本文主要是介绍数据中心的黑科技——到底什么是NPO/CPO?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
大家好,我是小枣君。
今天这篇文章,我们来聊聊数据中心的两项最新黑科技—NPO/CPO。

故事还是要从头开始讲起。
去年,国家发布了“东数西算”战略,吸引了全社会的关注。
所谓“东数西算”,其实就是数据中心的任务分工调整。我们将东部沿海地区的部分算力需求,转移到西部地区的数据中心完成。
之所以这么做,就是因为西部地区能源资源比较充沛,而且自然温度较低,可以大幅减少电费以及碳排放。
我们都知道,数据中心是算力的载体,现阶段我们大搞数字化转型和数字经济,离不开算力,也离不开数据中心。但是,数据中心的耗电问题,无法忽视。
根据数据显示,2021年全国数据中心总用电量为2166亿千瓦时,占全国总用电量的2.6%,相当于2个三峡水电站的年发电量,1.8个北京地区的总用电量。
如此恐怖的耗电量,对我们实现“双碳”目标造成了很大压力。
于是乎,行业开始加紧研究,究竟如何才能将数据中心的能耗降下来。

数据中心(IDC)
大家应该都知道,数据中心有一个重要的参数指标,那就是PUE(Power Usage Effectiveness,电能使用效率)。
PUE=数据中心总能耗/IT设备能耗。其中数据中心总能耗,包括IT设备能耗,以及制冷、配电等其它系统的能耗。
