本文主要是介绍论文阅读:《Learning Universal Policies via Text-Guided Video Generation》,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
题目:通过文本引导视频生成学习通用策略
摘要
人工智能的目标是构建一个可以解决各种任务的代理。文本引导图像合成的最新进展已经产生了具有生成复杂新颖图像的令人印象深刻的能力的模型,展示了跨领域的组合泛化。受这一成功的激励,我们研究了此类工具是否可用于构建更通用的代理。具体来说,我们将顺序决策问题转化为以文本为条件的视频生成问题,其中,给定期望目标的文本编码规范,规划器合成一组描述其未来计划行动的未来帧,然后从生成的视频中提取动作。通过利用文本作为潜在的目标规范,我们能够自然地、组合地推广到新的目标。所提出的策略视频公式可以进一步在统一的图像空间中表示具有不同状态和动作空间的环境,例如,可以实现跨各种机器人操作任务的学习和泛化。最后,通过利用预训练的语言嵌入和互联网上广泛使用的视频,该方法通过预测真实机器人的高度逼真的视频计划来实现知识转移。
介绍
构建解决各种任务的模型已成为视觉和语言领域的主导范例。在自然语言处理中,大型预训练模型已经展示了对新语言任务的出色的零样本学习能力。同样,在计算机视觉中,很多学者提出的模型已经显示出卓越的零样本分类和对象识别能力。自然的下一步是使用此类工具来构建可以跨多种环境完成不同决策任务的代理。
然而,训练此类智能体面临着环境多样性的固有挑战,因为不同的环境以不同的状态动作空间运行(例如,MuJoCo 中的联合空间和连续控制与 Atari 中的图像空间和离散动作有根本的不同)。这种多样性阻碍了跨任务和环境的知识共享、学习和泛化。尽管在序列建模框架中使用通用标记对不同环境进行了大量努力,但尚不清楚这种方法是否可以保留嵌入在预训练视觉和语言模型中的丰富知识,并利用这些知识转移到下游强化学习(RL) 任务。此外,很难构建指定跨环境的不同任务的奖励函数。
