本文主要是介绍python自动写文章程序_写第一个Python程序,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Python 2和 Python3的区别
3.0有Unicode support ,这代表着可以直接默认写中文,2是不行的
有一些库改名了,但表面上变化不大,都是些大写变小写,下划线没了之类的
Twisted还不支持Python3(现在应该已经支持了,具体不清楚)
仪式感十足的 Hello World!
Linux下需要指定解释器
#!/use/bin/env python
'''两种写法,推荐第二种方式'''
print "hello,world"
print ("Hello World")
变量
变量就是为了存东西,以备后面的调用。
声明变量
name = "hello world"
'''我们发现,这里是不需要声明数据类型的'''
print ("你好世界",name)
提出一个有点贫的问题:
name = "hello a"
name2 = name
name = "hello a2"
print (name,name2)
hello a2 hello a
'''请问,这里的name2问什么不跟着name变为hello a2'''
答:因为name2指向的是name 的hello a 而不是我们想象的,他指向name
变量的命名规则:
变量名只能是 字母、数字或下划线的任意组合
变量名的第一个字符不能是数字
以下关键字不能声明为变量名(因为已经内置使用了)
['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield']
常量都用全部大写来表示,他其实也能更改,只是全部大写后表示这个变量不应该随意修改!
字符编码
Python解释器在加载 .py 文件中的代码时,会对内容进行编码( 默认ascill )
字符编码可以把机器码装换成易读的内容
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256-1,所以,ASCII码最多只能表示 255 个符号。
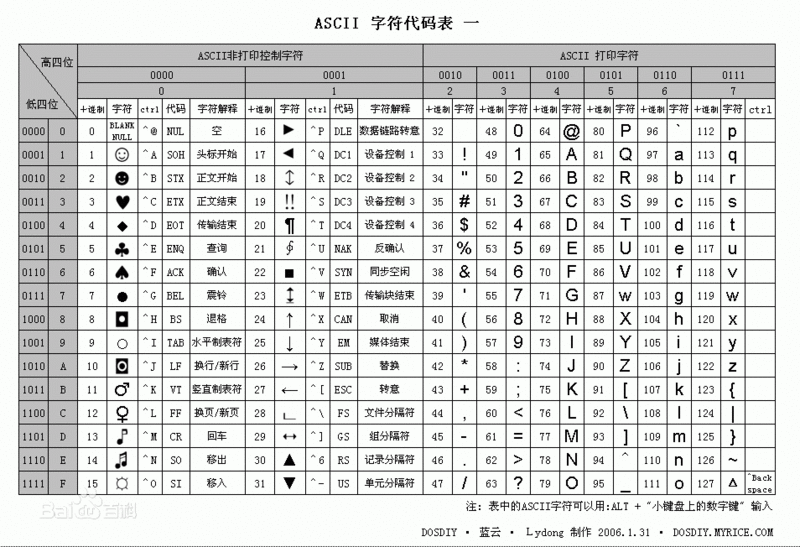
关于中文
为了处理汉字,程序员设计了用于简体中文的GB2312和用于繁体中文的big5。
GB2312(1980年)一共收录了7445个字符,包括6763个汉字和682个其它符号。汉字区的内码范围高字节从B0-F7,低字节从A1-FE,占用的码位是72*94=6768。其中有5个空位是D7FA-D7FE。
GB2312 支持的汉字太少。1995年的汉字扩展规范GBK1.0收录了21886个符号,它分为汉字区和图形符号区。汉字区包括21003个字符。2000年的 GB18030是取代GBK1.0的正式国家标准。该标准收录了27484个汉字,同时还收录了藏文、蒙文、维吾尔文等主要的少数民族文字。现在的PC平台必须支持GB18030,对嵌入式产品暂不作要求。所以手机、MP3一般只支持GB2312。
从ASCII、GB2312、GBK 到GB18030,这些编码方法是向下兼容的,即同一个字符在这些方案中总是有相同的编码,后面的标准支持更多的字符。在这些编码中,英文和中文可以统一地处理。区分中文编码的方法是高字节的最高位不为0。按照程序员的称呼,GB2312、GBK到GB18030都属于双字节字符集 (DBCS)。
有的中文Windows的缺省内码还是GBK,可以通过GB18030升级包升级到GB18030。不过GB18030相对GBK增加的字符,普通人是很难用到的,通常我们还是用GBK指代中文Windows内码。
显然ASCII码无法将世界上的各种文字和符号全部表示,所以,就需要新出一种可以代表所有字符和符号的编码,即:Unicode
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定虽有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536,
注:此处说的的是最少2个字节,可能更多
UTF-8,是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存...
