本文主要是介绍C语言算法~BF算法和KMP算法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!


各位CSDN的各位你们好啊,今天小赵要给大家分享一个算法方面的知识这个算法也是小赵琢磨了好久,才算把它理明白,今天小赵就用一篇博客带你理明白这个算法——KMP算法。当然再介绍这个算法前,小赵还会介绍一个BF算法和一个函数,让家人们更好地吸收和理解。
目录
🏀介绍strstr
🎾BF算法
🎾KMP算法是什么及原理
⚾KMP算法比BF强在哪里
⚽KMP算法的实现
⚽NEXT数组的实现
🏆结束语
🏀介绍strstr
在开始今天的两个算法之前,我们先由strstr引入,因为这两个算法与我们strstr对应的功能是十分相似的。

这个是在我们的cplusplus.com这个搜索得到的,(如果家人们有兴趣的话也可以收藏这个网站去学习我们的C语言C++中关键词函数之类的知识。里面有例子和对其的功能解析哦。)其实小赵在这里大致翻译一下就是,在str1中找到我们的str2的内容然后接着打印。比如我们的str1是abcd,str2是bc那么它输出的就是bcd。在这里小赵再用代码帮助大家理解一下。
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#include<string.h>
int main()
{char a[100] = "abcdef";char b[100] = "bcde";char* pch;pch=strstr(a, b);printf(pch);
}相信家人们通过小赵这样的举例一定明白了,对不对,那么我们下面就要进入我们的正餐。
🎾BF算法
其实如果家人们仔细阅读的话,就会发现,这个好像和我们的strstr很像,其实我们这里聊BF的算法的作用就是去实现我们的strstr,看看strstr究竟怎么实现。,怎么样是不是很刺激那我们快快开始把。
🏓BF算法的实现原理
