本文主要是介绍Hazel引擎学习(十二),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
我自己维护引擎的github地址在这里,里面加了不少注释,有需要的可以看看
参考视频链接在这里
这是这个系列的最后一篇文章,Cherno也基本停止了Games Engine视频的更新,感觉也差不多了,后续可以基于此项目开发自己想要的引擎功能了
Scene类重构
参考:《InsideUE4》GamePlay架构(二)Level和World
目前我的Scene类基本只是给entt的封装,提供了一些GameObject和Component的相关函数,其Update函数没有被调用,相关API也很缺乏,大概是这样:
namespace Hazel
{class GameObject;class Scene{public:Scene();~Scene();void Update();void OnViewportResized(uint32_t width, uint32_t height);GameObject& CreateGameObjectInScene(const std::shared_ptr<Scene>& ps, const std::string& name = "Default Name");...}
}
现在的窗口其实只有Viewport,没有GameView窗口。为了完善Scene的相关功能,可以先来看看别的游戏引擎里的设计,Unity里会有SceneView和GameView两个窗口,一个负责绘制场景,一个负责代表GamePlay的实际窗口,而UE里的Viewport和GameView则共用一个窗口,按F8 eject可以切换SceneView和GameView
游戏引擎里允许同时加载多个场景(Scene),那么逻辑上讲,需要三个内容:
- Scene Manager:应该是作为全局单例存在,负责加载和卸载场景
- 场景文件,作为文本文件(或可以被解析的二进制文件)存放了场景信息
- 程序加载时的Scene,每个Scene由序列化好的场景文件实例化而来
对应到各个引擎里,有不同的叫法,UE里把World认作Scene Manager、场景文件叫xxxx.map,Level就是实例化的Scene;而Unity早期用Application代表Scene Manager(后面改到了Scene Manager里),场景文件叫xxxx.unity,Scene就是实例化的Scene。
比如UE里的代码:
// UWorld里存了Level数组
class ENGINE_API UWorld final : public UObject, public FNetworkNotify
{/** Array of levels currently in this world. Not serialized to disk to avoid hard references. */UPROPERTY(Transient)TArray<TObjectPtr<class ULevel>> Levels;/** Level collection. ULevels are referenced by FName (Package name) to avoid serialized references. Also contains offsets in world units */UPROPERTY(Transient)TArray<TObjectPtr<ULevelStreaming>> StreamingLevels;...
}// ULevel里存了Actor数组
UCLASS(MinimalAPI)
class ULevel : public UObject, public IInterface_AssetUserData, public ITextureStreamingContainer
{...// Level里的Actor和待GC的Actor数组TArray<AActor*> Actors;TArray<AActor*> ActorsForGC;// 唯一的LevelScriptActor指针UPROPERTY(NonTransactional)TObjectPtr<class ALevelScriptActor> LevelScriptActor;
}
大概逻辑是,Update这些Level(或Scene),从而Tick里面的Actor和ActorComponent。所以这里把Scene类重构成如下所示:
namespace Hazel
{class GameObject;class Scene{public:Scene();~Scene();void Begin();void Pause();void Stop();void Update(const float& deltaTime);void Clear();void OnViewportResized(uint32_t width, uint32_t height);void ClearAllGameObjectsInScene();...}
}
PS:这里我并没有像Cherno一样区分了RuntimeUpdate和EditorUpdate,因为感觉别的游戏引擎里都没这么区分,而且Editor下应该也调用Update函数才对
2D PHYSICS!
主要是实现简单的物理引擎,做了以下事情:
- Fork GitHub上的比较有名的2D物理引擎(erincatto/box2d),作为submodule加入到引擎里
- 创建2D用的Rigidbody组件,目前只支持Box
- Scene类里添加一个box2d的manager对象的指针:具体的Rigidbody分为Static和Dynamic类型(还有Kinematic?)
- Render模块、物理模块与脚本模块的顺序问题
关于Box2D
参考:Box2D —— A 2D physics engine for games
From the game engine’s point of view, a physics engine is just a system for procedural animation.
这是个C++写的库,还挺牛的,Unity和Cocos都用到了它,为了避免与其他的库命名冲突,里面的类型名都以b2作为前缀,这里举个简单的Demo代码:
// 1. 创建世界, b2World is the physics hub that manages memory, objects, and simulation.
b2Vec2 gravity(0.0f, -10.0f);
b2World world(gravity);// 创建世界时需要设置重力加速度// 2. 创建一个长方形代表地面, 默认为static类型
b2BodyDef groundBodyDef;// 先创建引用
groundBodyDef.position.Set(0.0f, -10.0f);
b2Body* groundBody = world.CreateBody(&groundBodyDef);// 再创建实体// 给地面添加Box Collider, 这里的0.0f指的是?
