = API_3(B)'将跟踪目标从C更改为B。
- 外部函数的推断 (Inference of external functions)
- 如果跟踪目标是由外部函数定义的,UTOPIA将跟踪所有输入参数,以查找所有可能的定义。

4、合成模糊驱动程序
4.1、模糊输入分配
- UTOPIA通过用模糊输入赋值语句替换已识别的模糊目标,将每个测试用例转换为模糊驱动程序。在已识别的模糊目标中,如果无法修改其源代码或无法确定生成模糊输入的适当方法,则UTOPIA会排除某些根定义。排除标准如下:
- 头文件或项目文件中的根定义。
- 在编译时确定的常量,如sizeof(int)。
- 赋值带有外部函数的返回或输出参数(非输入参数)。
- 根定义带有nullptr赋值,因为不知道如何初始化指针引用的对象。
- 函数指针参数。
- 依赖于忽略值的值,如忽略Array的ArrayLen。
- 文件属性。
- 排除后,UTOPIA根据赋值语句的数据类型和变异策略,将赋值语句的右值替换为模糊输入。
- UTOPIA遵循以下突变策略来符合API语义:
- FilePath:将模糊输入传递给文件内容而不是文件路径。
- AllocSize:限制用作内存分配大小的参数的模糊输入范围。
- LoopCount:限制用作循环退出条件的参数的模糊输入范围。
- Array:将模糊输入视为数组,即创建一个数组并将模糊输入分配给数组的每个元素。
- ArrayLength/Index:将模糊输入限制为创建的数组大小减一。
4.2、模糊回路构造
- UTOPIA构建了一个入口函数,在每个模糊测试循环中调用一次。入口函数从模糊测试引擎(如libfuzzer)接收模糊输入,并按顺序识别和调用的测试函数(如gtest中的SetUp()、 TestBody()和TearDown())来执行带有指定模糊输入的模糊驱动程序。
4.3、初始种子提取
- UTOPIA在UT分析期间获取了嵌入在测试代码中的初始种子语料库,即根定义中确定为模糊目标的常数值。这些初始种子允许模糊驱动程序在模糊测试的早期阶段达到深层程序状态,并帮助模糊器探索到深层路径。
四、实现
- 本次研究使用了39000行代码来实现UTOPIA。其中,37000行代码是用于分析库和单元测试以及生成模糊驱动程序的C/C++代码,而剩余的2000行代码是用Python脚本来支持和简化整个分析和生成过程。
- 用于分析和模糊测试驱动程序合成的代码利用了LLVM/Clang的分析框架,将单元测试代码转换为模糊驱动程序是通过Clang AST Matcher和Libtooling实现的。
- 【注】LLVM是一个通用的编译器基础设施项目,而Clang是LLVM项目中针对C/C++/Objective-C的编译器前端。二者结合使用,能够提供强大的编译器工具链和性能优化能力。
- Clang AST Matcher提供了在Clang AST中进行模式匹配和搜索的功能,而LibTooling则为开发人员提供了创建基于Clang的自定义编译器工具的框架和API。
五、评估
- 本文从下面几个方面对UTOPIA进行评估:
- 自动化 (Automation)
- 有多少基于单元测试的项目可以被UTOPIA自动转换?生成的模糊驱动程序效果如何?
- 模糊测试效率 (Fuzzing effectiveness.)
- 在代码覆盖率和存在Bug方面,与手工编写的模糊驱动程序相比,UTOPIA生成的模糊驱动程序如何?
- 对比 (Comparison)
- UTOPIA与现有的自动生成模糊驱动程序的方法相比如何?
- 设计决策 (Design decisions)
- UTOPIA减少了多少虚假崩溃,处理断言的最佳策略是什么,分析API属性的效果如何?
- 自动化 (Automation)
1、自动生成模糊驱动程序和其效率
- 如下图所示,在项目中的5523个测试用例中,作者排除了1039个使用原型实现中未处理的宏函数实现的测试用例,即除了TEST和TEST F(用于gtest)或BOOST AUTO TEST CASE FIXTURE(用于boost)(Oths)之外的测试用例。
- 对于剩余的4,484个测试用例,根据文章的排除标准,在确定根定义的过程中,UTOPIA删除了1,769个测试用例(占检查的4,484个测试用例的39%)。
- 总的来说,UTOPIA自动从这些项目中可行的候选TC中生成了2715个模糊驱动程序。

- 总共发现了123个Bug,其中109个是在25个OSS项目中生成的2715个模糊驱动程序的短时间运行发现的,其中有56个得到维护者的确认或修复;14个是在30个Tizen原生库生成的2411个fuzz驱动程序的大约两周发现的,其中一些已经潜伏长达七年,这些Bug都被Tizen确认。UTOPIA在测试用例中使用完全相同的API序列但仍发现了新的错误,这说明利用TCs可以发现开发人员在测试期间错过的新类型的bug。使用UTOPIA为Tizen的30个项目生成了模糊驱动源代码,被该社区采用。
3、与OSS-Fuzz驱动程序比较
- 手动编写的模糊驱动应用在OSS-FUZZ上和自动生成模糊驱动的UTOPIA覆盖率对比:
- 如上面两图所示,UTOPIA的模糊驱动程序在6个项目中有4个项目的表现平均高出20.5%,在2个项目中表现不佳(平均为9.7%),但都存在unique coverage。