那么BF算法究竟是怎样实现的呢?在这里,小赵先给大家讲讲我们的运行理论。其实也就是小赵带大家玩一个游戏,这个游戏怎么玩呢?大家先看小赵下面这张图。
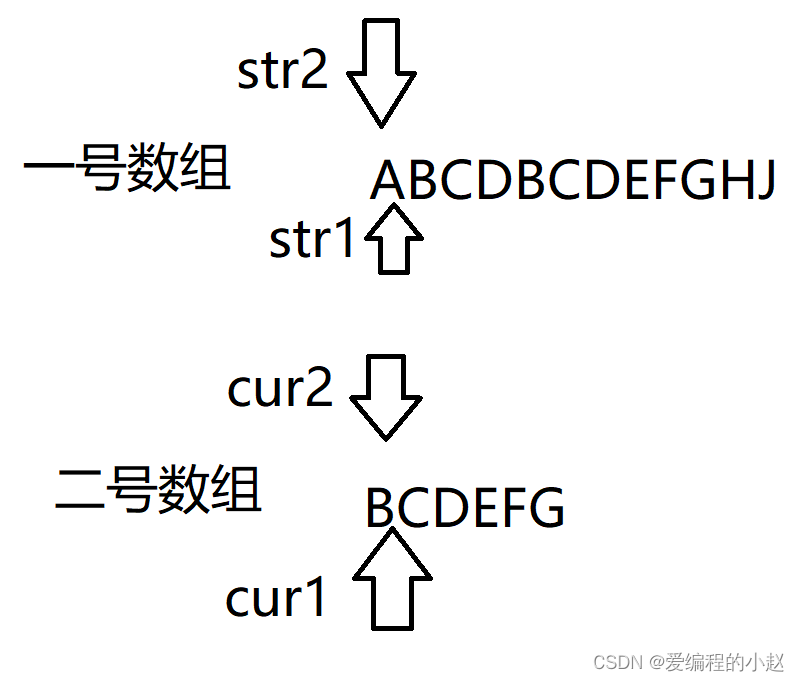
小赵给大家解释一下,一号数组是我们的资源数组,二号数组就是我们要查找的数组,我们的任务就是再一号数组里面找到二号数组。我们能用的东西就是这四个指针。cur2和我们的str2其实就是我们用来匹配的两个箭头,如果它们一样就会向后走,如果二号数组找完了就赢了。如果不一样我们的cur2就不会动,而str2和str1就会都向后移动。那其中最有趣的情况是什么呢?就是小赵下面发的这个图片。
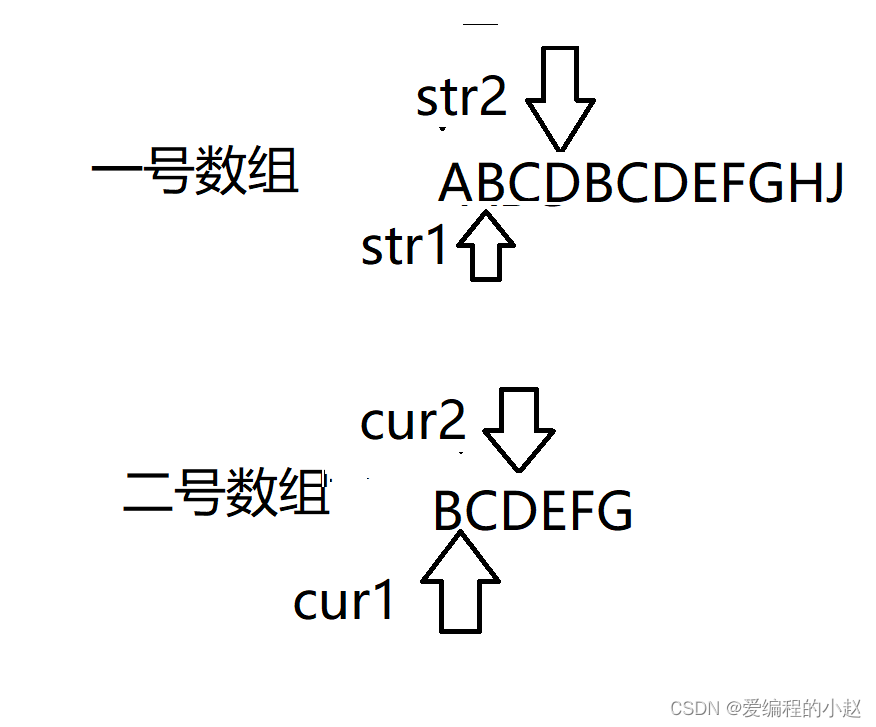
和它的下一步。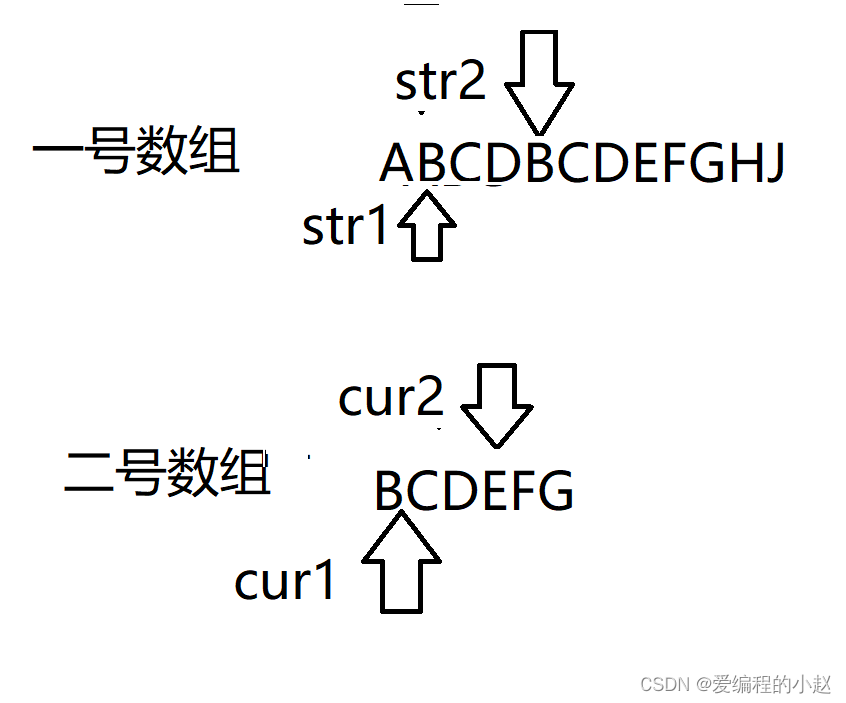
这个时候cur2的目标是肯定,就是立马回去,因为就像找对象一样,找错人了,那不得赶紧回去,那我们的str2,当然也是回家啦,再回到str1的怀抱里,继续向下走。
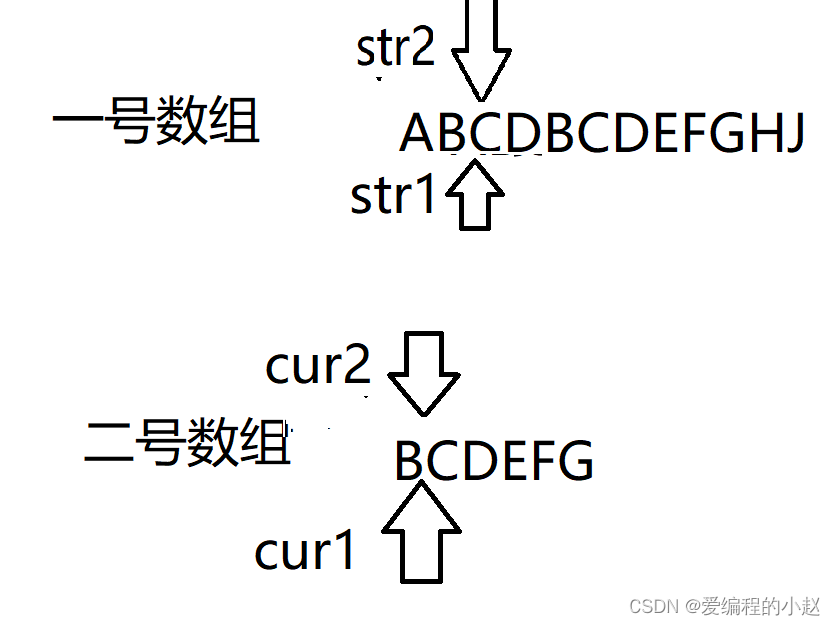
就如同这个图一样。好了游戏玩完了,这个游戏也就是我们BF的基本原理,家人们懂了吗?如果不懂也可以在评论区留言哦,小赵会一一回复的。

🏓BF算法的实现
那么BF算法究竟是怎么实现的,其实也就是上面的四个箭头的事,那究竟什么才能做到上面的四个箭头呢,其实就是指针啦。
char* my_strstr(char* a, char* b)//a为资源数组,b为待查找数组
{char* str = a;char* cur = b;while (*str!='\0'){char* str1 = str;char* cur1 = cur;while (*cur1 == *str1)//如果这两箭头指的字母一样就继续向后移动{cur1++;str1++;}if (*cur1 == '\0')//如果待查找数组遍历完了,那么就输出。{return str;}str++;}}