b2PolygonShape groundBox;
groundBox.SetAsBox(50.0f, 10.0f);
groundBody->CreateFixture(&groundBox, 0.0f);// 3. 创建一个dynamic类型的rigidbody
b2BodyDef bodyDef;
bodyDef.type = b2_dynamicBody;
bodyDef.position.Set(0.0f, 4.0f);
b2Body* body = world.CreateBody(&bodyDef);// 添加Box Collider, 添加一些物理参数
b2PolygonShape dynamicBox;
dynamicBox.SetAsBox(1.0f, 1.0f);b2FixtureDef fixtureDef;
fixtureDef.shape = &dynamicBox;
fixtureDef.density = 1.0f;
fixtureDef.friction = 0.3f;
body->CreateFixture(&fixtureDef);// 5. 开启世界的更新, 根据前面的设置, 世界开始后动态box会坠落到静态的地面上, 不断bounce
for (int32 i = 0; i < 60; ++i)
{// 调用物理世界的更新world.Step(timeStep, velocityIterations, positionIterations);// 打印更新后的Transformb2Vec2 position = body->GetPosition();float angle = body->GetAngle();printf("%4.2f %4.2f %4.2f\n", position.x, position.y, angle);
}// 6. Clean up
// world离开作用域时, 会自动释放相关的所有memory
顺便提一下,这里面有个概念叫fixture,具体有shape、restitution、friction和density四个主要属性,并不是固定装置的意思,而是类似于Unity里的Collider的概念。另外注意一点,这里需要先填写好BodyRef,再调用CreateBody,代码如下所示:
// 注意, 调用CreateBody之前要把b2BodyDef里的参数都填好// 正确写法
m_BodyDef.position.Set(x, y);
m_BodyDef.type = Rigidbody2DTypeToB2BodyType(type);
m_Body = world->CreateBody(&m_BodyDef);// 错误写法
m_BodyDef.position.Set(x, y);
m_Body = world->CreateBody(&m_BodyDef);
m_BodyDef.type = Rigidbody2DTypeToB2BodyType(type);
这里做的事情主要是封装,比较简单:
- 创建Rigidbody2DComponent类
- 对应类对象的UI绘制:允许在Inspector上Add此Component,可以编辑相关属性
- Rigidbody2DComponent类相关属性与场景对应的YAML文件之间的序列化与反序列化
- Scene里利用
b2World更新物理场景,更新完后,更新带Rigidbody2DComponent的GameObject的Transform(感觉这个过程应该在渲染Update之前)
Universally Unique Identifiers (UUID/GUID)
思考一个问题,在进入PlayMode再退出之后,怎么回到原本的场景:
- 最暴力的做法,重新load一下场景文件
资产的GUID不能用path,因为它们的路径是会改变的,而且存字符串性能也不好;也不适合用那种从0开始的,每创建一次就+1的global id,这是因为不同的人可能同时在创建新文件,这样做在资产合并之后会有GUID冲突;所以这里决定用random hash,就跟git commit hash一样,杜绝重名的GUID
比如git commit hash为2b621d3e7eee447057bb974fab80aad4193e5389,这里面有40个16进制的数字,每个数字有4个bit,代表半个字节,一共就是20个字节的hash值,git还有个short hash,也就是这里的前7位2b621d3,一般16^7这么大范围的数字作为hash就足够了,这里的引擎没有那么大的体量,选择使用8个字节来存hash,也就是2 ^ 64 = 16 ^ 16,对应类型为uint64_t
具体步骤为:
- 随机数生成64位的hash,即HashFunction,虽然各个Platform有提供自己的算法,这里还是统一使用std的random库
- 创建UUID类,static涉及到thread safe,但GUID的创建应该只会在main thread里进行,设置static set避免冲突
- 把UUID实装到GameObject(视频里叫Entity)上
std提供的随机数生成算法
只是记录下写法:
#include <random>
#include <iostream>static std::random_device s_RandomDevice;
static std::mt19937_64 s_Engine(s_RandomDevice());
static std::uniform_int_distribution<uint64_t> s_UniformDistribution;int main()
{for (size_t i = 0; i < 10; i++){uint64_t rab = s_UniformDistribution(s_Engine);std::cout << rab << std::endl;}std::cin.get();
}
print为:
16594018988857477878
3025682643124843386
10762836072128041903
...
Playing and Stopping Scenes (and Resetting)
为了在进入和退出Play Mode后,还原场景本身,这里我认为有两种比较实用的做法:
- 区分Editor Scene和Runtime Scene(准确的说是PlayMode Scene),Editor下编辑的是Editor Scene,在点击Play进入Play Mode时,拷贝一份Editor Scene作为Runtime Scene。会有一个Scene的指针代表CurrentActiveScene,PlayMode下指向Runtime Scene,Editor下指向Editor Scene
- 在Editor下编辑Scene时,创建一个Cache,作为保存Scene的文本文件。当点击Play后,开始执行Runtime的逻辑,Stop Scene回到Editor状态下后,再Load一次Cache的Scene文件即可,当Save Scene时,该Cache文件可以直接覆盖原本的Scene文件
第二种方法是我自己想的,感觉写起来比较方便,但是涉及到了频繁的IO,如果场景变复杂了,可能会很卡,所以还是选择第一种做法,也是Cherno的做法,感觉挺复杂的,提供了Scene、Component和GameObject的Copy操作,然后在点击Play时,复制出Runtime用的Scene
注意在复制Scene时,只复制Scene的初始状态(即需要被序列化的部分),因为实际游戏里的Scene可能会非常复杂,里面可能会有很多脚本Spawn出来的对象,所以只记录初始状态,让其自己去Tick,是比较合理的
那么怎么复制一个场景呢?这里的需求应该是:
- 复制的Runtime Scene的数据与Editor Scene完全相同,GameObject的GUID也完全相同
- Runtime Scene下,不管怎么鼓捣,都不会影响Editor下的对象,这意味着两个类的数据成员都是独有的,不共享
目前Scene的数据成员有:
entt::registry m_Registryuint32_t m_ViewportWidth = 0, m_ViewportHeight = 0;b2World* m_PhysicsWorld = nullptr;