我们可以看出,除了用在主设备上的电量之外,还有很大一部分能耗,用在散热和照明上。
所以,捣鼓数据中心的节能减排,思路就在两点:
1、减少主设备的功耗
2、减少散热和照明方面的功耗(主要是散热)
█ 主设备的功耗挑战
说起主设备,大家马上就想到了服务器。是的没错,服务器是数据中心最主要的设备,它上面承载了各种业务服务,有CPU、内存等硬件,可以输出算力。
但实际上,主设备还包括一类重要的设备,那就是网络设备,也就是交换机、路由器、防火墙等。
目前,AI/ML(人工智能/机器学习)的加速落地,再加上物联网的高速发展,使得数据中心的业务压力越来越大。
这个压力不仅体现在算力需求上,也体现在网络流量上。数据中心的网络接入带宽标准,从过去的10G、40G,一路提升到现在100G、200G甚至400G。
网络设备为了满足流量增长的需求,自身也就需要不断迭代升级。于是乎,更强劲的交换芯片,还有更高速率的光模块,统统开始用上。
我们先看看交换芯片。
交换芯片是网络设备的心脏,它的处理能力直接决定了设备的能力。这些年,交换芯片的功耗水涨船高,如下图所示:
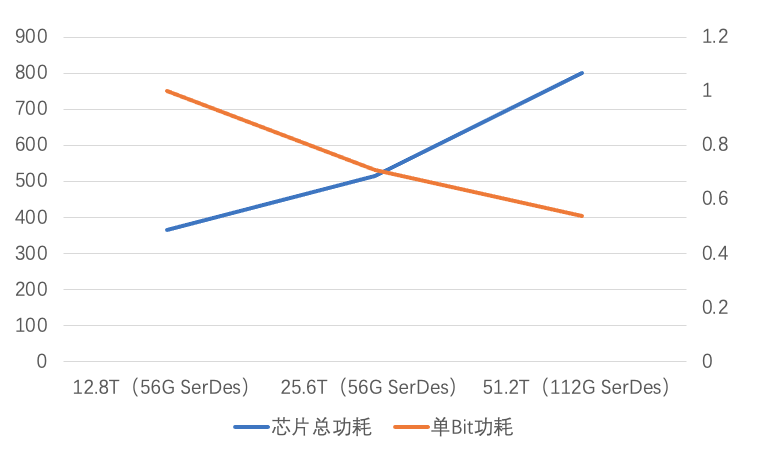
交换机芯片功耗变化趋势
值得一提的是,虽然网络设备的总体功耗在持续提升,但是,单Bit(比特)的功耗是持续降低的。也就是说,能效越来越高。
再看光模块。
光模块在光通信领域,拥有重要的地位,直接决定了网络通信的带宽。
