本文主要是介绍ZeroMQ(1)——三个基本模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
ZeroMQ(1)——三个基本模型
官方文档
我自己使用zeromq,但是其实对zeromq,并不是很了解,对于zeromq,具体解决什么问题也是不太清楚。项目中将zeromq用作一个消息队列。
引用他人的一段总结:
引用官方的说法: “ZMQ (以下 ZeroMQ 简称 ZMQ)是一个简单好用的传输层,像框架一样的一个socket library,他使得Socket编程更加简单、简洁和性能更高。是一个消息处理队列库,可在多个线程、内核和主机盒之间弹性伸缩。ZMQ 的明确目标是“成为标准网络协议栈的一部分,之后进入 Linux 内核”。现在还未看到它们的成功。但是,它无疑是极具前景的、并且是人们更加需要的“传统”BSD 套接字之上的一层封装。ZMQ 让编写高性能网络应用程序极为简单和有趣。”
近几年有关”Message Queue”的项目层出不穷,知名的就有十几种,这主要是因为后摩尔定律时代,分布式处理逐渐成为主流,业界需要一套标准来解决分布式计算环境中节点之间的消息通信。几年的竞争下来,Apache 基金会旗下的符合 AMQP/1.0标准的 RabbitMQ 已经得到了广泛的认可,成为领先的 MQ 项目。
与 RabbitMQ 相比,ZMQ 并不像是一个传统意义上的消息队列服务器,事实上,它也根本不是一个服务器,它更像是一个底层的网络通讯库,在 Socket API 之上做了一层封装,将网络通讯、进程通讯和线程通讯抽象为统一的 API 接口。
其实zeromq所处理的就是使用网络通信来实现一个消息队列,用于系统,进程,线程之间的通信。其是对于socket的一层封装,类似于ACE。
ZeroMQ的几种基本模型
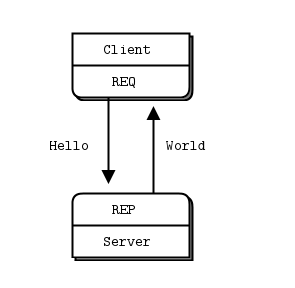
模型一:请求响应模型(Request-Reply)
请求响应模型是一个最基本的服务器/客户端socket通信模型:
服务器端代码:
# Hello World server in Python
# Binds REP socket to tcp://*:5555
# Expects b"Hello" from client, replies with b"World"
#import time
import zmqcontext = zmq.Context()
socket = context.socket(zmq.REP) #创建的socket类型需要定义好,zmq.REP,响应型
socket.bind("tcp://*:5555") #绑定端口,其实也就是bind&listenwhile True:# Wait for next request from clientmessage = socket.recv() #阻塞型的print("Received request: %s" % message)# Do some 'work'time.sleep(1)# Send reply back to clientsocket.send(b"World")
~要理解的是zmq就是对socket进行了一层封装
客户端代码:
#
# Hello World client in Python
# Connects REQ socket to tcp://localhost:5555
# Sends "Hello" to server, expects "World" back
#import zmqcontext = zmq.Context()# Socket to talk to server
print("Connecting to hello world server…")
socket = context.socket(zmq.REQ) #zmq.REQ请求型
socket.connect("tcp://localhost:5555") #这个就是连接端口# Do 10 requests, waiting each time for a response
for request in range(10):print("Sending request %s …" % request)socket.send(b"Hello") #send# Get the reply.message = socket.recv()print("Received reply %s [ %s ]" % (request, message)a) 服务端和客户端无论谁先启动,效果是相同的,这点不同于Socket。