int main()
{char a[100] = "abcdef";char b[100] = "cde";char* pch;pch= my_strstr(a, b);printf(pch);
}小赵的整个代码的实行其实就是照着小赵上面的那个小游戏来了,如果实在看不懂,可以回头再想想那个游戏哦。

⚾KMP算法比BF强在哪里
那么既然上面的BF算法已经如此完美地还原了我们的strstr,我们又为什么要KMP算法。这样说吧,就像火车到现在已经基本由科技更发达,速度更快的高铁取代了,那么我们也不得不去看看我们的BF算法是否有什么问题,在这里小赵引入一个例子

比如这个例子,如果按照刚才的算法我们的cur2是一定要回到cur1,str2是一定要回到str1的,那么换个角度想如果我们不让他们那样回去,换一个,像小赵这样回去,是否会好一点呢?

我们不让str2回到头,而是让它找到和str2前面一样的几个字母后面,是否是对这个程序的优化呢?可能现在各位看来只是少跑了几步路,但如果这是一个超级长的查找,那么各位是否还觉得这样的简便是少几步呢?可能就是少跑了几十几百步不止,大大加快了程序的整体运行。
🎾KMP算法是什么及原理
其实KMP算法的原理上面已经有提到,就是我们不再让我们的cur2只是简单地回到开头,而是让他有选择的回去。那么这种选择究竟怎么才能实现呢?大家别急,小赵给你们讲讲下面这个待查找究竟什么情况才会回去。
⚾NEXT数组
在这里小赵先给大家看一个待查找数组
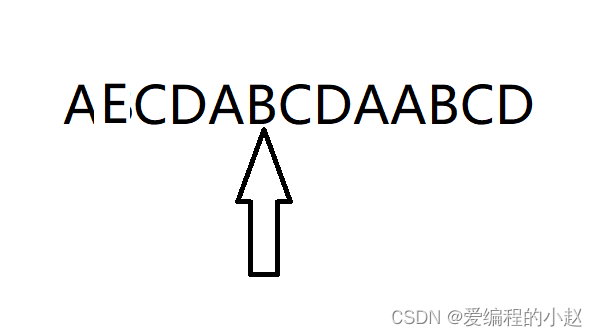
如果我们到了这个B的这个地方,我想问各位,这是不是代表前面的字母是与我们的资源数组此时指向的前面几个保持一致,那么此时资源数组此时前面指向的一定是A,那么我们这个时候要回到哪里呢?那肯定是前面的E位置那这个位置究竟是怎么得来的呢?