早在2007年的时候,一个万兆(10Gbps)的光模块,功率才1W左右。
随着40G、100G到现在的400G,800G甚至以后的1.6T光模块,功耗提升速度就像坐上了火箭,一路飙升,直逼30W。大家可要知道,一个交换机可不止一个光模块,满载的话,往往就有几十个光模块(假如48个,就是48×30=1440 W)。
一般来说,光模块的功耗大约占整机功耗的40%以上。这就意味着,整机的功耗极大可能会超过3000 W。
一个数据中心,又不止一交换机。这背后的功耗,想想都很可怕。
除了交换芯片和光模块之外,网络设备还有一个大家可能不太熟悉的“耗电大户”,那就是——SerDes。
SerDes是英文SERializer(串行器)/DESerializer(解串器)的简称。在网络设备中,它是一个重要器件,主要负责连接光模块和网络交换芯片。
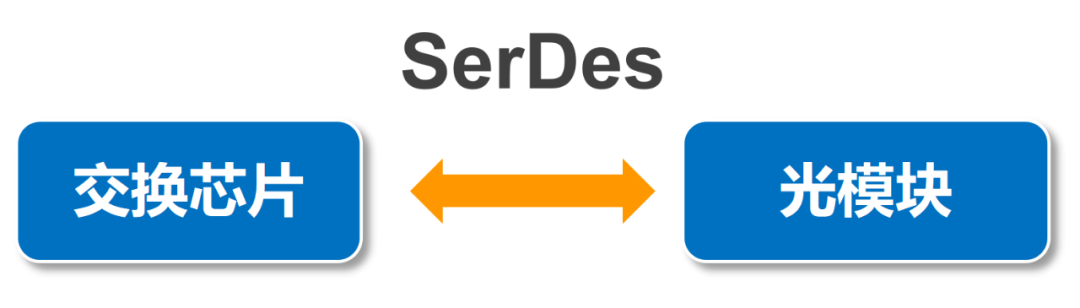
简单来说,就是将交换芯片出来的并行数据,转换成串行数据进行传输。然后,在接收端,又将串行数据转换成并行数据。
前面提到,网络交换芯片的能力在不断提升。因此,SerDes的速率也必须随之提升,以便满足数据传输的要求。
SerDes的速率提升,自然就带动了功耗的增加。
在102.4Tbps时代,SerDes速率需要达到224G,芯片SerDes(ASIC SerDes)功耗预计会达到300W。