要从Editor Scene复制出一个新的Runtime下随便折腾的Scene,还不能影响Editor Scene的内容,相对于要对原本的Scene做一个Deep Copy的操作。所以肯定是不能直接Copy registry和b2World对象的,新的registry会影响Editor Scene,所以这里的Copy Scene的做法跟反序列化一个场景很像,无非反序列化是从文本里读取信息,而这里是从原场景里读取信息。
这样一看思路就比较清晰了:
- 设计
CopyComponent函数 - 设计
CopyGameObject函数,里面会调用各个Component的CopyComponent函数 - 设计
CopyScene函数,里面调用CopyGameObject函数
Copy Component
很久没写这块的代码了,先来回顾下Component相关代码:
// 目前的Component基类,基本就是简单成了这个样子
class Component
{// 记录的是此Component对应的Instance在Scene(register)里的Id, 是ECS系统里的唯一标识// 派生类复制的时候应该走的是CopyCtoruint32_t InstanceId = 0;
};class GameObject
{
public:template<class T, class... Args>T& AddComponent(Args&& ...args){auto& com = m_SceneRegistry.emplace<T>(m_InstanceId, std::forward<Args>(args)...);com.InstanceId = (uint32_t)m_InstanceId;return com;}private:entt::entity m_InstanceId;// entt::entity就是std::uint32_tentt::registry m_SceneRegistry;std::shared_ptr<UUID> m_ID;
}
有了这个就好说了,CopyComponent的时候,任务交给Component类的复制构造函数即可,模板函数如下:
// 用于把src里entity的某种Component复制到dst的entity上
template<typename Component>
static void CopyComponent(entt::registry& dst, entt::registry& src)
{// 获取所有带有Component的entity数组auto view = src.view<Component>();for (auto e : view){// 保证Component对应的Entity()的ID与原来的相同即可auto& component = src.get<Component>(e);dst.emplace_or_replace<Component>(component.InstanceId, component);}
}
Copy Scene
代码如下:
// 大体是new一个scene, 基于原本的UUID, new出每个Entity, 再逐一为Component调用Copy操作
// 为复制得到的Entity添加Component
std::shard_ptr<Scene> Scene::Copy(std::shard_ptr<Scene> other)
{std::shard_ptr<Scene> newScene = CreateRef<Scene>();newScene->m_ViewportWidth = other->m_ViewportWidth;newScene->m_ViewportHeight = other->m_ViewportHeight;auto& srcSceneRegistry = other->m_Registry;auto& dstSceneRegistry = newScene->m_Registry;// 创建一个临时map, 存储新创建的带UUID的Entitystd::unordered_map<UUID, entt::entity> enttMap;// Create entities in new sceneauto idView = srcSceneRegistry.view<IDComponent>();for (auto e : idView){UUID uuid = srcSceneRegistry.get<IDComponent>(e).ID;const auto& name = srcSceneRegistry.get<TagComponent>(e).Tag;Entity newEntity = newScene->CreateEntityWithUUID(uuid, name);enttMap[uuid] = (entt::entity)newEntity;}// Copy components (except IDComponent and TagComponent)CopyComponent<TransformComponent>(dstSceneRegistry, srcSceneRegistry, enttMap);CopyComponent<SpriteRendererComponent>(dstSceneRegistry, srcSceneRegistry, enttMap);CopyComponent<CameraComponent>(dstSceneRegistry, srcSceneRegistry, enttMap);CopyComponent<NativeScriptComponent>(dstSceneRegistry, srcSceneRegistry, enttMap);CopyComponent<Rigidbody2DComponent>(dstSceneRegistry, srcSceneRegistry, enttMap);CopyComponent<BoxCollider2DComponent>(dstSceneRegistry, srcSceneRegistry, enttMap);return newScene;
}
去掉Component之间的继承关系
参考:Iterating through components with common base class or via ducktype
在Copy Scene时遇到了一个操作,我想给所有的Component添加Awake函数(类似于Unity里的Awake和UE里的BeginPlay函数),这个函数只在Play Mode下被调用。目前我的类继承逻辑是这样的:
class Component
{
public:Component() = default;virtual ~Component() = default;virtual void Awake() {}uint32_t InstanceId = 0;
};class CameraComponent : public Component...
class Rigidbody2D : public Component...
class Transform : public Component...
现在我需要在进入PlayMode时,调用所有Component的Awake函数,我是这么写的:
auto& view = m_Registry.view<Component>();
for (auto& entity : view)
{Component* com ref = view.get<Component>(entity);com->Awake();
}
实际代码里,发现返回的view数组为空,这意味着entt的view函数只能返回派生类类型的对象,这么写就不会有问题:
auto& view = m_Registry.view<CameraComponent>();
看了下相关论坛的解释,发现entt是不希望Component之间存在继承关系的,因为这样会有悖ECS的设计理念,它对于Component有两个要求:
- 每个带有数据的Component都应该有单独的final type
- 每个Component里的数据应该存的是value,而不是指针或引用