其实首先第一点肯定要从开头找吗,资源数组是有你前面的一大串的,如果你从中间找,那肯定难以保证你资源数组指针这个时候指针前面的是否会和你的待找数组是一样的。第二点就是要有一样的东西。归结下来就是我们要找的这个位置就是以我们首元素开头的以我们指针前面那个字母前面一个字母结尾的一个字符串,要求就是要有两个一样(并且这两个字符串一个是从头找,一个是从我们的指针结尾的前面找。的我们才能回去。在这里小赵就带大家用一个例子演示一下

而在我们的这个算法中对这个回去的位置专门设置了一个数组名字,叫NEXT数组。可以说是很神奇的了,但是唯一的不同就是NEXT数组的在0的时候是-1,我们后面会说为-1的好处。
这样一说完其实我们KMP算法的整个原理就算结束了,就是我们指针回去的时候回到它对应的NEXT数组即可。
⚽KMP算法的实现
int KMP(char* str, char* sub, int pos)//str为资源数组,sub为待找数组,pos为开始位置
{void Getnext(char* sub, int* next, int lensub);//声明next数组函数int lenstr = strlen(str);//计算str数组长度int lensub = strlen(sub);//计算sub数组长度if (lenstr == 0 || lensub == 0)//为0,没法找{return -1;}if (pos<0 || pos>=lenstr)//找的开始位置不能小于0,不能比资源数组还长{return -1;}int* next = (int*)malloc(lensub*sizeof(int));//为next数组开辟空间assert(next != NULL);Getnext(sub, next, lensub);//得到我们的next数组int i = pos;int j = 0;while (i < lenstr && j < lensub){if ((j == -1) || str[i] == sub[j])//如果相等继续向后走,如果j=-1,那么要+1{i++;j++;}else{j = next[j];//如果不等于,那么就找到对应的next的数组对应的位置,返回到前面。}}free(next);//释放next数组的空间if (j >= lensub)//如果待查找数组遍历完了,即找到了{return i - j;//返回开始的字母在资源数组中对应的位置}else{return -1;//没找到返回-1}