需要注意的是,SerDes的速率和传输距离,会受到PCB材料工艺的影响,并不能无限增加。换句话说,当SerDes速率增加、功耗增加时,PCB铜箔能力不足,不能让信号传播得更远。只有缩短传输距离,才能保证传输效果。
这有点像扔铅球比赛,当铅球越重(SerDes速率越高),你能扔的距离就越短。
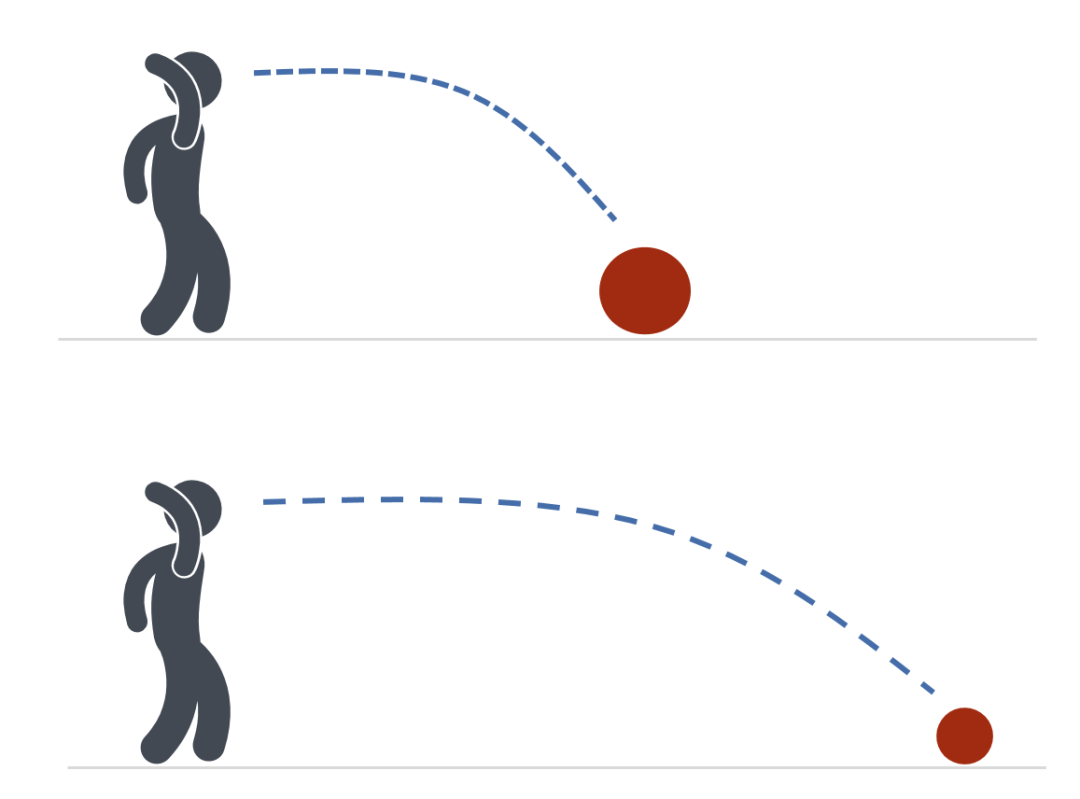
具体来说,SerDes速率达到224G时,最多只能支持5~6英寸的传输距离。
这意味着,在SerDes没有技术突破的前提下,网络交换芯片和光模块之间的距离,必须缩短。
综上所述,交换芯片、光模块、SerDes,是网络设备的三座“功耗”大山。
根据设备厂商的数据显示,过去的12年时间,数据中心的网络交换带宽提升了80倍,背后的代价就是:交换芯片功耗提升约8倍,光模块功耗提升26倍,交换芯片SerDes功耗提升25倍。
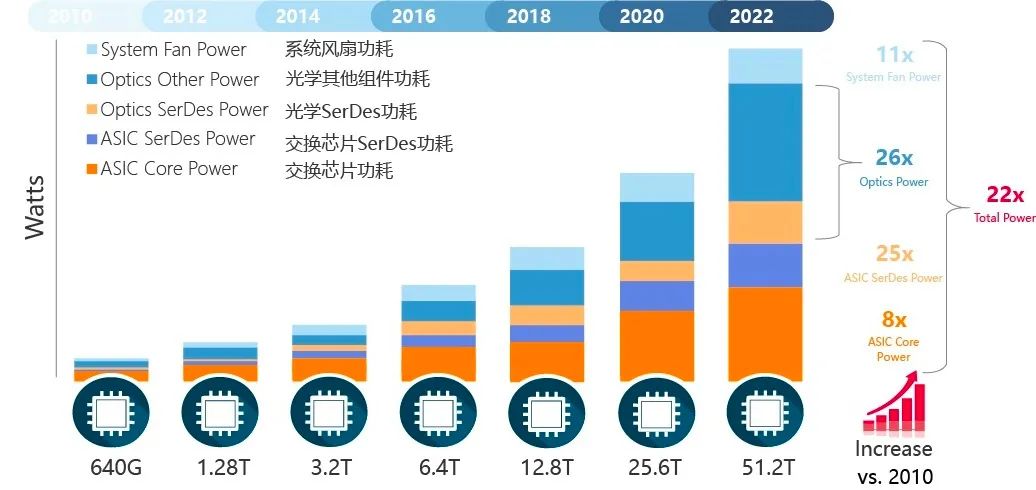
信息来源:2020 Cisco and/or its affiliates.All rights reserved.Cisco Public
在此情况下,网络设备在数据中心内的功耗占比,随之不断攀升。
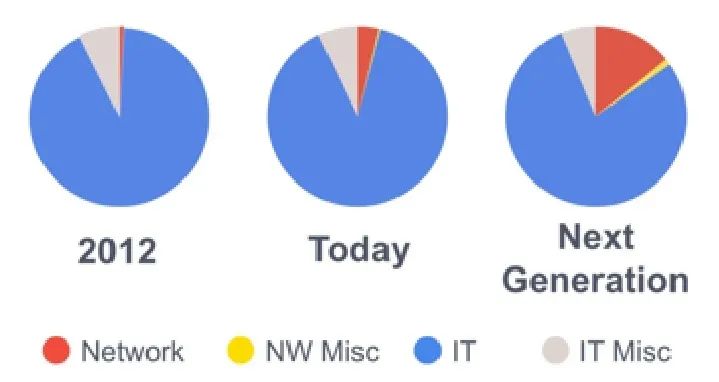
网络设备(红色)的能耗占比
数据来源:Facebook-OIF CPO Webinar 2020
█ 散热的功耗挑战
