本文主要是介绍有关方差分析的所有,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
不是所有也会慢慢补充
方差分析,又称 F检验。
借助于方差,对数据误差来源进行分析,从而检验多个母体平均数是否相等,也就是判断均值之间是否有差异。
单因素方差分析 (ANOVA):众多因素中只有一个因素的水平有多个,其余因素只有一个水平。
多因素方差分析 (Factorial ANOVA):多个因素有多个水平。
协方差分析 (ANCOVA):以另一个间隔变量为基础对各组之间的差异进行调节或控制的方差分析方法,作为调节或控制的变量成为协变量。
一、要清楚的基本概念
指标:试验结果称为指标,一般表示为数值,用 X 表示。
因素(因子):试验中需要考察的可以控制的条件。用 A, B, C 表示。
水平:因素所处的状态,一般用 A1、A2、A3、… Ar表示。一般将因子控制在几个不同的状态上,每一个状态成为因素的一个水平。
举个栗子,假设我们有一片种植地,经销商向我们推销肥料(因素A),为了比较,我们暂时买了四种不同的肥料(水平 A1 A2 A3 A4),现在我们将地分成完全相同的四块(土壤类型,灌溉条件等全部相同),将四种不同的肥料施上去,看看产量(指标)怎么样。但是即使得到了指标,我们暂时也无法判断,产量的差异到底是由于取样的随机性造成的,还是真的是由于肥料的不同造成的。此时,判断肥料对产量是否有显著影响,就需要用到单因素方差分析。

二、单因素方差分析数学模型的前提假设:
- 影响指标的因子A有s个水平:A1 A2 … AS
- 将每个水平 Aj 下要考察的指标作为一个总体,称为部分总体,仍记为 Aj ,则共有 s 个部分总体。
假设如下:
每个部分总体都服从正态分布,即:
Aj ~ N(μj, σ2j), j=1, 2,…, s
部分总体的方差都相等,即:
σ21= σ22= … σ2s= σ2
不同的部分总体下的样本是相互独立的。
其中 μ1,μ2,… ,μs 和 σ2 都是未知参数。
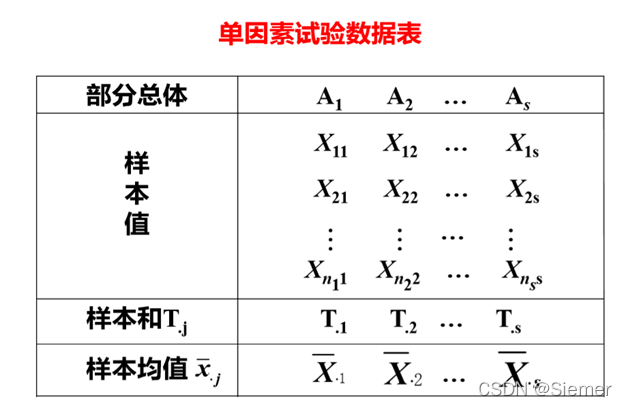
对每个水平 Aj 下的样本 X1j X2j … Xnj,共计 nj 个,引进统计量:
样本和:T·j= ∑ i = 1 n j \sum_{i=1}^{n~j~} ∑i=1n j Xij
样本均值: X ⋅ j ‾ \overline{X_{·j}} X⋅j= 1 n j \frac {1} {n_j} nj1 ∑ i = 1 n j \sum_{i=1}^{n_j} ∑i=1nj= 1 n j \frac {1} {n_j} nj1T·j
样本总均值: X ‾ \overline{X} X= 1 n \frac {1} {n} n1 ∑ j = 1 s \sum_{j=1}^{s} ∑j=1s ∑ i = 1 n j \sum_{i=1}^{n_j} ∑i=1nj= 1 n \frac{1}{n} n1 ∑ j = 1 s \sum_{j=1}^{s} ∑j=1s=nj X ⋅ j ‾ \overline{X_{·j}} X⋅j
记 ε \varepsilon εij=Xij- μ \mu μj,称随机误差,因为 Xij~ N(μj, σ2j),则 ε \varepsilon εij~N(0, σ2)
所以,单因素方差法分析的数学模型如下:
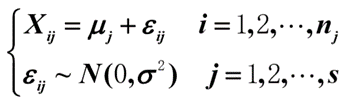
各个随机误差 ** ε \varepsilon εij**相互独立。
三、两类误差概念
Ⅰ随机误差
因素的同一水平下,样本各个观察值之间的差异,对数据形成组内差,可以看成是随机因素的影响。
在方差分析中的表达方式一般是组内平方和(也称残差平方和):
SE = SSE (or RSS) = ∑ j = 1 s \sum_{j=1}^{s} ∑j=1s ∑ i = 1 n j \sum_{i=1}^{n_j} ∑i=1nj(Xij- X ⋅ j ‾ \overline{X_{·j}} X⋅j)2
