本文主要是介绍【期末向】“我也曾霸榜各类NLP任务”-bert详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
预训练语言模型
预训练语言模型于 2015 年被首次提出(Dai & Le,2015)。首先我们要了解一下什么是预训练模型,举个例子,假设我们有大量的维基百科数据,那么我们可以用这部分巨大的数据来训练一个泛化能力很强的模型,当我们需要在特定场景使用时,例如做文本相似度计算,那么,只需要简单的修改一些输出层,再用我们自己的数据进行一个增量训练,对权重进行一个轻微的调整。预训练的好处在于在特定场景使用时不需要用大量的语料来进行训练,节约时间效率高效。
也可以简单把预训练模型理解为一个特征提取器,通过对大量无标注数据的训练获得能够表示大部分文字80%特征信息的词向量,然后再根据特定的下游任务用自己的标注数据进行微调。每个预训练模型都有自己的预训练任务,通过预训练任务来提升模型参数提取特征的能力。
而第一个比较出名的预训练语言模式是ELMo,利用双向LSTM模型结合上下文语境信息生成词的embedding。而ELMo的预训练任务是预测下一个词。
Bert
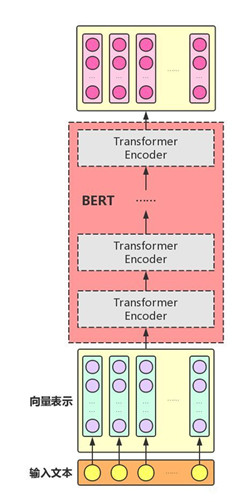
(1)bert的结构
bert是谷歌公司于2018年提出的预训练语言模型,其本身在模型结构上并没有太多创新点,BERT主要用了Transformer的Encoder,而没有用Decoder,因为BERT是一个预训练模型,只要学到其中的语义关系即可,不需要去解码完成具体的任务。
(2)bert的输入数据格式
bert的输入格式由3种嵌入向量拼接而来,分别是标记嵌入、段落嵌入和位置嵌入。标记嵌入就是转换为词向量,在区分句子是开头会加上CLS,每个句子结尾会加上SEP。位置嵌入就是加上位置向量,这2个和transformer的输入没有区别,而所谓的段落嵌入是指,bert输入可能由2个以上的句子组成,那么需要给每个句子训练一个向量,并加在该句子的每个词向量上。具体看下图:

(3)bert的预训练任务