前面小枣君仔细介绍了网络设备的功耗挑战。接下来,我们再看看散热。
事实上,相比对网络设备的功耗提升,散热的功耗才是真正的大头。
根据数据统计,交换设备在典型数据中心总能耗中的占比,仅仅只有4%左右,还不到服务器的1/10。
但是散热呢?根据CCID数据统计,2019年中国数据中心能耗中,约有43%是用于IT设备的散热,基本与45%的IT设备自身的能耗持平。
即便是现在国家对PUE提出了严格要求,按照三级能效(PUE=1.5,数据中心的限定值)来算,散热也占了将近40%。
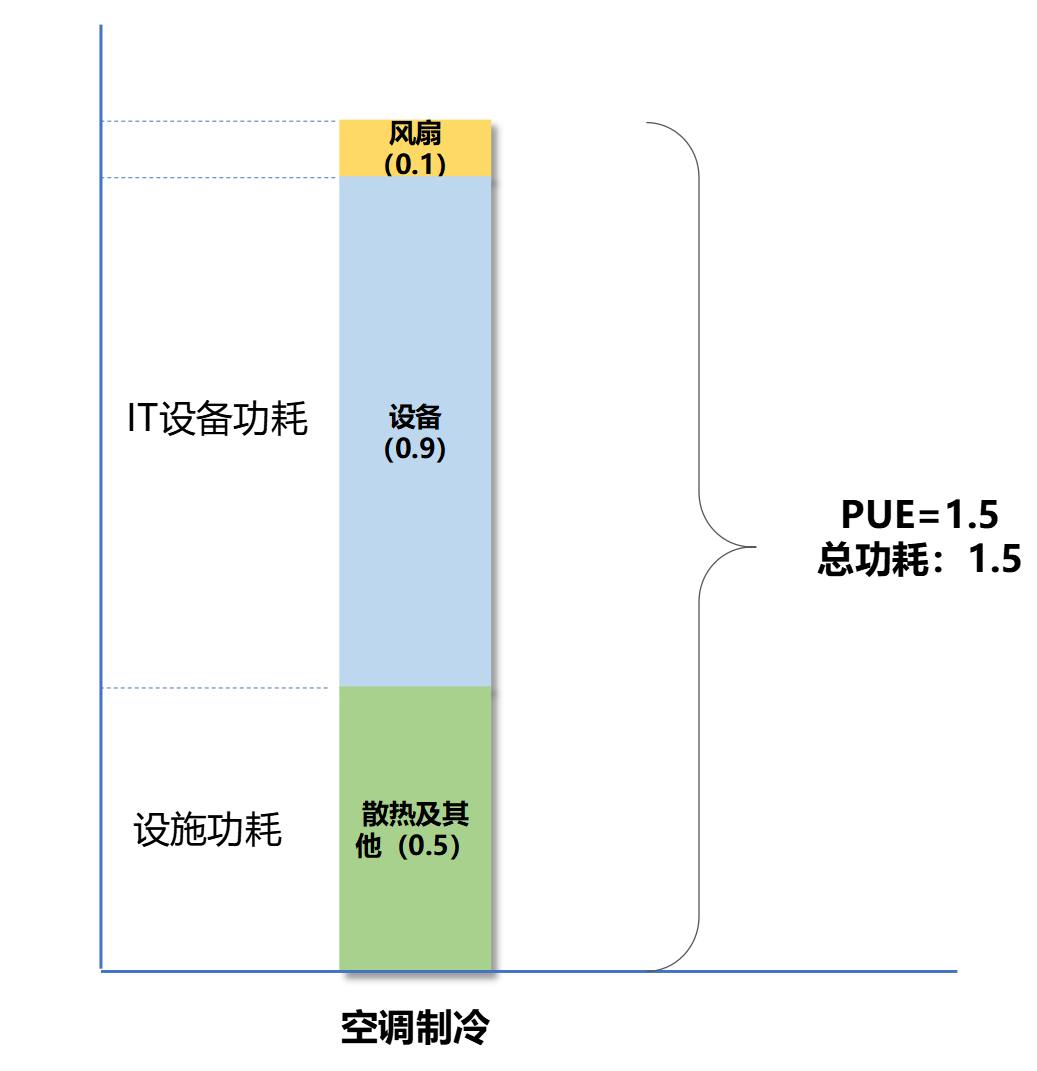
传统的散热方式(风冷/空调制冷),已经不能满足当前高密数据中心的业务发展需求。于是,我们引入了液冷技术。
液冷,是使用液体作为冷媒,为发热部件散热的一种新技术。引入液冷,可以降低数据中心能近90%的散热能耗。数据中心整体能耗,则可下降近36%。
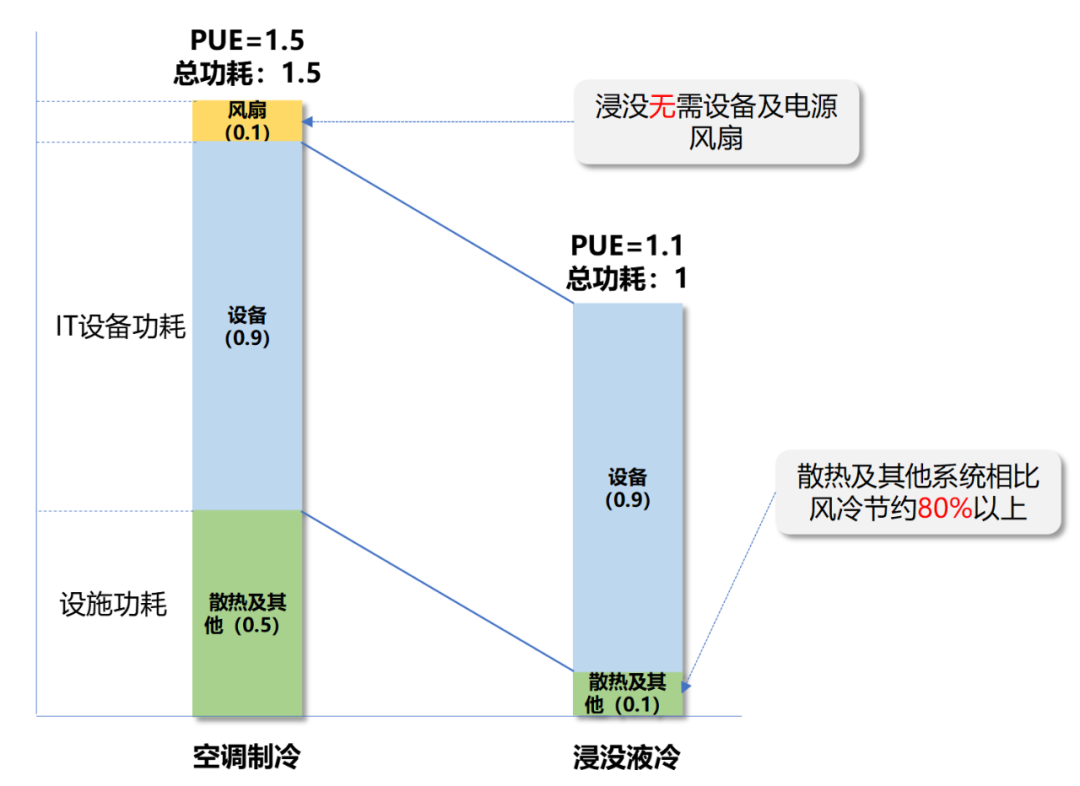
这个节能效果,可以说是非常给力了,直接省电三分之一。
除了散热更强更省电之外,液冷在噪音、选址(不受环境气候影响)、建设成本(可以让机柜采用高密度布局,减少机房占地面积)等方面也有显著优势。
所以,现在几乎所有的数据中心,都在采用液冷。有的液冷数据中心,甚至可以将PUE干到1.1左右,接近1的极限值。
液冷,是不是把整个设备全部浸没在液体里呢?
