本文主要是介绍【机器学习】MNIST数据集上的python读取和使用操作,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
MNIST手写字符数据集由LeCun大神提出。该数据集在机器学习中就相当于程序中的“Hello World”的存在。由于这个数据集可以很好测试我们的一些分类算法,本博客将对该数据集的读取操作等进行解释
MNIST官网: http://yann.lecun.com/exdb/mnist/
MNIST数据集主要由下面四个ubyte文件组成:

其中train_images_idx3_ubyte.gz和train_labels_idx1_ubyte.gz 两个文件分别为训练集及其标签,含60k张训练图像和标签。
t10k-images_idx3_ubyte.gz和t10_labels_idx1_ubyte.gz则分别表示为测试集图像,含10k张测试图像和标签
读取操作
先来看下idx3_ubyte文件和idx1_ubyte文件的构成:
idx3_ubyte(以训练集为例)
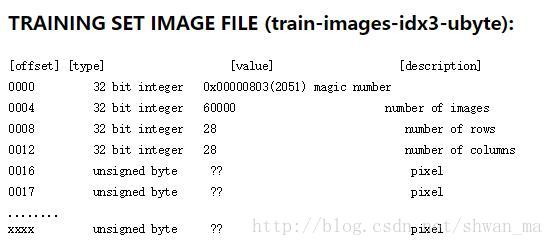
可以看到该文件前4个字节为magic number, number of image, number of rows, number of columns
因此在读取图片时,注意将其跳过。读取时,我们对一个图像一个图像进行,所以要设定一个偏移量offset
代码如下:
def decode_idx3_ubyte(idx3_ubyte_file, saveFlag, status):'''idx3_ubyte_file: source filesaveFlag: bool var (save image or not)status: Train or test (like 'test/') '''with open(idx3_ubyte_file, 'rb') as f:buf = f.read()offset = 0magic, imageNum, rows, cols = struct.unpack_from('>IIII', buf, offset)offset += struct.calcsize('>IIII')images = np.empty((imageNum,rows, cols))image_size = rows * colsfmt = '>' + str(image_size) + 'B'for i in range(imageNum):images[i] = np.array(struct.unpack_from(fmt, buf, offset)).reshape((rows,cols))if saveFlag == True:#保存图像im = Image.fromarray(np.uint8(images[i]))im.save(status + str(i) + '.png')offset += struct.calcsize(fmt)return images
idx1_ubyte(以训练集为例)
其组成结构:

同样,文件头含magic numbe 和 number of items两个综述性标志,读取时记得跳过:
def decode_idx1_ubyte(idx1_ubyte_file):# idx3_ubyte_file: source filewith open(idx1_ubyte_file, 'rb') as f:buf = f.read()offset = 0magic, LabelNum = struct.unpack_from('>II', buf, offset)offset += struct.calcsize('>II')Labels = np.zeros((LabelNum))for i in range(LabelNum):Labels[i] = np.array(struct.unpack_from('>B', buf, offset))offset += struct.calcsize('>B')return Labels由于我们对数据集进行处理时候,经常要对图片进行向量化操作,这里顺便也把代码贴上来:
def MNIST2vector(idx3_ubyte_file):Im = decode_idx3_ubyte(idx3_ubyte_file, None, None)length,row,col = Im.shapereturn Im.reshape((length, row*col))这样MNIST文件就转成了我们熟悉的格式,便很容易进行对我们的分类算法进行验证。
本文主要参考了http://www.jianshu.com/p/84f72791806f
这篇关于【机器学习】MNIST数据集上的python读取和使用操作的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