b) 在服务端收到信息以前,程序是阻塞的,会一直等待客户端连接上来。
c) 服务端收到信息以后,会send一个“World”给客户端。值得注意的是一定是client连接上来以后,send消息给Server,然后Server再rev然后响应client,这种一问一答式的。如果Server先send,client先rev是会报错的。
d) ZMQ通信通信单元是消息,他除了知道Bytes的大小,他并不关心的消息格式。因此,你可以使用任何你觉得好用的数据格式。Xml、Protocol Buffers、Thrift、json等等。
e) 虽然可以使用ZMQ实现HTTP协议,但是,这绝不是他所擅长的。
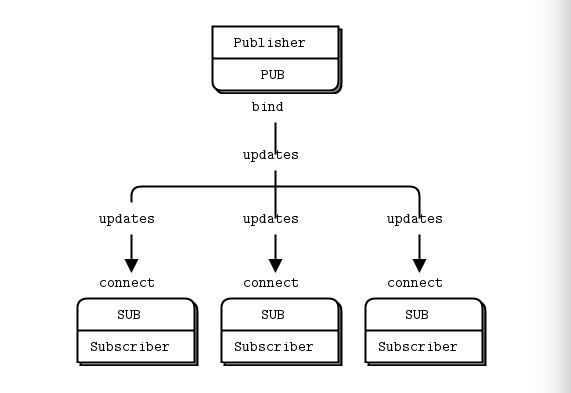
模型二:订阅者模式(Publish-Subscribe)
服务器端:
#
# Weather update server
# Binds PUB socket to tcp://*:5556
# Publishes random weather updates
#import zmq
from random import randrangecontext = zmq.Context()
socket = context.socket(zmq.PUB) #publisher类型
socket.bind("tcp://*:5556")while True:zipcode = randrange(1, 100000)temperature = randrange(-80, 135)relhumidity = randrange(10, 60)socket.send_string("%i %i %i" % (zipcode, temperature, relhumidity))这里可以看出发布者只是绑定了端口,并进行信息发布,其并不care是否有接收者,有哪些接收者。
客户端:
#
# Weather update client
# Connects SUB socket to tcp://localhost:5556
# Collects weather updates and finds avg temp in zipcode
#import sys
import zmq# Socket to talk to server
context = zmq.Context()
socket = context.socket(zmq.SUB)print("Collecting updates from weather server…")
socket.connect("tcp://localhost:5556")# Subscribe to zipcode, default is NYC, 10001
zip_filter = sys.argv[1] if len(sys.argv) > 1 else "10001"# Python 2 - ascii bytes to unicode str
if isinstance(zip_filter, bytes):zip_filter = zip_filter.decode('ascii')
socket.setsockopt_string(zmq.SUBSCRIBE, zip_filter)# Process 5 updates
total_temp = 0
for update_nbr in range(5):string = socket.recv_string()zipcode, temperature, relhumidity = string.split()total_temp += int(temperature)print("Average temperature for zipcode '%s' was %dF" % (zip_filter, total_temp / update_nbr)
)其中有一句代码是乍看之下不太容易理解的:
socket.setsockopt_string(zmq.SUBSCRIBE, zip_filter)官方文档的解释:
Note that when you use a SUB socket you must set a subscription using zmq_setsockopt() and SUBSCRIBE, as in this code. If you don’t set any subscription, you won’t get any messages.