在这项工作中,我们通过利用视频(即图像序列)作为在不同环境中传达动作和观察行为的通用界面,以及利用文本作为表达任务描述的通用界面来解决环境多样性和奖励规范方面的挑战。特别是,我们设计了一个视频生成器作为规划器,它按顺序以当前图像帧和描述当前目标(即下一个高级步骤)的文本片段为条件,以生成图像序列形式的轨迹,然后逆动力学模型用于从生成的视频中提取底层动作。这种方法允许利用语言和视频的通用性来泛化不同环境中的新目标和任务。具体来说,我们使用视频扩散实例化以文本为条件的视频生成模型。然后从合成框架中回归一组基本动作,并用于构建策略来实施计划的轨迹。所提出的模型 UniPi 如图 1 所示。
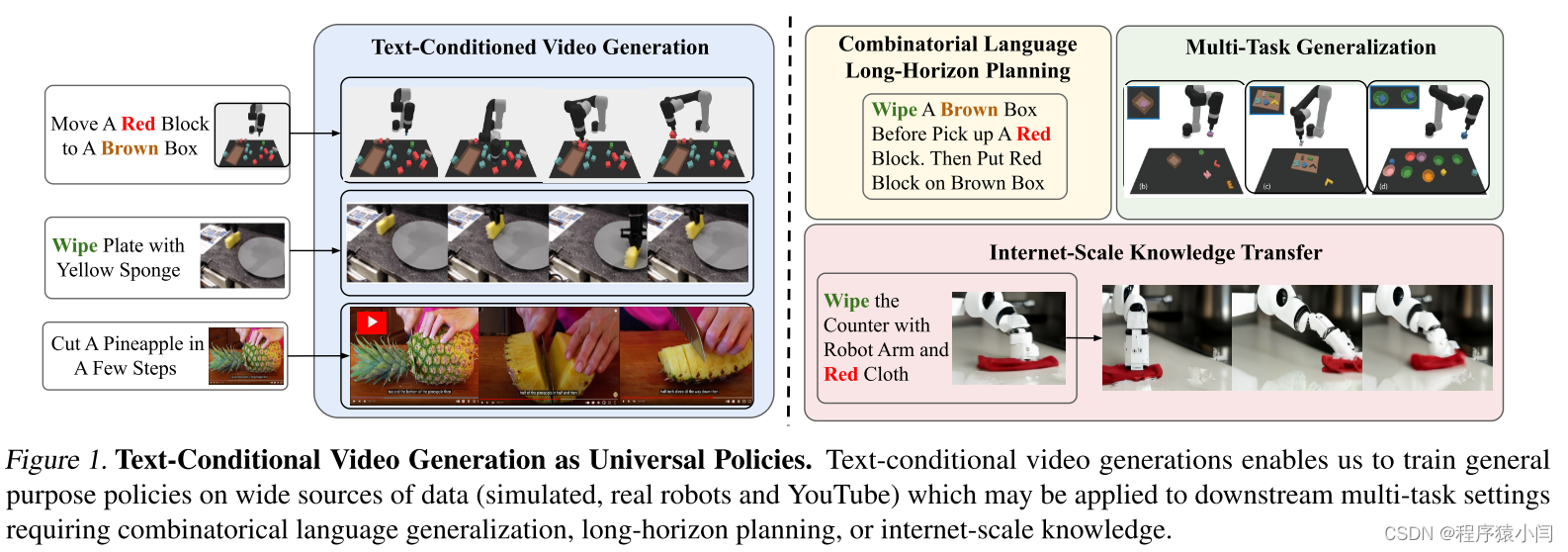
我们发现通过以文本为条件的视频合成制定策略生成具有以下优点:
1、组合泛化。可以利用语言丰富的组合性质来合成环境中新颖的组合行为。这使得所提出的方法能够将对象重新排列为新的未见过的几何关系组合,如第 4.1 节所示。
2、多任务学习。将动作预测表述为视频预测问题可以轻松实现跨许多不同任务的学习。我们在第 4.2 节中说明了这如何能够跨语言条件任务进行学习,并在测试时推广到新任务,而无需进行微调。
3、动作规划。视频生成过程对应于规划过程,其中生成代表动作的帧序列以达到目标。这样的规划过程自然是分层的:首先可以生成朝向目标的时间稀疏图像序列,然后再使用更具体的计划进行细化。此外,规划过程是可操纵的,因为规划的生成可能会因测试时通过测试时采样引入的新约束而产生偏差。最后,规划在人类可以自然解释的视频空间中生成,使行动验证和计划诊断变得容易。我们在表 2 中说明了分层抽样的有效性,在图 5 中说明了可操纵性。
4、互联网规模的知识转移。通过在从互联网上恢复的大规模文本视频数据集上预训练视频生成模型,人们可以恢复大量的“演示”存储库,帮助在新环境中构建文本条件策略。我们在第 4.3 节中说明了如何根据给定的自然语言指令真实地合成机器人运动视频。
这项工作的主要贡献是将文本条件视频生成制定为通用规划策略,从中可以合成不同的行为。虽然这种方法与 RL 中的典型策略生成不同,后者要执行的后续操作是直接从当前状态预测的,但我们证明 UniPi 在各个领域都比传统策略生成方法表现出显着的泛化优势。
问题描述
我们首先激发一种新的抽象,即统一预测决策过程 (UPDP),作为强化学习中常用的马尔可夫决策过程 (MDP) 的替代方案,然后展示具有扩散模型的 UPDP 实例。
马尔可夫决策过程
马尔可夫决策过程是一个广泛的抽象,用于制定许多顺序决策问题。许多强化学习算法源自 MDP,并取得了经验上的成功,但现有算法通常无法跨不同环境进行组合泛化。这种困难可以追溯到底层 MDP 抽象的某些方面:
