本文主要是介绍四十七、Redis分片集群,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一、分片集群结构
二、散列插槽
1、Redis如何判断某个key应该在哪个实例?
2、如何将同一类数据固定的保存在同一个Redis实例?
三、集群伸缩
四、故障转移
1、当集群中有一个master宕机时
(1)自动转移
(2)手动转移
五、RedisTemplate访问分片集群
一、分片集群结构
主从和哨兵可以解决高可用、高并发读的问题。但是依然有两个问题没有解决:
• 海量数据存储问题• 高并发写的问题
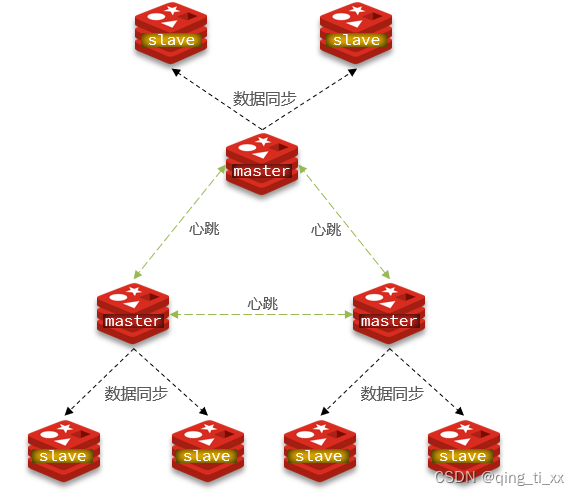
使用分片集群可以解决上述问题,分片集群特征:
• 集群中有多个 master ,每个 master 保存不同数据• 每个 master 都可以有多个 slave 节点• master 之间通过 ping 监测彼此健康状态• 客户端请求可以访问集群任意节点,最终都会被转发到正确节点
二、散列插槽
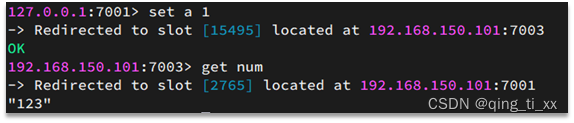
Redis会把每一个master节点映射到0~16383共16384个插槽(hash slot)上,查看集群信息时就能看到:(每个节点分配一部分插槽)

数据key不是与节点绑定,而是与插槽绑定。redis会根据key的有效部分计算插槽值,分两种情况:
• key 中包含 "{}" ,且“ {} ”中至少包含 1 个字符,“ {} ”中的部分是有效部分• key 中不包含“ {} ”,整个 key 都是有效部分
例如:key是num,那么就根据num计算,如果是{itcast}num,则根据itcast计算。计算方式是利用CRC16算法得到一个hash值,然后对16384取余,得到的结果就是slot值。
1、Redis如何判断某个key应该在哪个实例?
• 将 16384 个插槽分配到不同的实例• 根据 key 的有效部分计算哈希值,对 16384 取余• 余数作为插槽,寻找插槽所在实例即可
2、如何将同一类数据固定的保存在同一个Redis实例?
• 这一类数据使用相同的有效部分,例如 key 都以 { typeId } 为前缀
三、集群伸缩
集群命令
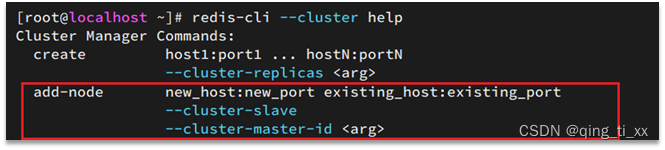
可以创建新的master节点和slave节点
四、故障转移
1、当集群中有一个master宕机时
(1)自动转移
- 首先是该实例与其它实例失去连接
- 然后是疑似宕机
- 最后是确定下线,自动提升一个slave为新的master
(2)手动转移
输入命令即可
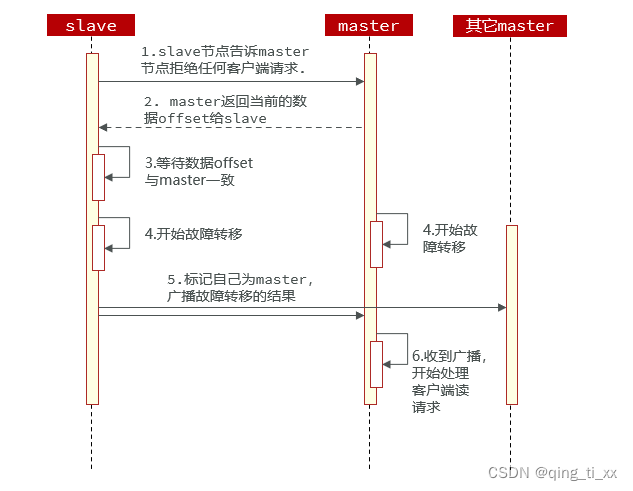
手动的Failover支持三种不同模式:
• 缺省:默认的流程,如图 1~6步
• force :省略了对 offset 的一致性校验
• takeover :直接执行第5步,忽略数据一致性、忽略master 状态和其它 master 的意见
五、RedisTemplate访问分片集群
RedisTemplate底层同样基于lettuce实现了分片集群的支持,而使用的步骤与哨兵模式基本一致:
1. 引入 redis 的 starter 依赖
2. 配置分片集群地址
3. 配置读写分离
与哨兵模式相比,其中只有分片集群的配置方式略有差异,如下:
spring:redis:cluster:nodes: # 指定分片集群的每一个节点信息- 192.168.150.101:7001- 192.168.150.101:7002- 192.168.150.101:7003- 192.168.150.101:8001- 192.168.150.101:8002- 192.168.150.101:8003
这篇关于四十七、Redis分片集群的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