这样是为了Cache Friendly,每个相同的Component类的Data都放到同一个内存池了,当遍历场景里的同一种Component时,会只在同一片内存区域上操作,Component不存指针和引用也是为了避免内存访问的跳转;同时,这里的虚函数调用也会给CPU造成额外的性能消耗(Another thing your CPU really likes, is predictable code to execute. It tries to predict and prepare upcoming code. It also has some local space for instructions as well),所以理想的entt代码应该是这样的:
Struct TextDrawable {
sf::Text text;
};struct SpriteDrawable {
sf::Sprite sprite;
};//and you simple iterate them separately:
registry.view().each([&renderTarget](const TextDrawable& rDrawable){
renderTarget.draw(rDrawable);
});registry.view().each([&renderTarget](const SpriteDrawable& rDrawable){
renderTarget.draw(rDrawable);
});
看了下Cherno写的,确实没用到继承关系,类声明都写到了一个Component.h里,方便后续遍历
顺便看了下俩常用游戏引擎里的Component设计,发现它们还是存在着继承关系的,比如:
// 虽然UObject里没有任何数据, 都是接口, 但这里的UActorComponent里面是有数据的
class UMovementComponent : public UActorComponent : (public UObject, public IInterface_AssetUserData)
这也正说明了俩引擎是EC架构,不是严格的ECS架构,因为相同的Component的Data不是完全存放到一起去的
暂时还没想好要不要这么改,后面再说吧
Using C# Scripting with the Entity Component System
前两课基本都是搭建基础建设,使得在引擎脚本层的C#和引擎本身的C++之间的api可以相互调用,这节课主要是为了在引擎里的应用,比如这两个操作:
- C++暴露创建GameObject的接口,用户可以从C#里调用它来创建GameObject
- 添加ScriptComponent,在C#里使用WASD键位来实现场景里Quad的移动
我的理解是,要做的方法跟Unity是类似的。添加按钮,点击的时候出现一个TextBox,然后输入,会创建对应的类在项目里,然后C++里会定义去查询C#里的特殊名字的函数,为其调用mono的internal call函数,应该会有一个集合把这些函数都存起来,再在C++引擎特定loop的地方,调用这些函数
Finishing The Pull Request
enum class
enum class有个不太好的地方,它不可以直接参与位运算,需要重载它的相关运算符,而enum可以,其实可以用下面这种写法,用enum模拟enum class:
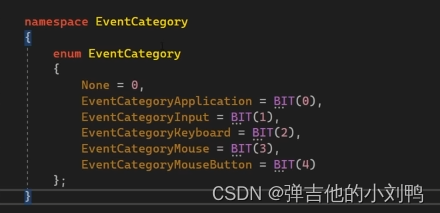
-
Hazel未来想要完全从C#里调用C++的代码,而不是像Unity这样,要一个个接口暴露出来这么麻烦。因为Unity为了闭源,是把C++代码提供成dll的,而Hazel的C#是直接有C++的源码工程的
-
往Transform组件里加Cache数据并不好,一方面是加内存占用,更重要的是一堆Transform数组会在Cache里造成Cache miss,因为带来了很多无效数据
Rendering Circles in a Game Engine
有几种取巧的办法:
- 绘制正多边形近似圆
- 使用圆形贴图模拟,这种情况下其实绘制的是quad
一般游戏里,如果是Debug用的东西,比如Gizmos,那么可以用多边形模拟圆,但是Runtime用的东西,比如角色吃的甜甜圈,还是比较适合直接绘制出真正的圆
这里主要讲的是渲染Circles,其实不需要具体的geometry,可以通过Shader算法来实现,其实挺简单的,就是利用UV坐标做文章,绘制一个圆时,需要知道它的圆心对应的UV坐标,然后再给定一个半径对应的UV坐标长度R即可,那么每次绘制像素时,如果其UV坐标到中心UV坐标的长度小于R,即绘制点,即可
这里可以使用Shader Toy帮助快速看效果,如下图所示,用左下角的(0,0)点为圆心,绘制的圆,裁剪后就剩四分之一部分:

由于UV坐标都在[0,1]区间,但是这里的屏幕长宽比不同,所以要根据ratio调整一下UV坐标,这里把U坐标按比例增大,再改一下圆心坐标为屏幕中心的(0.5, 0.5),即可:
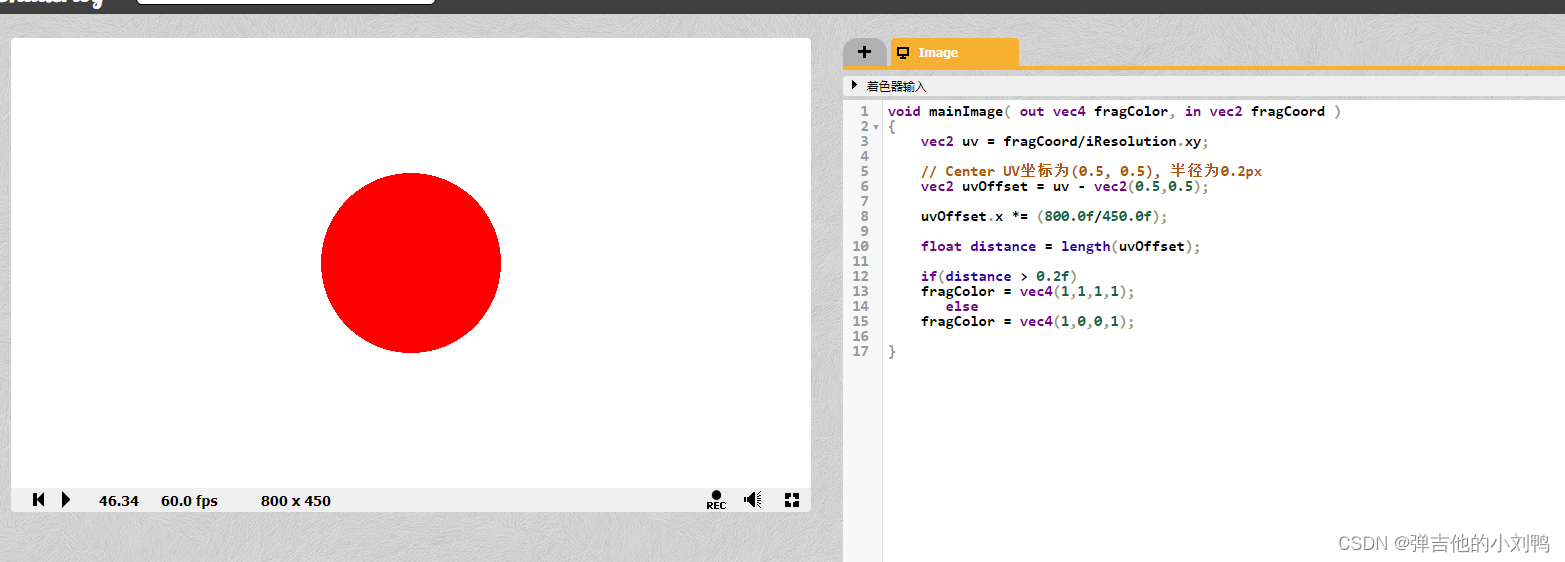
附录
raw pointer转换成smart pointers的问题
参考:Creating shared_ptr from raw pointer
首先回顾一下相关语法,对于raw pointer转换成shared_ptr时,写法为:
classA* raw_ptr = new classA;// 一定要记住, 后续不能再使用raw_ptr// 如果是声明加定义shared_ptr
shared_ptr<classA> my_ptr(raw_ptr);// 这个过程会析构classA么// 如果只是给shared_ptr赋值
my_ptr.reset(raw_ptr);// 这个过程会析构classA么
顺便说一句,这里的三行代码,只有第三行会调用classA的析构函数,因为reset函数会把原本的对象析构,再重新赋值,不过此时的raw_ptr已经被析构了,再去给my_ptr赋值的话,此时的my_ptr里面会存一个野指针,总之,raw pointer转换成shared_ptr不涉及对象的析构过程,但是shared_ptr.reset赋值方法会调用原本存储对象的析构函数
上面的写法其实并不好,这样写更好:
// 避免创建一个指针变量, 让其他代码使用, 这样从根本上避免了raw pointer的问题
shared_ptr<classA> my_ptr(new classA);
raw pointer转换成unique_ptr的情况,也是类似的:
classA* raw_ptr = new classA;
std::unique_ptr<classA> my_ptr(raw_ptr);classA* raw_ptr2 = new classA;
my_ptr.reset(raw_ptr2);
至于weak_ptr,它不能直接通过raw pointer转过来,因为weak_ptr必须基于shared_ptr或其他的weak_ptr,参考Creating weak_ptr<> from raw pointer
Intrusive Reference Counting
参考:invasive vs non-invasive ref-counted pointers in C++
Intrusive reference counters are atomic integers embedded inside data object which tell how many times in the program the object is being used. As soon as the reference counter reaches value 0 , the object is deleted
When counter is stored inside body class, it is called intrusive reference counting and when the counter is stored external to the body class it is known as non-intrusive reference counting.