}⚽NEXT数组的实现
这里来谈一下next数组的实现,其实我们上面已经聊到了我们的目的就是找到以开头字母开始,以指针前面的字母结尾的一个相同的字符串。那么我们这里就可以用两个箭头
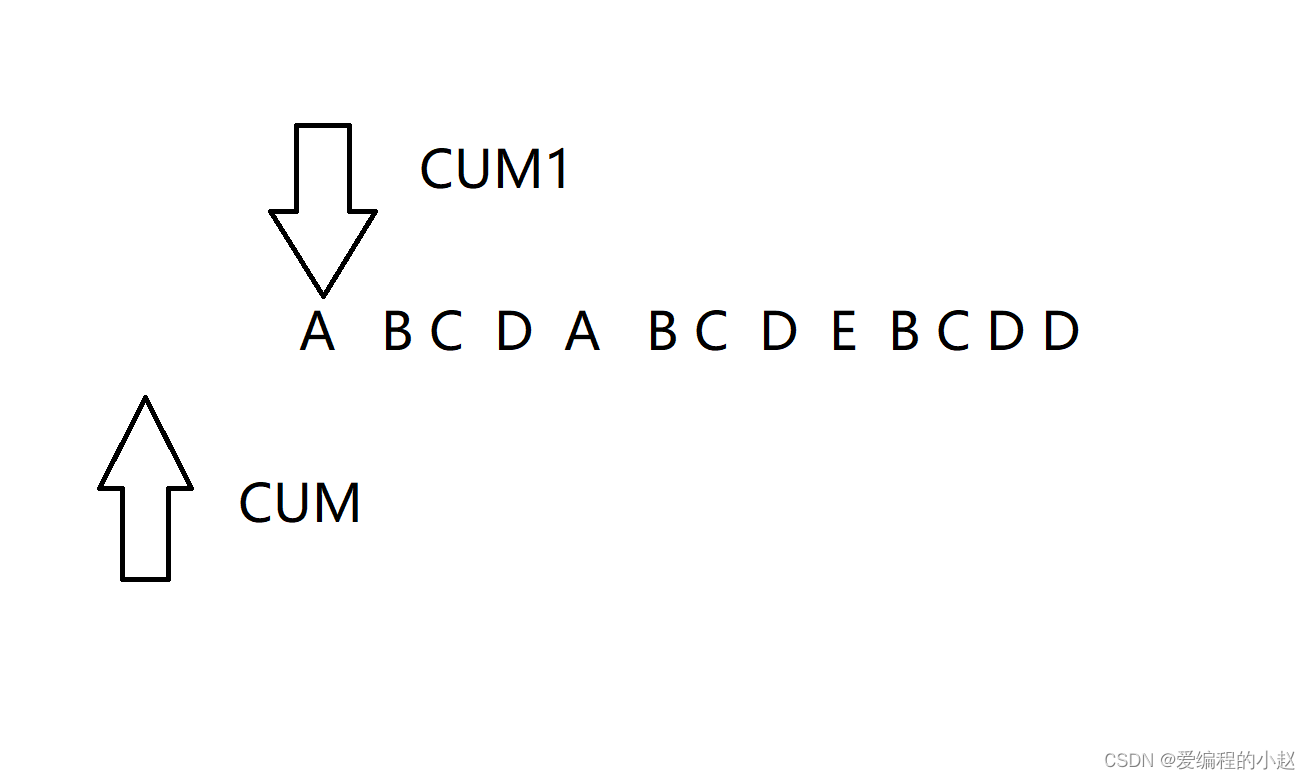
我们可以让我们CUM1先向前走,CUM后走,如果两个不相等,那么我们的CUM就回到我们的A位置,而CUM1继续向后走,直到我cum1前面的字母与你cum指的字母一样我们才一起走,并且这个时候我们CUM1指向字母对应的NEXT数组即可是我们CUM指向的字母的后一个位置,因为两者是几乎等地位。
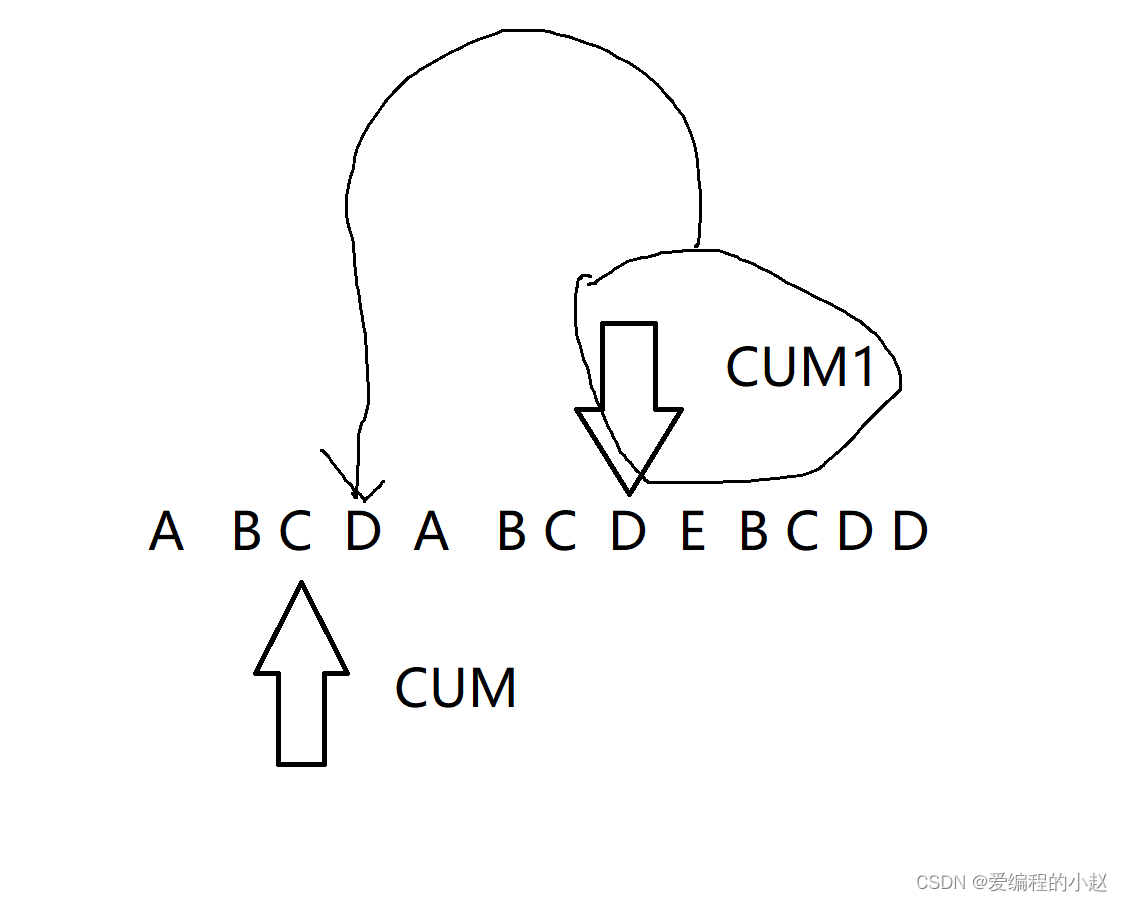
通过小赵上面的描述我们可以明白一件,一为什么next[0]为零,,要让我们的cum1先走,同时也为了我们的代码。其次如果大家仔细看这个原理其实和我们上面的游戏还是蛮像的哈哈。
void Getnext(char* sub, int* next, int lensub)
{next[0] = -1;//定义0位置时候是-1next[1] = 0;//定义1位置时候是0int i = 2;//从2开始找next数组int j = 0;while (i < lensub){if (sub[i - 1] == sub[j] || j == -1)//如果指针指向的前一个字母与前面的指针对应的字母一样{next[i] = j+1;//则这个位置的next为前面那个指针对应的位置加一i++;j++;}else{j = next[j];//如果相等,那么找的指针回到前面自己对应的next数组的位置。}}
}
🏆整个代码
int KMP(char* str, char* sub, int pos)//str为资源数组,sub为待找数组,pos为开始位置
{void Getnext(char* sub, int* next, int lensub);//声明next数组函数int lenstr = strlen(str);//计算str数组长度int lensub = strlen(sub);//计算sub数组长度if (lenstr == 0 || lensub == 0)//为0,没法找{return -1;}if (pos<0 || pos>=lenstr)//找的开始位置不能小于0,不能比资源数组还长{return -1;}int* next = (int*)malloc(lensub*sizeof(int));//为next数组开辟空间assert(next != NULL);Getnext(sub, next, lensub);//得到我们的next数组int i = pos;int j = 0;while (i < lenstr && j < lensub){if ((j == -1) || str[i] == sub[j])//如果相等继续向后走,如果j=-1,那么要+1{i++;j++;}else{j = next[j];//如果不等于,那么就找到对应的next的数组对应的位置,返回到前面。}}free(next);//释放next数组的空间if (j >= lensub)//如果待查找数组遍历完了,即找到了{return i - j;//返回开始的字母在资源数组中对应的位置}else{return -1;//没找到返回-1}
}
void Getnext(char* sub, int* next, int lensub)
{next[0] = -1;//定义0位置时候是-1next[1] = 0;//定义1位置时候是0int i = 2;//从2开始找next数组int j = 0;while (i < lensub){if (sub[i - 1] == sub[j] || j == -1)//如果指针指向的前一个字母与前面的指针对应的字母一样{next[i] = j+1;//则这个位置的next为前面那个指针对应的位置加一i++;j++;}else{j = next[j];//如果相等,那么找的指针回到前面自己对应的next数组的位置。}}
}
int main()
{int c = KMP("abcdefghi", "cde", 0);printf("%d", c);return 0;
}🏆结束语
好了小赵今天的分享就到这里了,如果大家有什么不明白的地方可以在小赵的下方留言哦,同时如果小赵有什么地方说得不对也希望得到大家的指点,谢谢各位家人们的支持。你们的支持是小赵创作的动力,加油。
如果觉得文章对你有帮助的话,还请点赞,关注,收藏支持小赵,如有不足还请指点,小赵及时改正,感谢大家支持!!!

这篇关于C语言算法~BF算法和KMP算法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