反映在每个水平下,样本值与样本均值的差异,由随机误差引起。
Ⅱ系统误差
因素的不同水平下,各个观察值之间的差异,对数据形成组间差。可能是由于抽样的随机性造成的,也可能是由所要考察的因素本身造成的。
在方差分析中一般表达方式为组间平方和(也称回归平方和):
SA = SSR (or ESS) = ∑ j = 1 s \sum_{j=1}^{s} ∑j=1s ∑ i = 1 n j \sum_{i=1}^{n_j} ∑i=1nj( X ⋅ j ‾ \overline{X_{·j}} X⋅j - X ‾ \overline{X} X)2
反映在每个水平下,样本均值与样本总体均值的差异,由因子取不同水平引起的。
总偏差和 ST=组内平方和 SE + 组间平方和 SA
四、单因素方差分析的假设检验
H0:μ1 = μ2 = … = μs
H1:μ1,μ2,… ,μs 不全相等
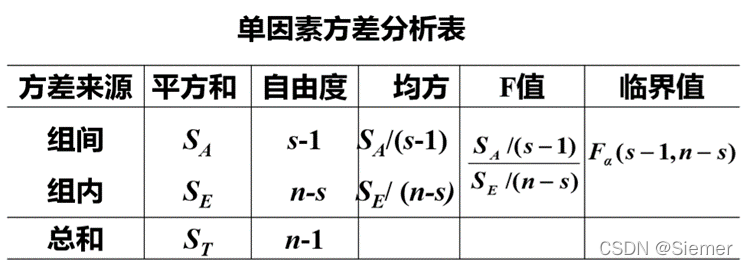
单因素方差分析是将样本总偏差的平方和分解为两个平方和,通过这两个平方和之间的比较,导出假设检验的统计量和拒绝域。
五、两类误差的统计特征
定理:在单因素方差分析的模型下,
- S E σ 2 \frac{S_E}{\sigma^2} σ2SE ∼ \sim ∼ χ \chi χ2(n-s)
- SA 和 SE相互独立
- H0:μ1 = μ2 = … = μs为真时, S A σ 2 \frac{S_A}{\sigma^2} σ2SA ∼ \sim ∼ χ \chi χ2(s-1), S T σ 2 \frac{S_T}{\sigma^2} σ2ST ∼ \sim ∼ χ \chi χ2(n-1)
所以有, F \mathbf{F} F= S A / ( s − 1 ) S E / ( n − s ) \frac{S_A/(s-1)}{S_E/(n-s)} SE/(n−s)SA/(s−1) ∼ \sim ∼ F \mathbf{F} F ( s − 1 , n − s ) \mathbf{(s-1,n-s)} (s−1,n−s)
在计算统计量时,由于各误差平方和的大小与观测值的多少有关,为了消除观测值多少对误差平方和大小的影响,需要将其平均,也就是用各平方和除以它们所对应的自由度,这一结果成为均方(mean square),也成为方差。

好了到这里我们接着第四部分,单因素方差分析的假设检验,原假设和备择假设都已经提出了,检验的统计量取为 F \mathbf{F} F= S A / ( s − 1 ) S E / ( n − s ) \frac{S_A/(s-1)}{S_E/(n-s)} SE/(n−s)SA/(s−1),拒绝域取为 W={ F ≥ Fα (s-1, n-s) }
如果组间差异比组内差异大得多,则说明各个水平间有显著差异,H0不真,拒绝原假设。
上个SPSS做的单因素方差分析结果表做个实例对比展示
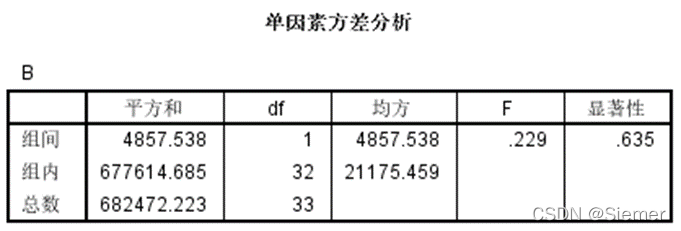
这里,比较P值(显著性)与α(0.05)的大小(从P值的定义,拒绝原假设的最小显著性水平理解):
P < α,拒绝原假设,认为有显著性差异;
P > α,接受原假设,认为没有显著差异。
或者比较 Fα(s-1, n-1)临界值与查表值F的大小,查表值 > 临界值,则落在拒绝域,组间有显著差别。
因为在SPSS里做单因素方差分析时,看起来很简单,但遇到很多问题,如以下:
方差齐性检验:
在方差分析的F检验中,是以各个实验组内总体方差齐性为前提的,因此,按理应该在方差分析之前,要对各个实验组内的总体方差先进行齐性检验。如果各个实验组内总体方差为齐性,而且经过F检验所得多个样本所属总体平均数差异显著,这是才可以将多个样本所属总体平均数的差异归因于各种实验处理的不同所致(注:也就是说组间方差大),如果各个总体方差不齐,那么经过F检验所得多个样本所属总体平均数差异显著的结果,可能有一部分归因于各个实验组内总体方差不同所致。