引用计数写在对象类内的叫做intrusive(或Invasive) reference counting,否则为non intrusive reference counting
关于MSAA(抗锯齿)
跟Cherno上的课没有太大关系,纯粹是因为我看到屏幕里绘制的图形存在锯齿,看上去很不舒服,所以决定开的抗锯齿。
这个过程比较复杂,踩了很多坑,就不多说了,记录下几个重点:
ImGui::Image需要输出Textuer2D类型的id,而不支持Texture2DMultiSample,应该单独写一个framebuffer,专门用于Resolve MSAA的framebuffer输出的MSAA的Texture Attachment和Render Object- OpenGL里同一个framebuffer不可以输出不同类型的Texture Attachment或Render Object,要么都是MSAA,要么都不是MSAA
- 学习使用Render Doc可以很好的排查这些问题
最后的效果差异如下图所示:

解决Z Depth的Bug
参考:Depth testing
参考:Framebuffers
参考:Advanced GLSL
目前遇到了一个以为比较棘手的Bug,渲染的深度测试功能完全失效了,仔细研究了下,发现它是按照物体的渲染顺序来的,即第一个出现在Hierarchy里的永远最后被画,永远不会被其他物体所遮挡。
为了确认我到底是哪里出了问题,我决定先把Depth数据绘制出来,把Shader改成了如下所示:
void main()
{// 原本的不管out_color = texture(u_Texture[v_TexIndex], v_TexCoord * v_TilingFactor) * v_Color;out_InstanceId = v_InstanceId;out_color = vec4(vec3(gl_FragCoord.z,gl_FragCoord.z,gl_FragCoord.z), 1.0);
}
这里的gl_FragCoord是OPENGL在fs里提供的内置变量,其xy值代表片元的屏幕坐标,z值代表绘制的primitive对应片元的深度值(注意并不是Depth buffer里对应位置的深度值),其值所在的区间为[0, +Infinity),由于绘制的时候,z值超过1的都是白色了,所以我拉的比较近,如下图所示:

可以看到,较近的颜色较暗,然而较远的颜色是白的,这说明我的Depth值应该是没问题的
仔细查了下,发现是framebuffer没有添加depth attachment的缘故,因为我是把场景用fbo渲染出一张贴图的,对应的depth attachment也应该加上,MSAA和正常的fbo绘制写法稍有不同,如下所示:
// 正常FBO的写法
// create a renderbuffer object for depth and stencil attachment (we won't be sampling these)
unsigned int rbo;
glGenRenderbuffers(1, &rbo);
glBindRenderbuffer(GL_RENDERBUFFER, rbo);
glRenderbufferStorage(GL_RENDERBUFFER, GL_DEPTH24_STENCIL8, spec.width, spec.height); // use a single renderbuffer object for both a depth AND stencil buffer.
glFramebufferRenderbuffer(GL_FRAMEBUFFER, GL_DEPTH_STENCIL_ATTACHMENT, GL_RENDERBUFFER, rbo); // now actually attach it
m_RboAttachmentIndices.push_back(rbo);// MSAA的FBO的写法
unsigned int rbo;
glGenRenderbuffers(1, &rbo);
glBindRenderbuffer(GL_RENDERBUFFER, rbo);
glRenderbufferStorageMultisample(GL_RENDERBUFFER, 4, GL_DEPTH24_STENCIL8, spec.width, spec.height); // use a single renderbuffer object for both a depth AND stencil buffer.
glFramebufferRenderbuffer(GL_FRAMEBUFFER, GL_DEPTH_STENCIL_ATTACHMENT, GL_RENDERBUFFER, rbo); // now actually attach it
关于ImDrawList::AddCallback()
AddCallback() just registers a function and parameter that your imgui renderer loop will call. The order within a same window/drawlist are preserved, so if you add 1000 triangles and then add a callback, then 1000 triangles again, your renderer will see them in that order.
AddCallback其实就是传入一个DrawCall的function指针,随后ImGui会在对应的位置调用此函数,
When should I set GL_TEXTURE_MIN_FILTER and GL_TEXTURE_MAG_FILTER?
参考:https://learnopengl.com/Getting-started/Textures
这里回顾一下贴图在OpenGL里的参数设置,原本绘制的Viewport贴图的代码为:
{...GLuint textureId;glGenTextures(1, &textureId);glBindTexture(GL_TEXTURE_2D, textureId);// R32I应该是代表32位interger, 意思是这32位都只存一个integerglTexImage2D(GL_TEXTURE_2D, 0, GL_R32I, spec.width, spec.height, 0, GL_RED_INTEGER, GL_UNSIGNED_BYTE, NULL);glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_NEAREST);glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_NEAREST);// 下面这两行代码是必须的, 否则会黑屏glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR);glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR);
}
前面两行比较简单,属于Texture Wrapping,是当UV坐标超过[0, 1]范围时,应该如何Mapping UV坐标的问题,可以用Map,也可以用Clamp。但是这里的GL_TEXTURE_MIN_FILTER和GL_TEXTURE_MAG_FILTER就不太理解了,看了下文档,这两行属于Texture Filtering,处理的是当输入贴图大小与输出的贴图大小不匹配时的选项,这里分为好几种情况:
- 输入贴图的长和宽均大于输出贴图的长和宽
- 输入贴图的长和宽均小于输出贴图的长和宽
- 输入贴图和输出贴图各有一个尺寸更长(不太清楚这种情况下的计算)
这里的逻辑是,这里会根据屏幕上要绘制的像素点的中心坐标,得到相对于屏幕的XY值(在[0, 1]区间),即为采样贴图的UV坐标,由于贴图上也是一个个的Texel,所以采样的时候可以直接选择Texel点(GL_LINEAR),或者根据周围的四个Texel点进行双线性插值一下(GL_NEAREST),如下图所示:

至于这里的GL_TEXTURE_MIN_FILTER和GL_TEXTURE_MAG_FILTER,其实是把这种GL_LINEAR和GL_NEAREST的使用情况更细分一下而已:
GL_TEXTURE_MIN_FILTER意味着输入贴图尺寸大于输出的贴图尺寸,这意味着贴图变小GL_TEXTURE_MAX_FILTER意味着输入贴图尺寸小于输出的贴图尺寸,这意味着贴图变大
有比较好的思路是在贴图变大时使用线性效果,而贴图变小时使用插值效果:
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_NEAREST);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR);
回到这个问题本身,为啥没有设置这两行会黑屏,我猜是因为framebuffer的贴图尺寸会改变,必须设置这个的原因吧,查了下,这两行对于任何Texture2D贴图来说,应该都是必要的(Texture Wraping不是必要的):
For standard OpenGL textures, the filtering state is part of the texture, and must be defined when the texture is created.