1、缺乏跨不同控制环境的通用状态接口。事实上,由于不同的环境通常具有独立的底层状态空间,因此需要构建一种复杂的状态表示来表示所有环境,这使得学习变得困难;
2、MDP 中对实值奖励函数的明确要求。 RL 问题通常被定义为最大化 MDP 中的累积奖励。然而,在许多实际应用中,如何设计和转移奖励并不明确,并且在不同环境中也有所不同。
3、MDP 中的动力学模型依赖于环境和代理。具体来说,表征动作 a 下状态之间转换的动力学模型
明确依赖于智能体的环境和动作空间,而不同的智能体和任务之间可能存在显着差异。
UPDP(统一的预测决策过程)
这些困难激励我们构建一种替代抽象,以便跨多种环境进行统一的顺序决策。我们的抽象称为统一预测决策过程(UPDP),利用图像作为跨环境的通用界面,利用文本作为任务说明符以避免奖励设计,以及与环境相关的控制分离的任务不可知的规划模块,实现知识共享和泛化。
首先,将UPDP定义为一个元组,其中
表示图像的观测空间,
表示文本任务描述的空间。
UPDP可以理解为对MDP进行隐式规划,并在指令下直接输出最优轨迹。 UPDP 的抽象绕过了奖励设计、状态提取和显式规划,并允许基于图像的状态空间的非马尔可夫建模。然而,在 UPDP 中学习规划器需要视频和任务描述,而传统的 MDP 不需要此类数据,因此 MDP 还是 UPDP 更适合给定任务取决于可用的训练数据类型。尽管与 MDP 相比,非马尔可夫模型以及视频和文本数据的要求在 UPDP 中带来了额外的困难,但可以利用已在大规模网络规模数据集上进行预训练的现有大型文本视频模型来减轻这些复杂性。
UPDP的扩散模型
我们从无条件模型开始。连续时间扩散模型定义前向过程 qk(τk|τ) = N(·; αkτ, σ2 kI),其中 k ∈ [0, 1] 和 αk, σ2 k 是具有预定义计划的标量。还定义了生成过程 p(τ),它通过学习去噪模型 s(τk, k) 来反转前向过程。相应地,可以通过使用祖先采样器或数值积分来模拟这个逆过程来生成τ。在我们的例子中,无条件模型需要进一步适应文本指令 c 和初始图像 x0 的条件。将条件降噪器表示为 s(τk, k|c, x0)。 。在我们的例子中,无条件模型需要进一步适应文本指令 c 和初始图像 x0 的条件。将条件降噪器表示为 s(τk, k|c, x0)。我们利用无分类器指导,并使用 sˆ (τk, k|c, x0) = (1 + ω)s(τk, k|c, x0) − ωs(τk, k) 作为采样逆过程中的降噪器,其中 ω 控制文本和第一帧调节的强度。
