本文主要是介绍古诗文网html,古诗文网爬虫,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
0x00 代码
#coding:utf-8
import requests
import re
def parse_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36'
}
response = requests.get(url,headers=headers)
text = response.text
titles = re.findall(r'
#print(title)
dynasties = re.findall(r'
.*?(.*?)',text,re.DOTALL)
#print(dynasty)
authors = re.findall(r'
,*?.*?(.*?)',text)
#print(authors)
content_tags = re.findall(r'
#print((contents))
contents = []
for content in content_tags:
x = re.sub(r'<.>',"",content)
contents.append(x.strip())
#print(contents)
for value in zip(titles,dynasties,authors,contents):#将目标转换成一一对应的数组
title,dynastiy,author,content = value#进行解包
#将下面封装的字典装在列表里
poems = []
#封装在字典里
poem = {
'title':title,
'dynastiy':dynastiy,
'author':author,
'content':content
}
poems.append(poem)
for poem in poems:
print(poem)
print('='*40)
def main():
url = 'https://www.gushiwen.org/default_1.aspx'
for x in range(1,11):
url = "https://www.gushiwen.org/default_%s.aspx" %x
parse_page(url)
if __name__ == "__main__":
main()
0x02 效果
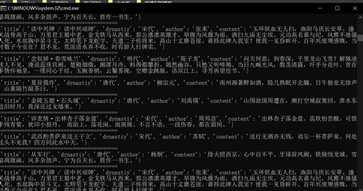
原文:https://www.cnblogs.com/wangtanzhi/p/12416397.html
这篇关于古诗文网html,古诗文网爬虫的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





