本文主要是介绍JAVA高效率 (秒级) 入库千万级别数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
问题背景:
多个定时任务定期运行,各任务从若干张表中取出数据处理后形成千万级别数据再入库表😖,任务之间有关联关系,任务B依赖任务A产出的表,任务C依赖任务B产出的表....。
任务之间有依赖关系,数据又是千万级别数量,那数据入库速度至少得1s处理几万条数据吧。

想要实现这种飞一般的处理速度,就需要用到JDBC两个对象:PrepareStatement、Statement
简单介绍PreparedStatement 和 Statement 的区别
PreparedStatement在使用时只需要编译一次,就可以运行多次,Statement每运行一次就编译一次,所以PreparedStatement的效率更高
PreparedStatement需要的sql语句为用?(占位符)来替换值,Statement所需要的sql语句为字符串拼接
PreparedStatement解决了sql注入的问题,Statement没有解决,因为PreparedStatement有一个预编译的过程,就算传入占位符的数据中有sql关键字也都被认为是值。Statement所需要的是字符串拼接,传入的整个字符串被默认为sql语句,如果用户手动拼接了字符串,那么会导致语句的改变
从区别中看出,preparedStatement的效率会更高点,就使用它了。
要想使用preparedStatement,我们得自己手搓数据库连接😆😆😆,不能依赖springboot集成mysql。
要想使用preparedStatement,我们得自己手搓数据库连接😆😆😆,不能依赖SpringBoot集成Mysql。(目前这套方法已经在Mysql、ClickHouse数据库上有明显效果,本文着重介绍Mysql使用方法,感兴趣的同学可以尝试其他数据库如何使用。)
编写JDBC数据库连接DBHelper辅助工具类