通过视频做出决策
接下来我们详细描述我们提出的方法 UniPi,它是扩散 UPDP 的具体实例。 UniPi 结合了第 2 节中讨论并如图 2 所示的两个主要组件:(i) 基于通用视频的规划器 ρ(·|x0, c) 的扩散模型,它合成以第一帧和任务为条件的视频描述; (ii) 特定于任务的动作生成器 π(·|{xh}H h=0, c),它通过逆动力学建模从生成的视频中推断出动作序列。
Universal Video-Based Planner
受到最近文本到视频模型成功的鼓励,我们寻求构建一个视频扩散模块作为轨迹规划器,它可以在给定初始帧和文本任务描述的情况下忠实地合成未来的图像帧。然而,所需的规划器偏离了文本到视频模型中的典型设置,该模型通常在给定文本描述的情况下生成不受约束的视频。通过视频生成进行规划更具挑战性,因为它要求模型能够生成从指定图像开始的受限视频,然后完成目标任务。此外,为了确保视频中合成帧的有效动作推断,视频预测模块需要能够跟踪合成视频帧的底层环境状态。
Conditional Video Synthesis
为了生成有效且可执行的计划,文本到视频模型必须从当前观察到的图像开始合成受约束的视频计划。解决此问题的一种方法是修改无条件模型的底层测试时间采样过程,将生成的视频计划的第一帧固定为始终从观察到的图像开始。然而,我们发现这种方法表现不佳,并导致视频计划中的后续帧与原始观察到的图像显着偏离。相反,我们发现通过在训练期间提供每个视频的第一帧作为显式调节上下文,来显式训练受限视频合成模型更为有效。
通过平铺实现轨迹一致性
现有的文本到视频模型通常会生成视频,其中基础环境状态在持续时间内发生显着变化。为了构建准确的轨迹规划器,重要的是环境在所有时间点保持一致。为了增强条件视频合成中的环境一致性,我们在对合成视频中的每个帧进行去噪时提供观察到的图像作为附加上下文。特别是,我们重新设计了时间超分辨率视频扩散架构,并提供跨时间平铺的条件视觉观察作为上下文,而不是在每个时间步进行去噪的低时间分辨率视频。在这个模型中,我们直接将每个中间噪声帧与跨采样步骤的条件观察图像连接起来,作为跨时间维持底层环境状态的强信号。