不一定。
液冷的方案,一般包括两种,分别是浸没式和冷板式。
浸没式,也叫直接式,是将主设备里发热量大的元器件,全部浸入冷却液中,进行散热。
冷板式,也称间接式,是将主要散热部件与一块金属板贴合,然后金属板里有冷媒液体流动,把热量带走。现在很多DIY组装电脑,就是冷板式。
服务器采用液冷,已经是非常成熟的技术。那么,既然要上液冷,当然是服务器和网络设备一起上,会更好啊,不然还要搞两套体系。
问题来了,咱们的网络设备,能上液冷吗?
█ NPO/CPO,闪亮登场
当当当!铺垫了那么多,我们的主角,终于要闪亮登场了。
为了尽可能地降低网络设备的自身工作功耗以及散热功耗,在OIF(光互联网络论坛)的主导下,业界多家厂商,共同推出了——NPO/CPO技术。
2021年11月,国内设备厂商锐捷网络(Ruijie Networks),发布了全球第一款25.6T的NPO冷板式液冷交换机。2022年3月,他们又发布了51.2T的 NPO冷板式液冷交换机(概念机)。

NPO冷板式液冷交换机
NPO,英文全称Near packaged optics,近封装光学。CPO,英文全称Co-packaged optics,共封装光学。
简单来说,NPO/CPO是将网络交换芯片和光引擎(光模块)进行“封装”的技术。
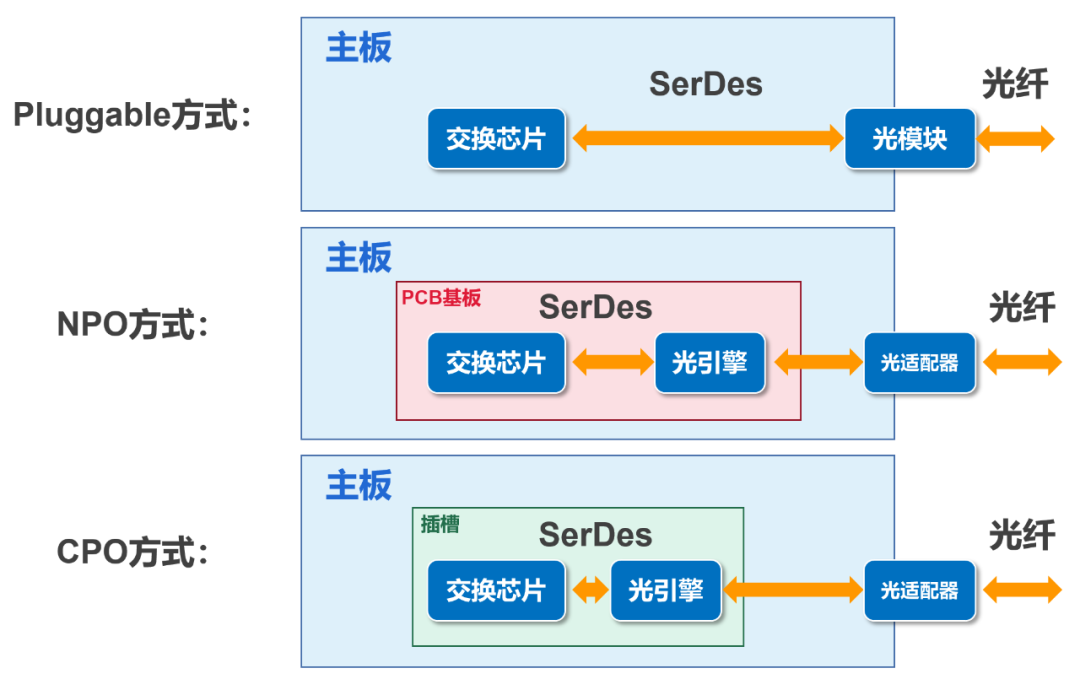
我们传统的连接方式,叫做Pluggable(可插拔)。光引擎是可插拔的光模块。光纤过来以后,插在光模块上,然后通过SerDes通道,送到网络交换芯片(AISC)。
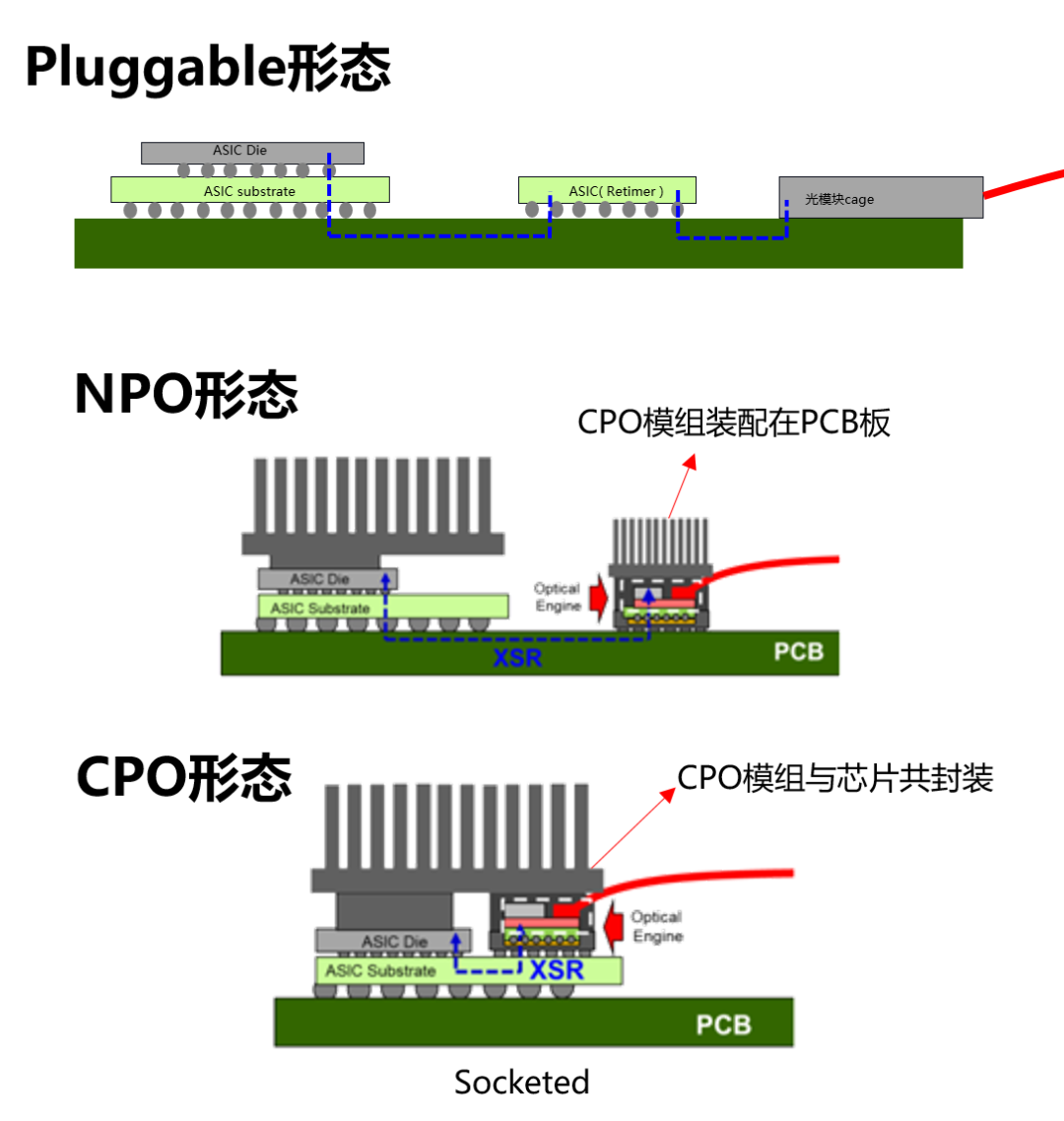
CPO呢,是将交换芯片和光引擎共同装配在同一个Socketed(插槽)上,形成芯片和模组的共封装。