这里还有个问题,就是MultiSample Texture如何设置Texture Wraping和Filtering?参考:Creating Multisample Texture Correctly
得到的结论是,由于MultiSample Texture就是带了多个Sampler的Texture,比如它会对一个Texel的四个角进行采样,然后融合,所以它本身就是GL_NEAREST类型的参数,相当于:
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_NEAREST);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_NEAREST);
由于所有的MultiSample Texture都是这么设置的,所以OpenGL就直接省略让人设置的环节了,如果像下面这么写:
glGenTextures(1,&_texture_id);
glBindTexture(GL_TEXTURE_2D_MULTISAMPLE,_texture_id);
glTexParameterf(GL_TEXTURE_2D_MULTISAMPLE,GL_TEXTURE_MIN_FILTER,GL_NEAREST);
glTexParameterf(GL_TEXTURE_2D_MULTISAMPLE,GL_TEXTURE_MAG_FILTER,GL_NEAREST);
glTexImage2DMultisample(...);
应该会报错:
GL_INVALID_ENUM error generated. multisample texture targets doesn’t support sampler state
glDrawBuffers函数复习
之前代码里调用过这个函数,现在给忘了咋用了,这里复习一下,代码如下:
OpenGLFramebuffer::OpenGLFramebuffer(const FramebufferSpecification& spec) : Framebuffer(spec.width, spec.height)
{glGenFramebuffers(1, &m_FramebufferId);glBindFramebuffer(GL_FRAMEBUFFER, m_FramebufferId);// 创建俩Color Attachment ...HAZEL_CORE_ASSERT((bool)(glCheckFramebufferStatus(GL_FRAMEBUFFER) == GL_FRAMEBUFFER_COMPLETE), "Framebuffer incomplete");// 目前每个Camera只output两张贴图, 第一张代表Viewport里的贴图, 第二张代表InstanceID贴图const GLenum buffers[]{ GL_COLOR_ATTACHMENT0, GL_COLOR_ATTACHMENT1 };glDrawBuffers(2, buffers);
}
问题是:
- glDrawBuffers是不是DrawCall,如果是的话,为啥会在fbo的ctor里调用,而不是在loop里被调用?
- glDrawBuffers的用法
参考:https://www.reddit.com/r/opengl/comments/11sz3yf/does_gldrawbuffer_permanently_alter_the_bound/
参考:https://stackoverflow.com/questions/51030120/concept-what-is-the-use-of-gldrawbuffer-and-gldrawbuffers
glDrawBuffers specifies a list of color buffers to be drawn into.
看了下,这个函数应该不是DrawCall,只是负责开启和关闭FBO上的Color Attachment而已,开启后可供shader写入
glDrawElementsBaseVertex报Access violation reading location错
glDrawElementsBaseVertex与glDrawElements差不多,可以先回顾下glDrawElements函数:
// 函数签名
// indices: Specifies a byte offset (cast to a pointer type) into the buffer bound to GL_ELEMENT_ARRAY_BUFFER to start reading indices from.
void glDrawElements(GLenum mode, GLsizei count, GLenum type, const void * indices);glClearColor(0.1f, 0.1f, 0.1f, 1);
glClear(GL_COLOR_BUFFER_BIT);
// DrawCall调用, 在调用此函数前, 需要绑定Index Buffer
glDrawElements(GL_TRIANGLES, m_QuadVertexArray->GetIndexBuffer()->GetCount(), GL_UNSIGNED_INT, nullptr);
