本文主要是介绍莫凡keras学习笔记一回归,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前言
- 生成数据集
- 搭建神经网络进行训练
- 画图观察最后结果
前言
特别喜欢莫凡老师,总是在特别短的时间带你入门一门技术。对于我这种希望在短期内入门的孩子来说真是太好了。这里打算记录一波莫凡老师的keras教程的笔记。留作以后回忆。keras是一种封装了底层的神经网络包。让你只需要一行命令就能够添加各种神经网络层如CNN,RNN,LSTM。在这篇笔记中,记录了一个简单的回归模型,先根据一条直线生成200个数据点,然后用一个全连接层来进行训练,将均方误差作为损失函数,最后利用随机梯度下降来对网络进行更新。
生成数据集
根据直线y = 5x + 2这条直线加上一些噪音生成数据集合,并且进行切分
from keras import Sequential
from keras.layers import Dense
import matplotlib.pyplot as plt
import numpy as np
np.random.seed(1)
#为了保证每次试验的结果是一样的,设定随机种子
X = np.linspace(-1, 1, 200)
#生成从-1到1(包括-1和1)均匀分布的200个数
np.random.shuffle(X)
#将其打乱,为了便于之后按照索引划分数据为训练集和测试集,
#防止测试集和训练集是按照大小次序划分的,导致误差
Y = 5 * X + 2 + np.random.normal(0, 0.05, (200, ))
#根据y = 5x + 2这条直线生成加上一些噪音生成Y,
plt.scatter(X, Y)
plt.show()
#绘制散点图
X_train, Y_train = X[:160], Y[:160]
X_test, Y_test = X[160:], Y[160:]
#将数据集合根据索引划分为训练集(前160个点)和测试集(后40个点)
 |
搭建神经网络进行训练
建立一个神经元组成的神经网络,输入维度为1,输出维度为1,损失函数为均方误差,而优化器为随机梯度下降算法。
model = Sequential()
#建立一个神经网络
model.add(Dense(output_dim=1, input_dim=1))
#搭建一个输入和输出维度均为1的全连接层
model.compile(loss='mse', optimizer='sgd')
#设置损失函数为均方误差,优化器为随机梯度下降
print("Training------------")
for step in range(500):cost = model.train_on_batch(X_train, Y_train)if step % 100 == 0:print('cost', cost)
#训练500次,每100次打印一下损失#test
print("\nTesting--------------")
cost = model.evaluate(X_test, Y_test, batch_size=40)
print("test cost", cost)
#获得在测试集上的损失并且打印
W, b = model.layers[0].get_weights()
print('Weights=', W, "\nbiases=", b)
#获得节点的权重和偏差并且打印
最后的输出结果为
Training------------
cost 8.008512
cost 1.0976088
cost 0.26435542
cost 0.06862777
cost 0.019116014
Testing--------------
40/40 [==============================] - 0s 1ms/step
test cost 0.004155935253947973
Weights= [[4.89472]]
biases= [2.002386]
画图观察最后结果
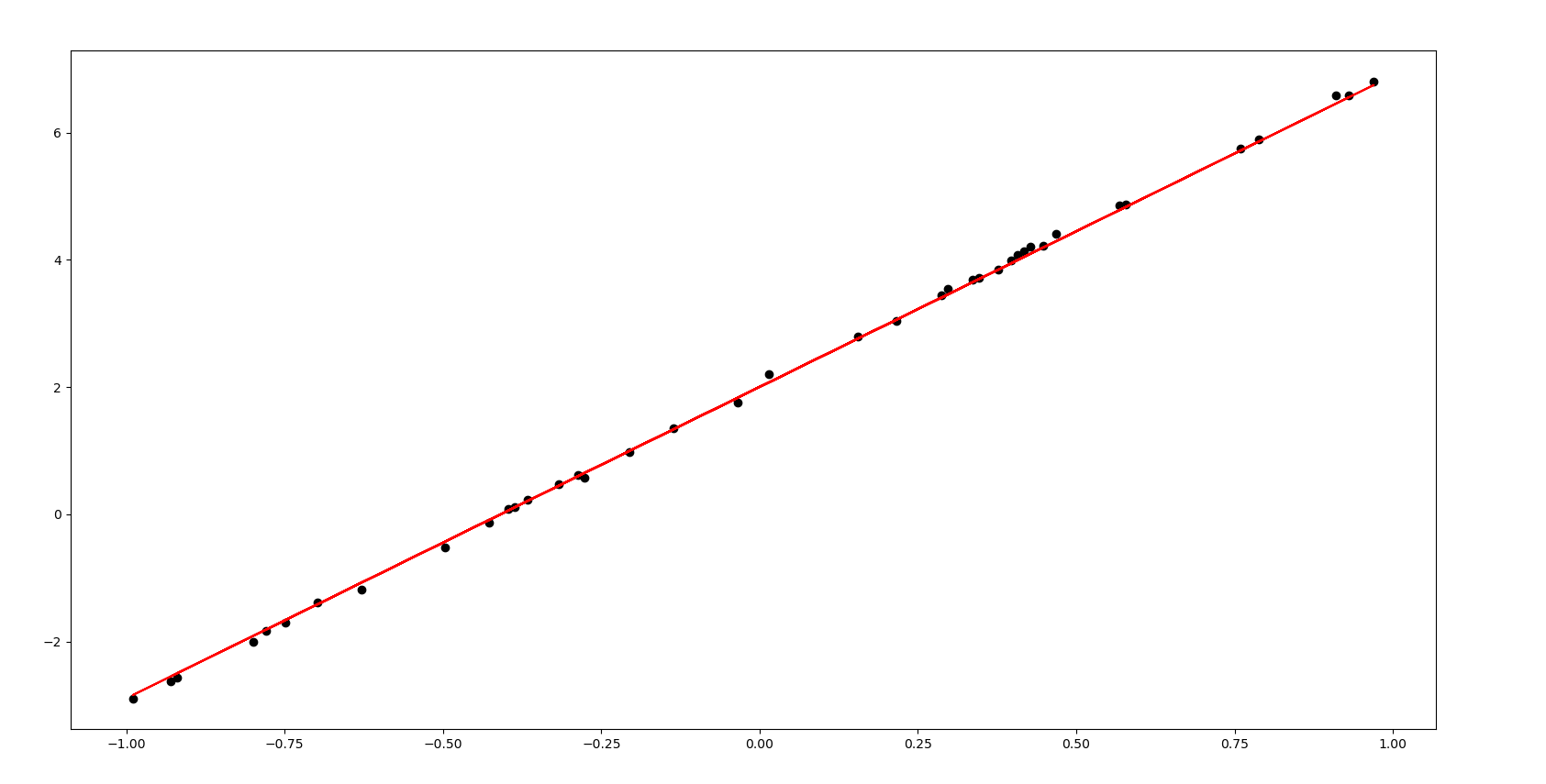
利用模型进行预测,画图观察预测值与实际值的差距
Y_pred = model.predict(X_test)
#利用训练好的模型进行预测
plt.scatter(X_test, Y_test, c='black')
#画出实际数据点的散点图
plt.plot(X_test, Y_pred, c='r')
#画出预测点的直线
plt.show()
 |
这篇关于莫凡keras学习笔记一回归的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