NPO是将光引擎与交换芯片分开,装配在同一块PCB基板上。
大家应该能看出来,CPO是终极形态,NPO是过渡阶段。NPO更容易实现,也更具开放性。
之所以要做集成(“封装”),目的很明确,就是为了缩短了交换芯片和光引擎间的距离(控制在5~7cm),使得高速电信号能够高质量的在两者之间传输,满足系统的误码率(BER)要求。
缩短距离,保证高速信号的高质量传输
集成后,还可以实现更高密度的高速端口,提升整机的带宽密度。
此外,集成使得元件更加集中,也有利于引入冷板液冷。

NPO交换机内部(揭开冷板后)
可以看到,交换芯片和光引擎之间的距离大幅缩短
NPO/CPO技术的背后,其实就是现在非常热门的硅光技术。
硅光,是以光子和电子为信息载体的硅基光电子大规模集成技术。简单来说,就是把多种光器件集成在一个硅基衬底上,变成集成“光”路。它是一种微型光学系统。
硅光之所以这么火,根本原因在于微电子技术已经逐渐接近性能极限,传统的“电芯片”在带宽、功耗、时延方面,越来越力不从心,所以,就改走了“(硅)光芯片”这个新赛道。
█ NPO/CPO交换机的进展
NPO/CPO技术是目前各大厂商研究的热门方向。尤其是NPO,因为拥有最优开放生态,产业链更加成熟,可以获得成本及功耗的最快收益,所以,发展落地更快。
前面提到了锐捷网络的25.6T硅光NPO冷板式液冷交换机。
这款NPO交换机基于112G SerDes的25.6T的交换芯片,1RU的高度,前面板支持64个连接器的400G光接口,由16个1.6T(4×400G DR4)的NPO模块组成,支持8个ELS/RLS(外置激光源模块)。
散热方面,采用了非导电冷却剂的冷板冷却方式。