但是,方差齐性检验也可以在F检验结果为多个样本所属总体平均数差异显著的情况下进行,因为F检验之后,如果多个样本所属总体平均数差异不显著,就不必再进行方差齐性检验。
对控制变量不同水平下观测变量总体方差是否相等进行分析。即分析 σ 1 \sigma_1 σ12 = σ 2 \sigma_2 σ22 = … σ s \sigma_s σs2= σ \sigma σ2 是否成立。

原假设:各水平下观测变量总体方差无显著性差异。
LSD方法(Least Significant Difference):最小显著性差异法。检验敏感性高,即水平间的均值只要存在一定程度的微小差异就可能被检验出来。它利用全部观测变量值,而非仅使用某两组的数据。适用于各总体方差相等的情况,但没有对犯Ⅰ类错误(弃真)的概率问题加以有效控制。
Boonferroni方法:与LSD方法基本相同。不同之处在于对犯Ⅰ类错误(弃真)的概率进行了控制。
Tukey方法:仅使用于各水平下观测值个数相等的条件,要求各总体方差相等。对犯Ⅰ类错误(弃真)的概率问题给予了较为有效的处理。
以上部分有参考:
SPSS方差分析
找不到文件了……
统计学简介之十六——单因素方差分析
这个新浪账号好像没了……
SPSS干货分享:区分T检验与F检验
上面一直在说方差分析,但是统计学知识在应用的时候,有很多平时被我们忽略的前提,上面也有提到,方差分析的前提假设包括:样本正态、方差齐性、各样本独立。
我们先说一下,方差齐性检验,齐,就是“Homogeneity ”,数学层面上就是相等,“不齐”就是“不相等”。
1. 为什么要进行方差齐性检验?
对F检验来说,必须要有一定的前提条件,计算出的统计量才会服从t分布,而t检验正是以t分布作为其理论依据的检验方法。
在方差分析的 F 检验中,是以各个实验组内总体方差齐性为前提的,因此,按理应该在方差分析之前,要对各个实验组内的总体方差先进性齐性检验。如果各个实验组内总体方差为齐性,而且经过 F 检验所得多个样本所属总体平均数差异显著,这时才可以将多个样本所属总体平均数的差异归因于各种实验处理的不同所致;如果各个总体方差不齐,那么经过 F 检验所得多个样本所属总体平均数差异显著的结果,可能有一部分归因于各个实验组内总体方差不同所致。
虽然具体在进行不同统计分析时,对不同的前提假设要求严格性并不一样,但方差齐性这个假设非常重要,特别是自变量各水平的样本量不等时。
2. 进行方差检验的方法:
比较两组或多组样本方差是否相同,检验方法有三种:
- 传统的 Levene 检验,该检验使用各组平均数;
主要用于检验两个或两个以上样本间的方差是否齐性,要求样本为随机样本且相互独立。
国内常见的Bartlett多样本方差齐性检验主要用于正态分布的资料,而且非常灵敏,但对于非正态分布的数据,检验效果不理想。
Levene检验既可以用于正态分布的资料,也可以用于非正态分布的资料或分布不明的资料,其检验效果比较理想。
两者的区别在于,Bartlett检验针是对原始数据检验其方差是否齐性,而Levene检验检验的是组间残差是否齐性,而且一般认为要求残差的方差齐性(也因为只针对残差,所以与分布无关,而针对原始数据的Bartlett检验在应用时,受到数据本身的分布影响较大。)
-
稳健 Brown-Forsythe Levene 类型检验,该检验使用各组的中位数;
-
稳健 Levene 类型检验,该检验使用修剪后的各组中位数
方差齐性检验时假设各组的总体方差相同,如果检验结果,p 值很小(如 p<0.05),拒绝 H0,接受 H1,认为各组总体方差不等(不齐)。
方差趋势检验
当分组变量是有序变量(如文化程度分低、中、高),比较两组或多组样本方差是否随着分组变量变化呈线性变化趋势。
当数据多于两组时,T检验或者相应的非参数分析不再适用,这时需要方差分析。
如果已经知道不同组间的数据存在差异,想找出具体的组间差异,此方法就称为事后检验或多重检验。实际上,如果方差分析不显著,就以为着不同组间没有显著的差异,就不必再进行事后检验。
接下来引入:事后多重检验(post hoc test)
为什么要进行事后检验,而不是直接对不同组的数据两两进行T检验?