import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;public class DBHelper {private static final Logger log = LoggerFactory.getLogger(DBHelper.class);private static final String dbUrl = "jdbc:mysql://localhost:3306/animalhome?serverTimezone=UTC&rewriteBatchedStatements=true";private static final String username = "root"; //用户名private static final String password = ""; //密码private static final String driverClassName = "com.mysql.jdbc.Driver"; //连接类型public Connection conn = null; //数据库连接对象public DBHelper() {}/*** 提供功能接口,用于获取连接对象* @return Connection*/public Connection getConnection(){return conn;}//开启数据库连接public void openConnection() {try {Class.forName(driverClassName);//指定连接类型conn = DriverManager.getConnection(dbUrl, username, password);//获取连接conn.setAutoCommit(false);//关闭自动提交} catch (Exception e) {log.error("数据库连接失败,请联系相关人员排查!",e);}}//关闭数据库连接public void closeConnection() {try {this.conn.close();} catch (SQLException e) {log.error("关闭数据库连接失败,请联系相关人员排查!",e);}}
}定义User对象,后续测试类作为处理对象使用。
public class User {private String username;private String password;private String address;public String getUsername() {return username;}public void setUsername(String username) {this.username = username;}public String getPassword() {return password;}public void setPassword(String password) {this.password = password;}public String getAddress() {return address;}public void setAddress(String address) {this.address = address;}@Overridepublic String toString() {return "user{" +"username='" + username + '\'' +", password='" + password + '\'' +", address='" + address + '\'' +'}';}
}关键代码编写
定义数据处理类DataHandler,增加无参构造方法实现开启数据库连接、预编译sql语句返回PreparedStatement实例功能。(注释已在代码中)
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.sql.PreparedStatement;
import java.sql.SQLException;public class DataHandler {private static final Logger log = LoggerFactory.getLogger(DataHandler.class);//自定义数据库连接对象private DBHelper db;private PreparedStatement statement;//prepareStatement的sql语句是使用?(占位符)赋值。private String insertUser = "insert into user (username,password,address) values(?,?,?)";public DataHandler() {//new一个db = new DBHelper();//开启数据库连接db.openConnection();try {//预编译sql语句,返回PreparedStatement实例statement = db.conn.prepareStatement(insertUser);} catch (SQLException e) {e.printStackTrace();}}
}接下来的数据处理中,我们又会用到JDBC批量处理语句的三个方法:
addBatch(String):添加需要批量处理的SQL语句或是参数;
executeBatch():执行批量处理语句;
clearBatch():清空缓存的数据;
setObject():使用给定对象设置指定参数的值。
增加处理对象数据方法,解析添加到批量sql中,达到入库最大批次后批量入库。(注释已在代码中)
//入库总数private long totalLine = 0;//入库数量private int counter = 0;//最大入库数量private int maxBatch =10000;/*** 处理数据:解析添加到批量SQL中,达到入库最大批次后批量入库* @author xiafan* @param user 处理数据* @param count 行标识* @throws Exception*/public void insertUser(User user, long count) throws Exception {try {totalLine++;counter++;if (user != null) {statement.setObject(1, user.getUsername());statement.setObject(2, user.getPassword());statement.setObject(3, user.getAddress());statement.addBatch();//将数据转为一条sql语句// 达到一个批次最大值,入库if (counter == maxBatch) {// 批量处理statement.executeBatch();// 清空缓存数据,结合最大入库数量的判断,做到双重防止内存溢出问题。statement.clearBatch();// 记录读取数量重置为0,重新累加最大入库数量。counter = 0;}}//数据量小于最大批次入库量,且是最后一行则收尾。if (count < maxBatch && count == 1) {statement.executeBatch();statement.clearBatch();//关闭PreparedStatement实例statement.close();//为了防止预编译过程中程序异常,故改为手动提交sqldb.conn.commit();//关闭数据库连接db.closeConnection();log.info(Thread.currentThread().getName() + " parse total line is:" + totalLine);}} catch (Exception e){throw new Exception("预编译插入语句出现问题,请联系运维人员排查!",e);}}最后编写测试类,开始大力出奇迹! 🙏 🙏 🙏
import java.util.ArrayList;
import java.util.List;public class demo {public static void main(String[] args) throws Exception {DataHandler dataHandler = new DataHandler();List<User> list = new ArrayList<>();User usercs = new User();usercs.setUsername("孙悟空");usercs.setPassword("No1");usercs.setAddress("南京市");for (int i = 0; i < 1000000; i++) {list.add(usercs);}long count = list.size();long begin = System.currentTimeMillis();System.out.println("开始时间为:" + begin);for (User user: list) {dataHandler.insertUser(user,count);count--;}long end = System.currentTimeMillis();System.out.println("结束时间为:" + (end-begin) / 1000 + "秒");}
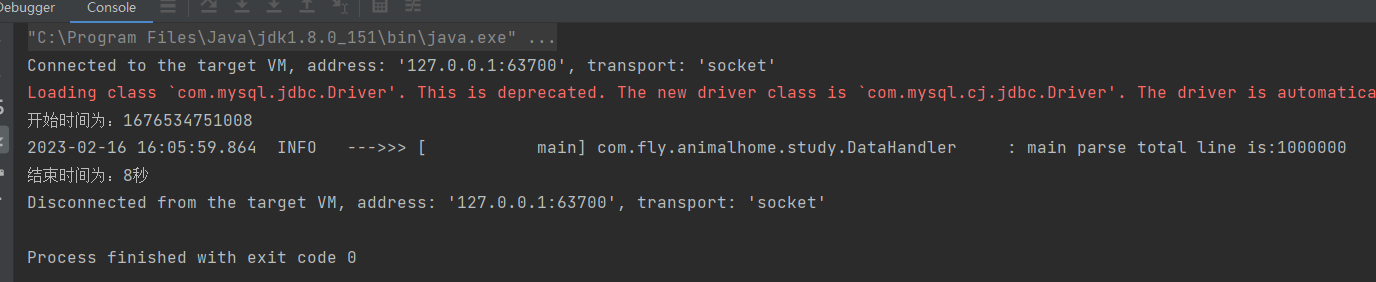
}本机电脑运行结果如下:
数据库如下:
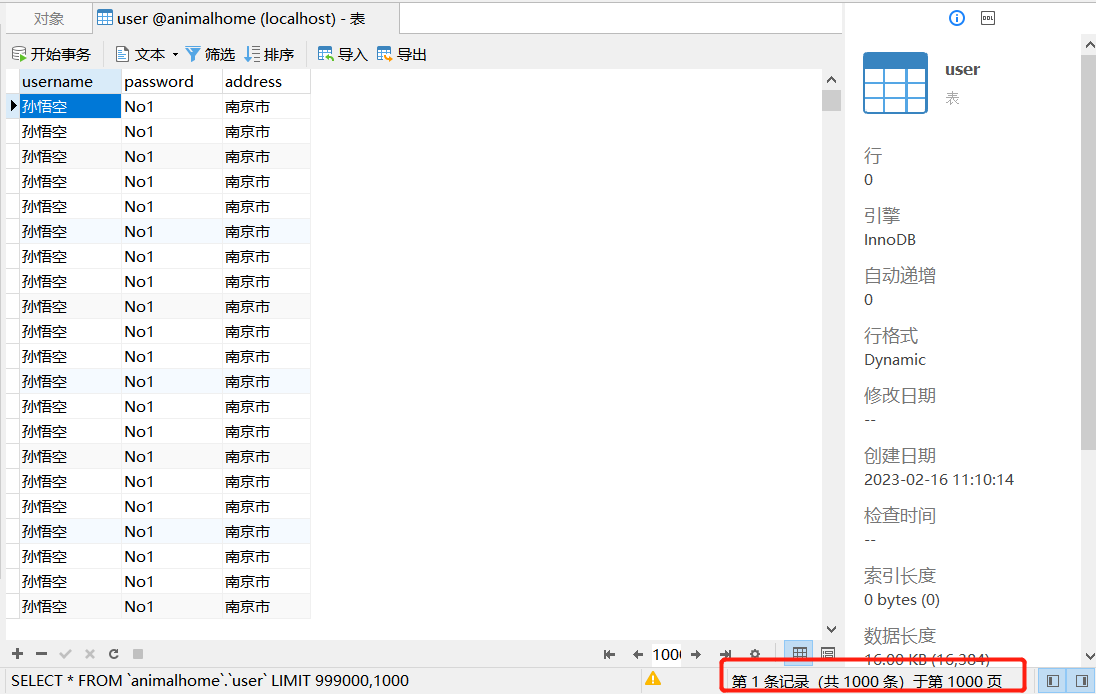
收货满满的成就感!!!

结语:
入库100w条数据仅仅耗时8秒,对于目前我所做需求来说绰绰有余,使用时只需根据不同电脑性能控制每次执行sql要导入的数据量即可,欢迎大家有更好的建议,亦或者更高的效率入库方法可以跟我讨论。
这篇关于JAVA高效率 (秒级) 入库千万级别数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