那款51.2T硅光NPO冷板式液冷交换机,高度不变,将NPO模组从1.6T升级到了3.2T,前面板支持64个800G连接器,每个连接器还可以分成2个400G端口,实现向前兼容。外置光源模块增加到了16个。

51.2T NPO冷板式液冷交换机
在实际组网中,51.2T的NPO交换机(最快在2023年底商用发布),可以应用于100G/200G的接入网络,作为接入&汇聚设备,实现高速互联。
值得一提的是,NPO/CPO的技术和产品研发,并不是一件简单的事情,背后是对一家企业整体研发实力的考验。
这次锐捷网络能够全球首发NPO/CPO产品,是他们持续投入资源进行艰苦研发和创新的成果,也体现了他们在这个领域的技术领先性。
锐捷网络在2019年开始关注硅光领域技术,2020年6月正式成立研发及产品团队。作为OIF/COBO的成员,他们一直都有参与工作组全球会议,参加相关标准的讨论和制定。

OIF工作组全球会议现场
在硅光这个方向上,锐捷网络已经走在了世界前列,未来可期。
█ 结语
好了,介绍了这么多,相信大家已经看明白,到底什么是NPO/CPO了。
这两项技术,是数据中心网络设备毫无疑问的发展方向。在目前的数字化浪潮下,我们对算力和网络通信能力的追求是无止境的。在追求性能的同时,我们也要努力平衡功耗。毕竟,我们要走的是可持续性发展的道路。
希望以NPO/CPO为代表的硅光科技,能够进一步加速落地,为信息基础设施的绿色低碳做出贡献。
未来,硅光技术究竟还会带来怎样的技术创新?让我们拭目以待吧!
——全文完——

这篇关于数据中心的黑科技——到底什么是NPO/CPO?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!