bert采用2种预训练任务,分别是Masked LM掩码语言模型(可以理解为完形填空)和Next Sentence Prediction 下一句预测。
- Masked LM任务
即对于给定的输入序列,我们随机屏蔽15%的单词,然后训练模型去预测这些屏蔽的单词。为了做到这一点,我们的模型以两个方向读入序列然后尝试预测屏蔽的单词。例如对于一句话“I don't like Pairs, and I like Barcelona.” 它会变成:
tokens = [ [CLS], I, don't, like, [MASK], [SEP], and, I, like,Barcelona, [SEP] ]
这里有一个小问题。 以这种方式屏蔽标记会在预训练和微调之间产生差异。即,我们训练BERT通过预测[MASK]标记。训练完之后,我们可以为下游任务微调预训练的BERT模型,比如情感分析任务。但在微调期间,我们的输入不会有任何的[MASK]标记。因此,它会导致 BERT 的预训练方式与微调方式不匹配。
为了解决这个问题,我们应用80-10-10%规则。我们知道我们会随机地屏蔽句子中15%的标记。现在,对于这些15%的标记,我们80%概率用MASK替换,10%用一个随机单词替换,10%不替换保持不变。
而预测MASK则是把最后代表MASK的向量通过softmax,取概率最大的在字典中对应的字。
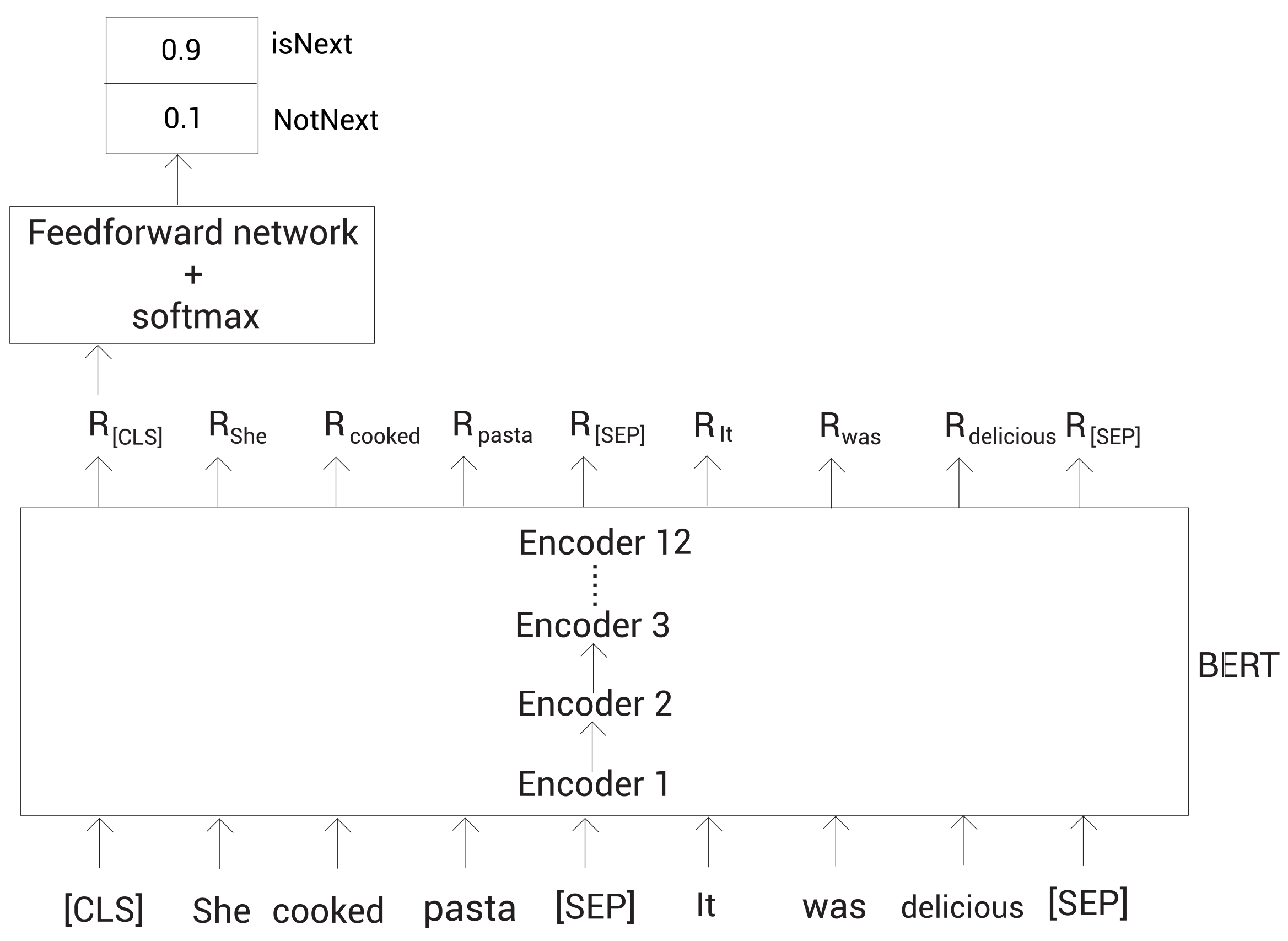
- Next Sentence Prediction
下一句预测(next sentence prediction,NSP)是另一个用于训练BERT模型的任务。NSP属于二分类任务,在此任务中,我们输入两个句子,B有50%的可能是A的下一句,也有50%的可能是来自语料库的随机句子,预测B是不是A的下一句。如果是,则这对句子标记IsNext;如果不是,则标记NotIsNext。然后用聚合了所有句子信息的CLS来预测
这篇关于【期末向】“我也曾霸榜各类NLP任务”-bert详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