也就是说当使用SUB形式来订阅消息的时候,必须设置一个过滤频道,否则什么也接收不到。而此处使用了,发布者的第一个发布字符串来过滤。这个有规定吗,具体的设置原则是什么?具体请参考:zmq_setsockopt()
另外要说明的两点就是:
1. 服务器端一直不断的广播中,如果中途有 Subscriber 端退出,并不影响他继续的广播,当 Subscriber 再连接上来的时候,收到的就是后来发送的新的信息了。这对比较晚加入的,或者是中途离开的订阅者,必然会丢失掉一部分信息,这是这个模式的一个问题,所谓的 Slow joiner。
注意这个slow joiner问题,之后会为了解决这个问题而设计新的模式。
2.但是,如果 Publisher 中途离开,所有的 Subscriber 会 hold 住,等待 Publisher 再上线的时候,会继续接受信息。
管道模式(Pipeline)
想象一下这样的场景,如果需要统计各个机器的日志,我们需要将统计任务分发到各个节点机器上,最后收集统计结果,做一个汇总。PipeLine 比较适合于这种场景。
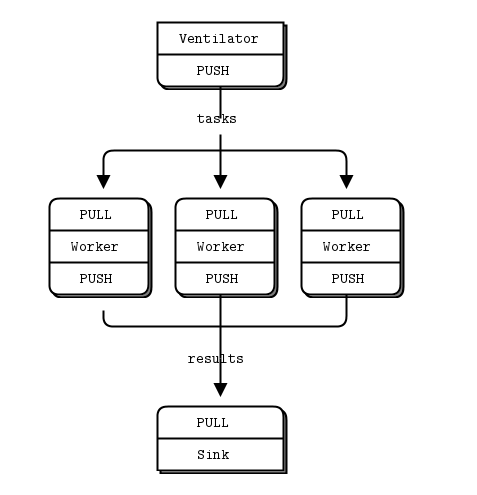
Pipeline的原理就是:有一个Publisher来发布任务,这些任务是可以平行执行的。有一批Worker用于接收任务,Worker处理完任务之后就将结果发送到Sink之中用于归总或进一步处理。
所以要明确的是Pipeline之中并不是服务器,客户端的关系了,而是有三种对象——Ventilator,Worker,Sink
Ventilator代码:
# Task ventilator
# Binds PUSH socket to tcp://localhost:5557
# Sends batch of tasks to workers via that socket
#
# Author: Lev Givon <lev(at)columbia(dot)edu>import zmq
import random
import timetry:raw_input
except NameError:# Python 3raw_input = inputcontext = zmq.Context()# Socket to send messages on
sender = context.socket(zmq.PUSH)
sender.bind("tcp://*:5557")# Socket with direct access to the sink: used to syncronize start of batch
sink = context.socket(zmq.PUSH)
sink.connect("tcp://localhost:5558")print("Press Enter when the workers are ready: ")
_ = raw_input()
print("Sending tasks to workers…")# The first message is "0" and signals start of batch
sink.send(b'0')# Initialize random number generator
random.seed()# Send 100 tasks
total_msec = 0
for task_nbr in range(100):# Random workload from 1 to 100 msecsworkload = random.randint(1, 100)total_msec += workloadsender.send_string(u'%i' % workload)print("Total expected cost: %s msec" % total_msec)# Give 0MQ time to deliver
time.sleep(1)Worker代码:
# Task worker
# Connects PULL socket to tcp://localhost:5557
# Collects workloads from ventilator via that socket
# Connects PUSH socket to tcp://localhost:5558
# Sends results to sink via that socket
#
# Author: Lev Givon <lev(at)columbia(dot)edu>import sys
import time
import zmqcontext = zmq.Context()# Socket to receive messages on
receiver = context.socket(zmq.PULL)
receiver.connect("tcp://localhost:5557")# Socket to send messages to
sender = context.socket(zmq.PUSH)
sender.connect("tcp://localhost:5558")# Process tasks forever
while True:s = receiver.recv()# Simple progress indicator for the viewersys.stdout.write('.')sys.stdout.flush()# Do the worktime.sleep(int(s)*0.001)# Send results to sinksender.send(b'')Sink代码:
# Task sink
# Binds PULL socket to tcp://localhost:5558
# Collects results from workers via that socket
#
# Author: Lev Givon <lev(at)columbia(dot)edu>import sys
import time
import zmqcontext = zmq.Context()# Socket to receive messages on
receiver = context.socket(zmq.PULL)
receiver.bind("tcp://*:5558")# Wait for start of batch
s = receiver.recv()# Start our clock now
tstart = time.time()# Process 100 confirmations
total_msec = 0
for task_nbr in range(100):s = receiver.recv()if task_nbr % 10 == 0:sys.stdout.write(':')else:sys.stdout.write('.')sys.stdout.flush()# Calculate and report duration of batch
tend = time.time()
print("Total elapsed time: %d msec" % ((tend-tstart)*1000))从程序中,我们可以看到,task ventilator 使用的是 SOCKET_PUSH,将任务分发到 Worker 节点上。而 Worker 节点上,使用 SOCKET_PULL 从上游接受任务,并使用 SOCKET_PUSH 将结果汇集到 Slink。
这篇关于ZeroMQ(1)——三个基本模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