所以,python解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill),如果是如下代码的话:
报错:ascii码无法表示中文
#!/usr/bin/env
print "你好,世界"
改正:应该显示的告诉python解释器,用什么编码来执行源代码,即:
#!/usr/bin/env
# -*- coding: utf-8 -*-
print "你好,世界"
输入
输入并不显示在界面明文显示所输密码
import getpass
username = input("username :")
password = getpass.getpass("password: ")
print(username,password)
这些pycharm中不能用,需要在CMD中实验
字符串的拼接
name = input("name:")
password = input("password: ")
info ='''
———————— info of ''' + name + '''————————
Name : ''' + name +'''
password : '''+ password +'''
'''
print(info)
或者使用简单方式:
name = input("name:")
password = input("password: ")
age = int(input("age: "))
info ='''
———————— info of %s ————————
Name : %s
age : %d
password : %s
''' % (name,name,age,password)
print(info)
print(type(变量名)) :用来打印一个变量的数据类型
Python3里的raw_input和input是一样的
还有一种简单方式02:
name = input("name:")
password = input("password: ")
age = int(input("age: "))
info ='''
———————— info of {_name} ————————
Name : {_name}
age : {_age}
password : {_password}
'''.format(_name=name,_age=age,_password=password)
print(info)
这种方式中_name的下划线只是为了区别外面的变量,没有什么特殊含义
我们来写个登录程序(为了方便测试这里就先使用明文输入密码):
username = "admin"
password = "123123"
_username = input("username : ")
_password = input("password : ")
if username == _username and password == _password:
print("您登录 {name} 用户成功".format(name=_username))
else:
print("您的账户或密码输入错误")
while循环
死循环使用:while True:
结束循环:break
我们写一个猜数字的游戏
initial = 35
opportunity = 0
while opportunity < 3:
digital = int(input('请输入你猜的数字:'))
if digital == initial:
print('恭喜您猜对了!')
break
elif digital > initial:
print('''猜的有点大了
你还有{_opportunity}次机会
'''.format(_opportunity=2-opportunity))
else:
print('''猜的有点小了
你还有{_opportunity}次机会
'''.format(_opportunity=2-opportunity))
opportunity += 1
for循环
range(10)相当与0开始的10个整数
for i in range(10):
print('loop',i)
for循环版的猜大小
initial = 35
for i in range(3):
digital = int(input('请输入你猜的数字:'))
if digital == initial:
print('恭喜您猜对了!')
break
elif digital > initial:
print('''猜的有点大了
你还有{_opportunity}次机会
'''.format(_opportunity=2-i))
else:
print('''猜的有点小了
你还有{_opportunity}次机会
'''.format(_opportunity=2-i))
使用for循环每隔一个打印一次
for i in range(1,10,2):
print('loop',i)
这里的2为步长
在增加一个机会用完后,询问时候重新开始游戏的功能
initial = 35
opportunity = 0
while opportunity < 3:
digital = int(input('请输入你猜的数字:'))
if digital == initial:
print('恭喜您猜对了!')
break
elif digital > initial:
print('''猜的有点大了
你还有{_opportunity}次机会
'''.format(_opportunity=2-opportunity))
else:
print('''猜的有点小了
你还有{_opportunity}次机会
'''.format(_opportunity=2-opportunity))
opportunity += 1
if opportunity == 3:
carry_on = input("您的机会已用完,是否重新开始?")
if carry_on != 'n':
opportunity = 0
如何判断一个用户输入的数值是否为整数?
import random ##调用这个函数
number = random.randint(1,100) ##为number变量赋予一个随机数
if 'number'.isdigit(): ##判断number是否为整数,
number = int(number)
print(number)
这里最好加单引号将变量括起来,因为.isdogot无法对赋值的变量number生效,但会对input赋值的变量生效,为了方便,我们这里一律加单引号括起来。
这篇关于python自动写文章程序_写第一个Python程序的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!