举个栗子,以方差分析为例,
假如有5个样本,如果要进行多次均值的两两比较,那么两两比较的次数多达10次。
设每次比较的显著性水平等于0.05,那么10次比较都不犯“弃真”错误的概率为(1-0.05)的十次方,
也就是0.60左右,也就是说犯“弃真”错误的概率高达0.40,这远远大于原先设定的显著性水平0.05。
不仅如此,随着比较组数的增多,犯“弃真”错误的概率也会越来越大。
SPSS提供了多种进行事后检验的办法,恰恰说明到现在,对于事后检验仍然没有统一的解决办法,因此根据不同的目的和数据情况创造出了很多不同的办法。
SNK,student-newman-keuls多重范围检验
LSD,least significance difference最小显著性差异检验
TUKEY,tukey学生化范围检验
SCHEFFE,scheffe多重比较过程
DUNCAN,duncan多重范围检验
-
LSD:是最简单的比较方法之一,是t检验的一个简单变形,并未对检验水准做出任何校正,只是在标准误(注意不是标准差)的计算上充分考虑了所有总体水平的样本信息,估计出了一个更为稳健的标准误。因为单次比较的显著性水平α保持不变,所以LSD法是最灵敏的事后多重比较法。
LSD法侧重于减少Ⅱ类错误(存伪,原假设不正确而接受原假设),但是精度较差,易把不该判断为显著的差异错判为显著。 -
Sidak:Sidak法基于t统计量的成对多重比较检验。校正在LSD法上的应用。通过Sidak校正降低每次两两比较的“弃真”错误概率,以使最终整个比较的“弃真”错误概率保持为显著性水平α,也就是说Sidak调整多重比较的显著性水平,每次比较的显著性水平α会随着比较次数的增多而减小。显然(这个我也不理解显然在哪里)Sidak法比LSD法的灵敏度低,但是提供了比Bonferroni更严密的边界。每次进行Sidak比较的显著性水平为:
α s i d a k \alpha_{sidak} αsidak= ⊢ 1 − α k \vdash\sqrt[k]{1-\alpha} ⊢k1−α
α 表示事先设定的显著性水平;
α s i d a k \alpha_{sidak} αsidak 表示使用Sidak法进行单次比较的显著性水平;
k 表示进行k次两两比较 -
Bonferroni:与Sidak法类似,它的每一次比较实际上是Bonferroni校正在LSD法上的应用。Bonferroni法修正后每次比较的显著性水平比Sidak小,也就是说Bonferroni法比Sidak法的灵敏度更低。
α B o n f e r r o n i = α / k \alpha_{Bonferroni}=\alpha/k αBonferroni=α/k
α表示事先设定的显著性水平;
k表示进行k次两两比较
Bonferroni提出,设 H0 为真,如果进行 m 次显著性水平为 α 的假设检验时,犯Ⅰ类错误(弃真,原假设正确但是拒绝了原假设)的累积概率α’不超过mα,即有不等式Bonferroni不等式 α’≤mα 成立。所以令各次比较的显著性水平为 α=0.05/m,并规定p≤0.05/m时拒绝H0,基于这样的做法,就可以将Ⅰ类错误的累积概率控制在0.05,这种对检验水平进行修正的方法叫做Bonferroni调整(Bonferroni adjustment)法,简称为Bonferroni法。使用t检验在组均值之间执行成对比较,但通过将每次检验的错误概率设置为实验性质的错误率除以检验总数来控制总体误差率。这样,根据进行多个比较的实情对观察的显著性水平进行调整。换句话来说,Bonferroni法由LSD法修正而来,通过设置每个检验的α水平来控制总体的α水平,但是比较的次数越多,比较的结果越保守。
Bonferroni的用法指征:
3.1 各组的样本数无论是相等还是不等;
3.2 计划好的某两组间或几个组间做两两比较;
3.3 当比较次数不多时,Bonferroni法的效果较好;
3.4 当比较次数较多(例如在10次以上)时,则由于其检验水平选的过低,结论偏于保守,犯Ⅱ类错误的概率增加,即出现较多的假阴性结果;
Bonferroni法比LSD法、Duncan法、SNK法偏于保守,但是比Tukey法、Scheffe法要敏感。‘’ -
Scheffe:(最常用,不需要样本数目相同)为均值的所有可能的成对组合执行并发的联合成对比较。使用 F 取样分布。可用来检查组均值的所有可能的线性组合,而非仅限于成对组合。实质是对多个总体均值间的线性组合是否为0进行假设检验。
Scheffe的应用指征:
4.1 各组样本数相等或不等均可以,但是以各组样本数不等使用较多;
4.2 如果比较的次数明显地大于均数的个数时,Scheffe法的检验功效可能优于Bonferroni法和Sidak法,如均数的个数等于或小于比较的次数,Bonferroni方法较Scheffe法佳。 -
Dunnett法:常用于多个试验组与一个对照组间的比较。因此在指定Dunnett法时,还应当指定对照组。
(这段解释看不懂)
将一组处理与单个控制均值进行比较的成对多重比较 t 检验。 最后一类是缺省的控制类别。另外,您还可以选择第一个类别。双面检验任何水平(除了控制类别外)的因子的均值是否不等于控制类别的均值。<控制检验任何水平的因子的均值是否小于控制类别的均值。>控制检验任何水平的因子的均值是否大于控制类别的均值。
以上五种方法的排列顺序是按照灵敏度从高到低排列的,
LSD法>Sidak法>Bonferroni法>Scheffe法>Dunnett法
-
SNK法:全称为Student-Newman-Keuls法。它实质上是根据预先指定的准则将各组均值分为多个亚组,利用Studentized Range分布来进行假设检验,并根据所要检验的均值个数调整总的“弃真”错误(Ⅰ类错误)概率不超过设定的显著性水平a。即,使用学生化的范围分布在均值之间进行所有成对比较。它还使用步进式过程比较具有相同样本大小的同类子集内的均值对。均值按从高到低排序,首先检验极端差分。
-
Tukey法:全称为Tukey’ s Honestly Significant Difference法。最常用,需要样本数目相同。它也是利用Studentized Range分布来进行各组均数间的比较,与SNK法不同地是,它控制所有比较中最大的“弃真”错误(Ⅰ类错误)概率不超过设定的显著性水平a。
Tukey的应用指征:
7.1 所有各组的样本数相等;
7.2 各组样本均数之间的全面比较;
7.3 可能产生较多的假阴性结论。 -
Duncan:其思路与SNK法相类似,使用与 Student-Newman-Keuls 检验所使用的完全一样的逐步顺序成对比较,但要为检验的集合的错误率设置保护水平,而不是为单个检验的错误率设置保护水平。使用学生化的范围统计量。检验统计量服从的是Duncan’ s Multiple Range分布。
以上8种是常用的事后多重检验方法(各水平样本的方差齐性),剩下的六种方法并不常用,这里就不在介绍。除此之外,在各组样本方差不齐时,SPSS还提供了4种事后多重检验的方法,但从方法的接受程度和结果的稳健性讲,希望大家尽量不要在方差不齐时进行方差分析甚至两两比较,采用变量变换或者非参数检验往往更可靠。
以上整理有参考:
数据分析技术:事后多重比较的方法介绍;了解各种方法的原理才能做到“准确分析”
IBM-SPSS说明文件
这篇关于有关方差分析的所有的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