分层规划
当在长时间范围的高维环境中构建计划时,由于底层搜索空间的指数爆炸,直接生成一组动作以快速达到目标状态变得很棘手。规划方法通常通过利用规划中的自然层次结构来规避这个问题。具体来说,规划方法首先构建在低维状态和动作上运行的粗略计划,然后可以将其细化为底层状态和动作空间中的计划。与规划类似,我们的条件视频生成过程同样表现出自然的时间层次结构。我们首先通过沿着时间轴对我们期望的行为进行稀疏采样的视频(“抽象”)来生成粗略的视频。然后,我们通过跨时间的超分辨率视频来细化视频以代表环境中的有效行为。同时,从粗到细的超分辨率通过帧之间的插值进一步提高了一致性。
灵活的行为调节
Task Specific Action Adaptation
给定一组合成视频,我们可以训练一个小型特定于任务的逆动力学模型,将帧转换为一组动作,如下所述。
逆动力学
我们训练一个小模型来估计给定输入图像的动作。逆动力学的训练独立于规划器,并且可以在模拟器生成的单独的、较小的且可能不是最优的数据集上完成。
动作执行
通过合成H个图像帧来预测出了H个动作,然后按照H个动作依次执行。
实验评估
这些实验的重点是评估 UniPi 实现有效、通用决策的能力。我们特别评估:
1、组合概括第 4.1 节中不同子目标的能力;
2、有效学习和概括第 4.2 节中许多任务的能力;
3、利用互联网上的现有视频来推广第 4.3 节中的复杂任务的能力。
组合策略合成
首先,我们测量 UniPi 组合泛化到不同语言任务的能力。
设置
为了测量组合泛化,我们使用组合机器人规划任务。在此任务中,机器人必须根据语言指令操纵环境中的块,即将红色块放在青色块的右侧。为了完成这项任务,机器人必须首先拿起一个白色块,将其放入适当的碗中,将其涂上特定的颜色,然后拿起该块并将其放入盘子中,使其满足指定的关系。与使用预编程的拾取和放置基元进行动作预测的(Mao 等人,2022)相比,我们针对基线和我们的方法预测连续机器人关节空间中的动作。
我们将此环境中的语言指令分为两组:一组指令 (70%) 在训练期间看到,另一组指令 (30%) 仅在测试期间看到。环境中各个块、碗和盘子的精确位置在每次环境迭代中都是完全随机的。我们在训练集中生成的语言指令的 20 万个示例视频上训练视频模型。
