本文主要是介绍【C语言】P166 10.有一篇文章,共有3行文字,每行有80个字符。要求分别统计出其中英文大写字母、小写字母、数字、空格以及其他字符的个数,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
P166 10.有一篇文章,共有3行文字,每行有80个字符。要求分别
统计出其中英文大写字母、小写字母、数字、空格以及其他字符的个数
#include<stdio.h>int main() {char text[3][80];int i, j, upp, low, dig, spa, oth;upp = low = dig = spa = oth = 0;//获取每一行的内容for (i = 0; i < 3; i++) {printf("请输入第%d行的内容:", i + 1);gets(text[i]);//统计内容 注意:text[i][j]!='\0',不计算数组中无内容的位置for (j = 0; j < 80 && text[i][j] != '\0'; j++) {//统计大写字母if (text[i][j] >= 'A' && text[i][j] <= 'Z') {upp++;}//统计小写字母else if (text[i][j] >= 'a' && text[i][j] <= 'z') {low++;}//统计数字else if (text[i][j] >= '0' && text[i][j] <= '9') {dig++;}//统计空格else if (text[i][j] == ' ') {spa++;}//其他字符else {oth++;}}}printf("\n大写字母的个数为:%d", upp);printf("\n小写字母的个数为:%d", low);printf("\n数字的个数为:%d", dig);printf("\n空格的个数为:%d", spa);printf("\n其他字符的个数为:%d", oth);return 0;
}运行结果:
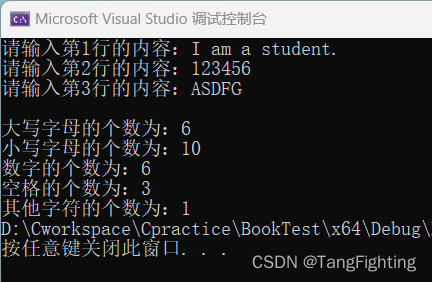
这篇关于【C语言】P166 10.有一篇文章,共有3行文字,每行有80个字符。要求分别统计出其中英文大写字母、小写字母、数字、空格以及其他字符的个数的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