glDrawElementsBaseVertex的签名如下,相较于glDrawElements,只多了一个int参数:
void glDrawElementsBaseVertex(GLenum mode, GLsizei count, GLenum type, void *indices, GLint basevertex);
这里都需要传入的指针,是代表的indices数组里的指针,比如说我有六个顶点,和一个顶点数组:
float positions[] =
{-0.5f, -1.0f, 0.0f,-1.5f, 1.0f, 0.0f,-2.5f, -1.0f, 0.0f,2.5f, -1.0f, 0.0f,1.5f, 1.0f, 0.0f,0.5f, -1.0f, 0.0f
};uint8 indices[] =
{0, 1, 2,3, 4, 5
};
通过传入合适的指针,可以只绘制部分顶点,比如:
// 直接绘制第二个三角形
glDrawElements(/* mode = */ GL_TRIANGLES,/* count = */ 3,/* type = */ GL_UNSIGNED_BYTE,/* offset = */ (void*)( sizeof( uint8 ) * 3 ) );
PDB文件
参考:https://learn.microsoft.com/en-us/visualstudio/debugger/specify-symbol-dot-pdb-and-source-files-in-the-visual-studio-debugger?view=vs-2022
PDB,全程program database,文件后缀为.pdb,也叫symbol files,它负责处理下面二者之间的映射:
- 源代码里的identifier或statement
- 编译后的APP里的identifiers或instruction
正是因为此特性,有了PDB文件的存在,才能把debugger和源码link到一起,从而实现基于代码的调试
查看lib里的object文件依赖的pdb路径
参考:https://stackoverflow.com/questions/25843883/how-to-remove-warning-lnk4099-pdb-lib-pdb-was-not-found
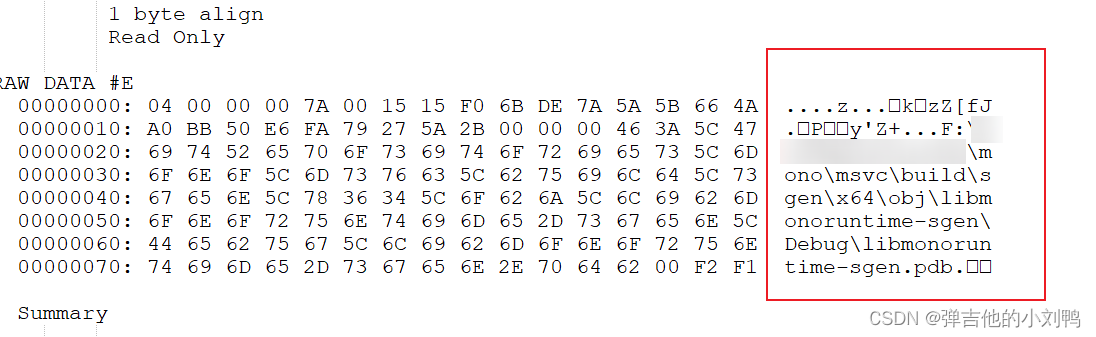
先把lib文件用7Zip解压,然后找到对应的object文件,然后打开VS对应的Developer Command Prompt For VS2022,cd到对应目录,执行以下命令输出到AAA.txt文件即可
C:\dev\scaler\center\agent\thirdparty\libcurl\win\lib>dumpbin /section:.debug$T /rawdata rc2_cbc.obj > AAA.txt
打开AAA文件即可看到里面依赖的PDB文件的路径,如下图所示:
解决所有的Warnings
目前分为以下几种Warning,会仔细分析后面几个复杂点的Warning
- 类型转换提示的loss of data,主要是把uint32_t转成指针类型,在64位机器上会把32位的整型转成64位的整型,会给警告
- 返回对象引用的函数返回了临时变量,比如函数
GameObject& Func(){ return GameObject(); } - warning LNK4006
second definition ignored - warning LNK4099: PDB ‘’ was not found with ‘Hazel.lib(sgen-fin-weak-hash.obj)’ or at ‘’; linking object as if no debug info
warning LNK4006
关于Warning LNK4006,详细信息为:
Ws2_32.lib(WS2_32.dll) : warning LNK4006: __NULL_IMPORT_DESCRIPTOR already defined in opengl32.lib(OPENGL32.dll); second definition ignored
Winmm.lib(WINMM.dll) : warning LNK4006: __NULL_IMPORT_DESCRIPTOR already defined in opengl32.lib(OPENGL32.dll); second definition ignored
这里的Ws2_32.lib是系统在C:\Program Files (x86)\Windows Kits下环境自带的文件,基于如何判断lib文件是static lib还是import lib,我用解压软件打开看了一下,里面一堆dll文件,说明它是import lib,比如对应的ws2_32.dll会出现在C:\Windows\System32文件夹下。关于这个警告,我看了下Linker warnings LNK4006 and LNK4221和Stop Warning: __NULL_IMPORT_DESCRIPTOR这两篇文章,得到的结论大概是:
由于我现在的HazelEditor依赖于Hazel项目,前者会build出一个exe(HazelEditor.exe),后者会build出一个静态lib文件(Hazel.lib),HazelEditor.exe只依赖Hazel.lib,而后者又为了支持Mono,依赖了Ws2_32.dll和Winmm.dll这些系统的库。重点就在于,我这个static lib的Hazel项目是不应该依赖一个dll的,这样当我最终build出exe时,会有两份相同的Ws2_32.dll,一份来自于依赖的Hazel.lib(应该是静态lib会拷贝所有内容的缘故),另一份来自HazelEditor.exe,这样就会重复了(也可能是Hazel.lib里多个静态lib都依赖于这个Ws2_32.dll的缘故)。
我把Hazel对应Project对这些系统lib的依赖挪到HazelEditor项目就可以了。
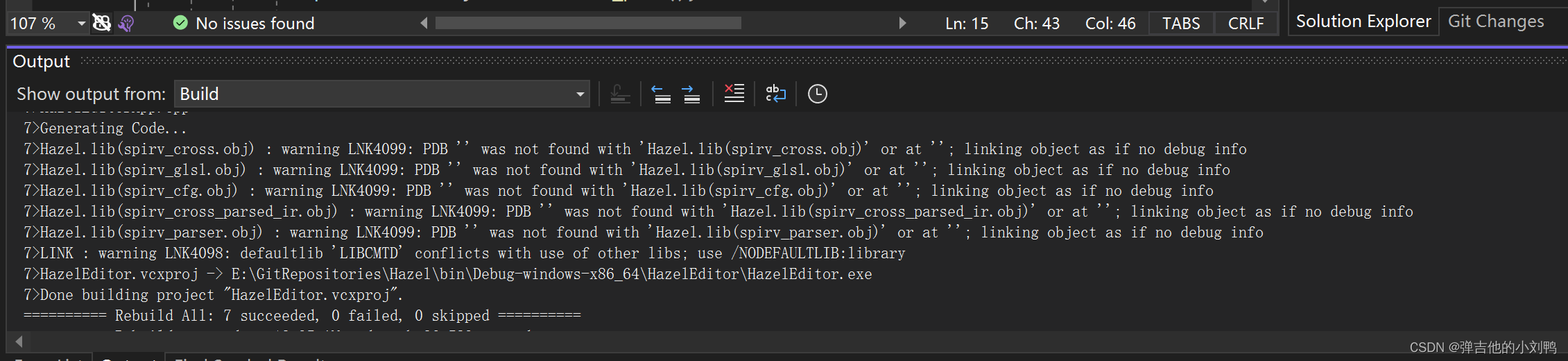
warning LNK4099
提示为:
warning LNK4099: PDB '' was not found with 'Hazel.lib(sgen-fin-weak-hash.obj)' or at ''; linking object as if no debug info
意思是找不到对应的PDB文件,如下图所示
关于PDB(Program database)文件就不多说了,它是在Debug Configuration下build出Binary时会附带的文件,它包含了源码的变量和指令与实际执行的APP里变量和指令的mapping。这里的Hazel.lib作为静态库文件,里面其实包含了一堆object文件,如下图所示,是我用解压文件对它进行操作时的样子:
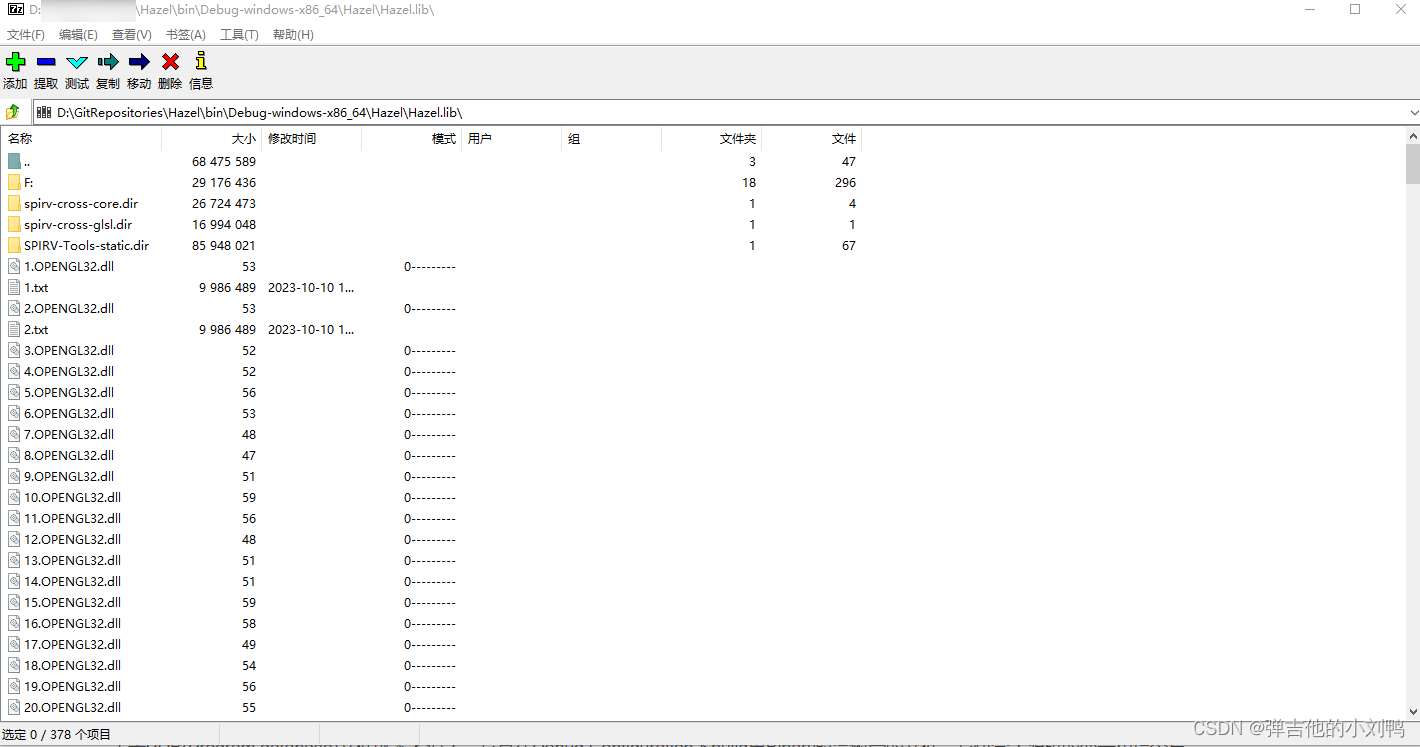
解压后能在对应的文件里看到我很多类编译出的.obj文件,如下图所示:
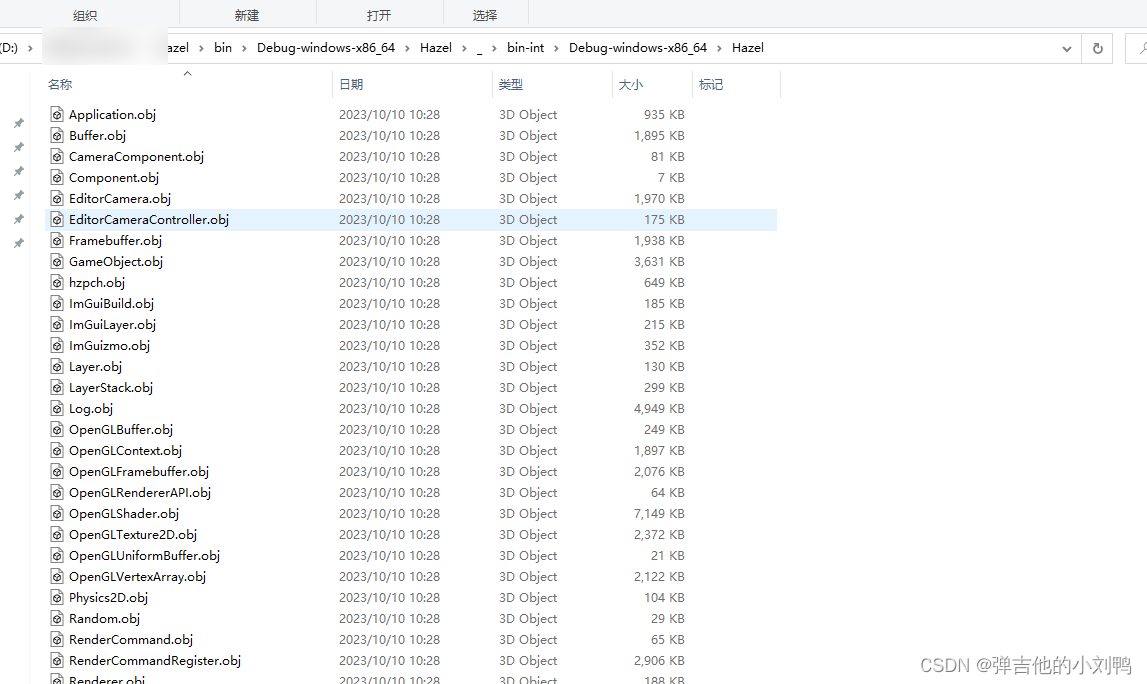
仔细看了了对应lib里报错的object文件依赖的pdb路径,发现本机上确实没有原本build出来的PDB文件了(因为我改动了盘的位置),要解决这个问题,应该不难,做法感觉比较多:
- 要么考虑直接更改object里依赖的PDB路径
- 考虑更新lib库,本机上是OK的
- 把PDB文件也提交上去,然后依赖时使用相对路径,这样每台电脑上都可以
- 写代码禁用此类warning,毕竟也不会去debug这些Mono的库
fatal error LNK1127: library is corrupt
用自己的笔记本电脑打开项目的时候报了这个错:
1>C:\Program Files (x86)\Windows Kits\10\lib\10.0.22000.0\um\x64\opengl32.lib : fatal error LNK1127: library is corrupt
本来是用VS2022打开的项目,但是我笔记本电脑上下载错了版本,导致VS2022专业版试用过期了,所以我换成了VS2017,重新Build出来sln后打开编译,就有这个错了
看了下这个库文件,属于Windows SDK里提供的库文件,在我对应项目的Properties->Librarian->General的Additional Dependencies里设置了对应的依赖:

看了下本机的同名文件路径,发现确实有好几个版本,177开头的应该是VS2017用的SDK,220开头的则是VS2022用的SDK:
发现右键点击对应项目,点击Retarget Projects,降级到VS2017对应的SDK就可以了,之前使用Premake5.exe重新创建sln的过程居然没改SDK的版本,需要这里手动改下
UE与EnTT的关系
参考:Upcoming ECS in UE5 (Mass)
参考:EnTT and Unreal Engine
其实没啥关系,UE本身是EC架构的引擎,跟Unity一样,近些年Unity提出了ECS对应的DOTS系统,旨在把游戏转成ECS架构,UE5也提出了类似的理念,即Mass系统,这个系统目前不知道有没有完全成型,但是在此之前,如果想要在UE的项目里自行实现ECS架构,很多人会选择使用EnTT库
这里介绍下在UE里使用EnTT的方法,截至UE4.25,其C++版本是C++14,但是EnTT最低需要使用C++17的版本,为了在项目里用它,需要手动升级项目里C++的版本,需要在对应项目的Build.cs里加上:
using UnrealBuildTool;public class MyProject : ModuleRules
{public MyProject(ReadOnlyTargetRules Target) : base(Target){PCHUsage = PCHUsageMode.NoSharedPCHs;PrivatePCHHeaderFile = "<PCH filename>.h";CppStandard = CppStandardVersion.Cpp17;PublicDependencyModuleNames.AddRange(new string[] { "Core", "CoreUObject", "Engine", "InputCore" });PrivateDependencyModuleNames.AddRange(new string[] { });}
}
最后再为EnTT创建单独的第三方库Module加进来即可
这篇关于Hazel引擎学习(十二)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