4、评估UTOPIA的设计决策
- 断言的不同处理方式对模糊测试的影响
- 如下图所示。可以看到忽略断言会对模糊测试产生不利影响。
- 如下图所示。可以看到忽略断言会对模糊测试产生不利影响。
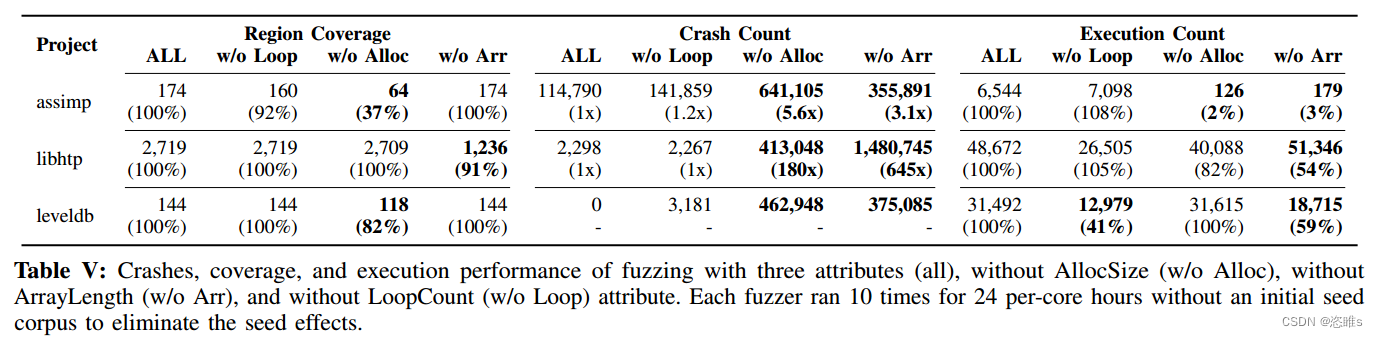
- 通过库分析获得的分析属性ArrayLength、AllocSize和LoopCount对减少由有害模糊输入引起的虚假崩溃和崩溃的影响
- 为了进行评估,我们从三个项目中选择了模糊驱动程序,这些项目通过删除其中一个属性进行比较来测试带有三个属性的API参数。如下图所示,没有ArrayLength或AllocSize属性的设置会导致崩溃的急剧增加,最多增加两个数量级,而覆盖率则略有增加。另一方面,如果没有LoopCount属性,在崩溃时不会观察到任何差异,但是exec/sec性能会显著下降,最高可达40%。对于assimp项目,当移除AllocSize属性时,与包含属性相比,覆盖率和exec/sec分别减少到37%和2%。在libtp项目的情况下,没有ArrayLength属性,覆盖率和exec/sec性能较差,崩溃增加了645倍。此外,leveldb中LoopCount的省略将exec/sec性能降低到41%。

5、实验总结
- UTOPIA可以实现几乎零人工参与的从现有的单元测试中有效合成模糊驱动。
- 成功将UTOPIA应用于55个开源项目库,包括Tizen和Node.js,并从8K个合格的单元测试中自动生成5K个模糊驱动程序。
- 每核小时执行约500万次生成的fuzzers,发现了123个Bug。
- 2.4K生成的模糊驱动程序被应用到Tizen的持续集成过程中,表明了UTOPIT生成的模糊驱动的有效性。
六、不足
1、虚假崩溃的其他来源
- 非常规关系
- 对一些非常规和高度自定义的参数和关系用法无法生成模糊驱动。
- 错误处理不足
- 开发人员在进行单元测试时会跳过对对象的正确构造和分配检查,硬编码一些非必要的参数,这种UT在成为模糊测试驱动时可能导致虚假报错。
2、UTOPIA分析的局限性
- 文件路径的根定义
- 在某些测试用例中,文件路径字符串是通过多个字符串操作创建的。在这种情况下,如果UTOPIA创建一个用于模糊测试的文件,并在字符串的根定义处(在所有操作之前)分配其路径,则API访问的实际路径将是不正确的,为了避免这种情况,UTOPIA启发式地将生成的模糊文件路径分配给API之前最接近的字符串操作。然而,由于这种启发式,UTOPIA可能无法在生成的模糊驱动程序中反映原始UT逻辑。
- 逻辑中的常数值别名
- 当测试用例直接使用常量值时UTOPI可能难以生成合适的模糊驱动程序。
八、结论
- 在本文中,我们提出了UTOPIA,它可以从可用的单元测试中自动生成模糊驱动,而不需要或只需要很少的人为干预。它不仅理解单元测试框架的语义结构,而且还分析被测试的每个库的API的实现。因此,UTOPIA能够以可扩展的方式产生具有有效API调用序列的众多模糊驱动程序。
- UTOPIA成功地为55个流行的开源项目生成模糊驱动程序,证明了UTOPIA可以被广泛应用。
- 评估显示,与手工制作的fuzzers相比,UTOPIA可以在6个项目中的4个项目中实现更高的代码覆盖率(平均20.4%),同时为开发人员提供有趣的API。更重要的是,UTOPIA在55个开源项目中发现了123个新Bug。
这篇关于阅读笔记——《UTOPIA: Automatic Generation of Fuzz Driverusing Unit Tests》的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