实验结果
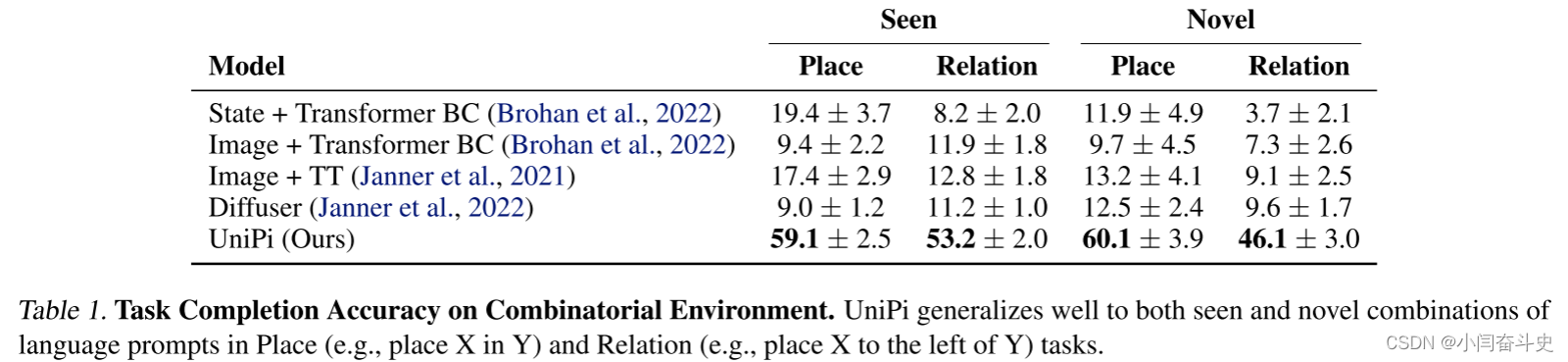
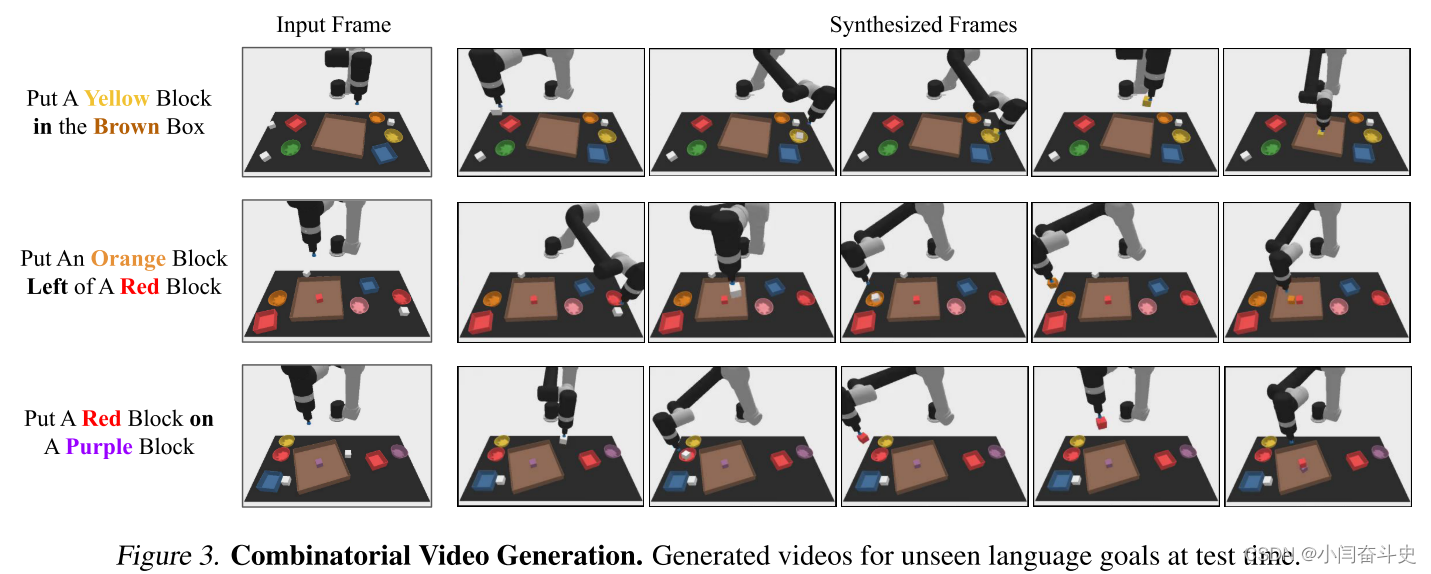
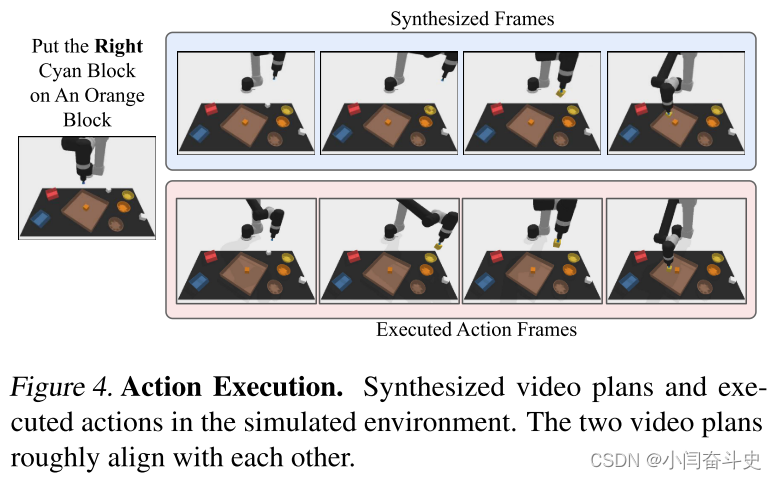
组合泛化。在表 1 中,我们发现 UniPi 可以很好地推广到见过的和新颖的语言提示组合。我们在图 4 中说明了我们的动作生成pipeline,并使用图 3 中的方法生成了不同的视频计划。
在表 2 中,我们根据已知的语言指令和与任务相关的内容来消除 UniPi。具体来说,我们研究了在第一个观察帧(帧条件)上调节视频生成模型的效果,跨时间步长平铺观察帧(帧一致性)以及跨时间超分辨率视频生成(时间层次结构)。 UniPi 的所有组件对于良好的性能都至关重要。在不强制执行帧一致性的设置中,我们提供归零图像作为视频中非起始帧的上下文。

适应性。接下来我们评估 UniPi 在测试时适应新约束的能力。在图 5 中,我们展示了构建计划的能力,该计划将一个特定块着色并将其移动到指定的几何关系。
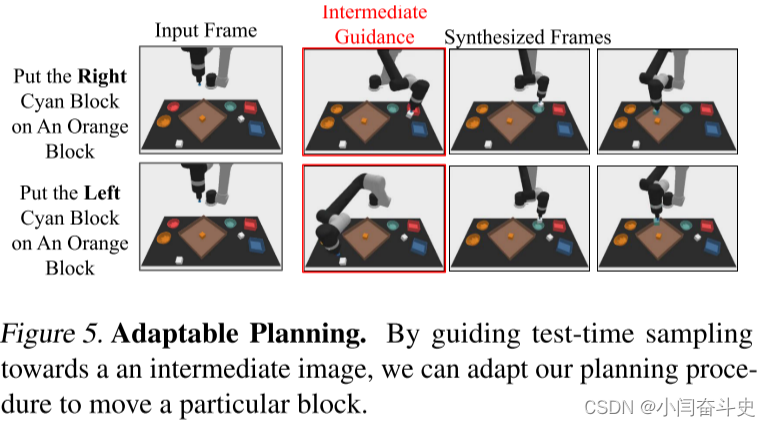
Multi-Environment Transfer多环境传输
接下来,我们评估 UniPi 有效学习一组不同任务的能力,并在测试时泛化到一组新的未见过的环境。
设置
为了衡量多任务学习和迁移,我们使用了(Shridhar et al., 2022)中的一套语言引导操作任务。我们使用来自(Shridhar et al., 2022)的一组 10 个独立任务的演示来训练我们的方法,并评估我们的方法转移到 3 个不同测试任务的能力。使用脚本化的预言机代理,我们生成了一组 20 万个环境中语言执行的视频。我们报告完成每项语言指令的基本准确性。
实验结果

在表 3 中,我们展示了我们的方法的结果和新任务的基线。我们的方法能够概括和综合新的视频和不同语言任务的决策,并且可以生成由挑选不同种类的物体和不同颜色的物体组成的视频。我们在图 6 中进一步展示了我们方法的视频可视化。
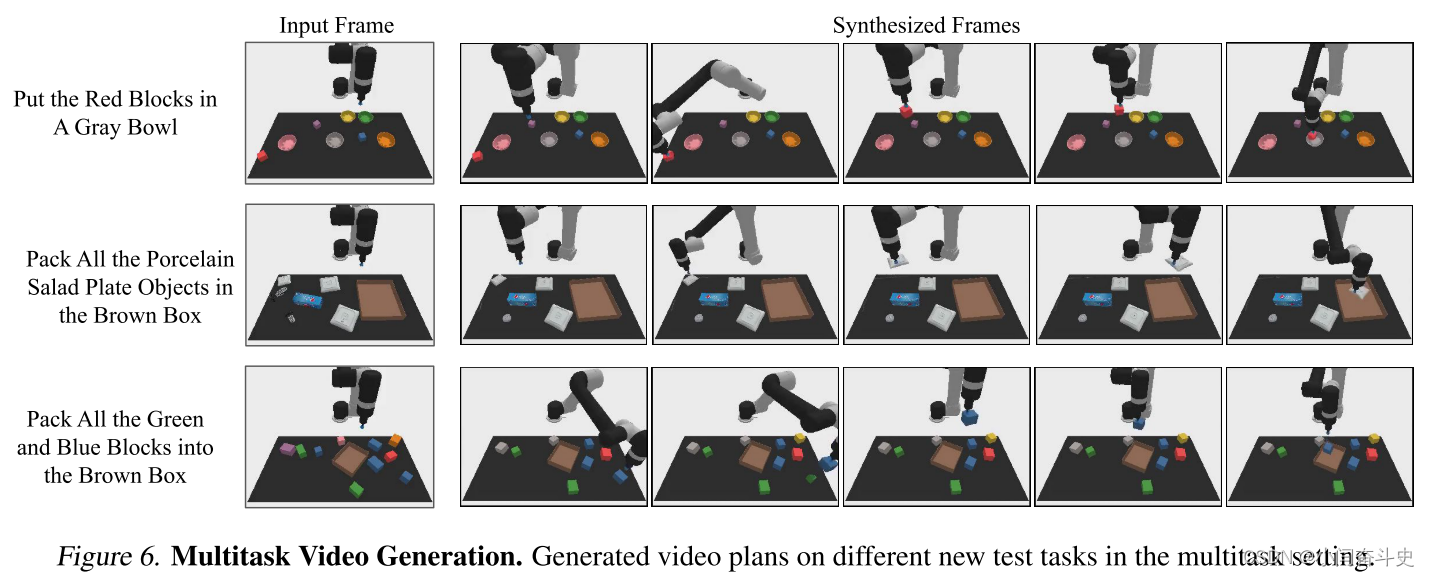
Real World Transfer真实世界转移
最后,我们评估 UniPi 能够在多大程度上推广到现实世界场景并利用互联网上广泛提供的视频构建复杂的行为。
设置
我们的训练数据由互联网规模的预训练数据集和较小的现实世界机器人数据集组成。预训练数据集使用与(Ho et al., 2022a)相同的数据,其中包含 1400 万个视频文本对、6000 万个图像文本对以及公开的 LAION-400M 图文数据集。机器人数据集采用了 Bridge 数据集(Ebert et al., 2021),具有 7.2k 视频文本对,其中我们使用任务 ID 作为文本。我们将 7.2k 个视频文本对划分为训练组 (80%) 和测试组 (20%)。我们在预训练数据集上对 UniPi 进行预训练,然后对 Bridge 数据进行微调。
视频合成
我们特别感兴趣的是预训练对非机器人特定的互联网规模视频数据的影响。我们报告了在 Bridge 数据上训练的 UniPi 的 CLIP 分数、FID 和 VID(跨帧平均并根据 32 个样本计算),无论是否经过预训练。如表 4 所示,与未进行预训练的 UniPi 相比,经过预训练的 UniPi 实现了显着更高的 FID 和 FVD,并且 CLIP 分数略好,这表明对非机器人数据进行预训练有助于生成机器人计划。有趣的是,没有预训练的 UniPi 通常会合成无法完成任务的计划(图 7),这在 CLIP 分数中没有得到很好的体现,这表明需要更好的生成指标来用于特定于控制的任务。


泛化性
我们发现,互联网规模的预训练使 UniPi 能够泛化到训练期间未见过的测试分割中的新任务命令和场景,而仅在特定于任务的机器人数据上训练的 UniPi 无法泛化。具体来说,图 8 显示了 Bridge 数据集中不存在的新颖任务命令的泛化结果。此外,UniPi 对于背景变化(例如黑色裁剪或添加经过修图的对象)相对稳健,如图 9 所示。


总结
我们已经展示了使用文本条件视频生成来表示策略的实用性,表明这可以实现有效的组合泛化、多任务学习和现实世界的迁移。这些积极的结果指出了使用生成模型和互联网上丰富的数据作为生成通用决策系统的强大工具的更广泛方向。
这篇关于论文阅读:《Learning Universal Policies via Text-Guided Video Generation》的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









